超详细caffe安装与mnist、cifar-10训练测试教程
Windows下caffe安装详解(cpu +matcaffe+pycaffe)
运行环境VS2013
1、caffe下载:https://github.com/happynear/caffe-windows
或https://github.com/Microsoft/caffe
2、caffe下载后解压到指定文件夹,进入caffe的windows目录(比如,D:\caffe-master\windows),将该目录下的CommonSettings.props.example复制一个并改名为CommonSettings.props,同样还是放在当前目录下。
3、上面两图为原始的CommonSettings.props.example,下面两图为需要修改的CommonSettings.props。
cpu模式的配置:
CommonSettings.props.example


CommonSettings.props


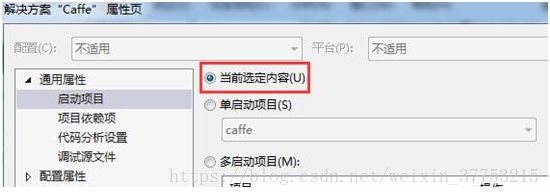
4、点击D:\caffe-master\windows该目录下的Caffe.sln用VS2013打开。这里由于别的模块用到了libcaffe,所以,首先选择libcaffe,右键生成。成功之后,再选择整个解决方案,右键生成解决方案。
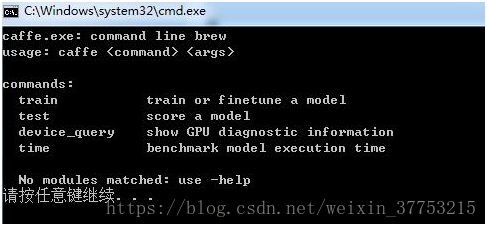
5、点击caffe->caffe.cpp,按F5运行,生成如下界面,证明安装成功。同时在根目录下面会生成相应的exe,lib,dll等文件。
遇到的错误解决方法:
①错误:错误 1 errorC1083: 无法打开包括文件: “pyconfig.h”: No such file or directory(..\..\src\caffe\layer_factory.cpp) D:\NugetPackages\boost.1.59.0.0\lib\native\include\boost\python\detail\wrap_python.hpp 50 1 libcaffe
原因:python路径不对
修改为:

②错误 298 errorC1083: 无法打开包括文件: “gpu/mxGPUArray.h”: No suchfile or directory D:\caffe-master\matlab\+caffe\private\caffe_.cpp 16 1 matcaffe
原因:matlab版本太高,gpu相关的文件路径被改
修改前:

修改后:

③Nuget会提示下载一些东西,包括是boost,opencv2.4.10,gflags,glog,hdf5,lmdb,LevelDB,OpenBLAS,protobuf等预编译的依赖包。过程有点慢,多等会就ok。下载完成后会在caffe的同级目录生成NugetPackages的文件。

④错误 5error MSB4062: 未能从程序集 S:\NugetPackages\OpenCV.2.4.10\build\native\\private\coapp.NuGetNativeMSBuildTasks.dll 加载任务“NuGetPackageOverlay”。未能加载文件或程序集“file:///S:\NugetPackages\OpenCV.2.4.10\build\native\private\coapp.NuGetNativeMSBuildTasks.dll”或它的某一个依赖项。系统找不到指定的文件。 请确认
原因:NugetPackages文件夹里的OpenCV.2.4.10的文件有误
修改:删除NugetPackages文件夹,重新生成libcaffe的解决方案。得到新的NugetPackages文件夹。(只用到CPU的情况)
⑤出现没有生成object文件的错误,双击该错误,点击确定,然后保存即可。
1、mnist测试(利用lenet网络)
Step1:下载mnist数据集,网址:http://yann.lecun.com/exdb/mnist/

数据特点:

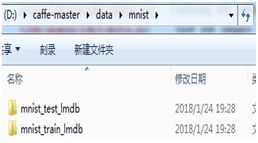
将下载好的数据集解压至caffe-master\data\mnist目录下。
建立如图所示的文件夹


Step2:在caffe根目录下,新建一个create_mnist.bat,里面写入如下的脚本。然后双击该脚本运行,则在.\examples\mnist文件夹下生成lmdb文件。

.\Build\x64\Release\convert_mnist_data.exe.\data\mnist\mnist_train_lmdb\train-images.idx3-ubyte.\data\mnist\mnist_train_lmdb\train-labels.idx1-ubyte.\examples\mnist\mnist_train_lmdb
echo.
.\Build\x64\Release\convert_mnist_data.exe.\data\mnist\mnist_test_lmdb\t10k-images.idx3-ubyte .\data\mnist\mnist_test_lmdb\t10k-labels.idx1-ubyte.\examples\mnist\mnist_test_lmdb
pause
运行结果:


Step3:修改.. \examples\mnist\lenet_solver.prototxt,将最后一行改为solver_mode:CPU,
如下所示,左面为原始的,右面为修改后的。


计算均值文件:在D:\caffe-master\Build\x64\Release目录下新建bat文件mnist_mean.bat,内容如下

compute_image_mean.exeD:\caffe-master\examples\mnist\mnist_train_lmdbD:\caffe-master\examples\mnist\mean.binaryproto
pause
在..\examples\mnist目录下得到mean.binaryproto
修改此文件夹下的训练方法lenet_train_test.prototxt的前两层,就是在原来的基础上把均值文件加进去。(左图为修改前,右图为修改后)


Step4:在caffe根目录下建立文件train_mnist.bat,然后输入如下的脚本,

双击运行,就会开始训练,训练完毕后会得到相应的准确率和损失率。直到出现下面的页面时,说明训练已经完成。(Optimization Done)

Step5:在caffe根目录下建立文件test_mnist.bat,然后输入如下的脚本,

Build\x64\Release\caffe.exetest --model=examples\mnist\lenet_train_test.prototxt-weights=examples\mnist\lenet_iter_10000.caffemodel
pause
双击运行,显示出来结果(准确率为0.9874,损失率为0.040711):

MNIST训练生产的模型进行手写数字进行测试
Step1:制作手写数字样本。打开电脑画图工具,重新调整大小,点击像素,水平和竖直的值置为28。再点击保持纵横比。


将画好0到9的数字依次保存到文件夹RGBnumbers,然后用matlab软件进行格式的转换。(转换原因:画图工具中手写数字依然是三通道的RGB图像,用matlab软件将他们转换成二值图像),转换代码如下:

所有的二值图像都将保存到指定目录下的binarybmp文件夹下。
Step2:把转换好的二值图像拷贝到D:\caffe-master\examples\mnist\
在D:\caffe-master\examples\mnist下建立标签文件synset_words.txt(注意不能有空行出现,必须是10行数字,可以打乱顺序,不一定是从小到大排序):

调用classification.exe去识别某张图片,D: \caffe-master目录新建mnist_class.bat,输入如下脚本:

D:\caffe-master\Build\x64\Release\classification.exe D:\caffe-master\examples\mnist\lenet.prototxt D:\caffe-master\examples\mnist\lenet_iter_10000.caffemodelD:\caffe-master\examples\mnist\mean.binaryprotoD:\caffe-master\examples\mnist\synset_words.txtD:\caffe-master\examples\mnist\binarybmp\0.bmp
Pause
双击运行,得到下面的结果,至此测试结束。

2、cifar-10测试
Step1:下载cifar-10数据集,网址:http://www.cs.toronto.edu/~kriz/cifar-10-binary.tar.gz
然后解压到caffe-master\data\cifar10目录下。


Step2:在caffe-master根目录下建立create_cifar10.bat文件,输入以下脚本:

双击后运行,在example\cifar10文件夹下产生cifar-10的训练数据和测试数据,如下图


Step3:计算图像均值
在D:\caffe-master\Build\x64\Release目录下建立cifar10_mean.bat文件,输入以下脚本:

于是,在D:\caffe-master\examples\cifar10目录下产生mean.binaryproto文件。
由于我们所采用的平台没有英伟达的GPU,故只能采用CPU进行训练,所以将cifar10_quick_solver.prototxt和cifar10_quick_solver_lr1.prototxt中的solver_mode:GPU均改为solver_mode:CPU。
左图为修改前,右图为修改后:




Step4:训练
在D:\caffe-master目录下建立train_cifar10.bat文件,输入以下脚本:

上述命令执行完毕后会在D:\caffe-master\examples\cifar10下生成cifar10_quick_iter_4000.caffemodel.h5以及cifar10_quick_iter_4000.solverstate.h5两个文件,其中cifar10_quick_iter_4000.solverstate.h5将在进一步的训练中使用到,而cifar10_quick_iter_4000.caffemodel.h5模型权值文件可用于数据集的测试(此处可不用,因为还有下面更深层的训练,会生成更深层的模型权值文件cifar10_quick_iter_5000.caffemodel.h5)。

下面将对配置文件中的内容进行简单说明或解释:
net:用于训练、预测的网络描述文件
test_iter:预测阶段迭代次数
test_interval:训练时每迭代多少次,进行一次预测
base_lr、momentum、weight_delay:网络的基础学习速率、冲量和权衰量
lr_policy:学习速率的衰减策略
display:每经过多少次迭代,在屏幕上打印一次运行日志
max_iter:最大迭代次数
snapshot:每多少次迭代打印一次快照
solver_mode:caffe的求解模式,根据实际情况选择GPU或CPU
总结一下训练一个网络用到的相关文件:
· 1:cifar10_quick_solver.prototxt:方案配置,用于配置迭代次数等信息,训练时直接调用caffe.exe train指定这个文件,就会开始训练
· 2:cifar10_quick_train_test.prototxt:训练网络配置,用来设置训练用的网络,这个文件的名字会在solver.prototxt里指定
· 3:cifar10_quick_iter_4000.caffemodel.h5:训练出来的模型,后面就用这个模型来做分类
· 4:cifar10_quick_iter_4000.solverstate.h5:也是训练出来的,应该是用来中断后继续训练用的文件
· 5:cifar10_quick.prototxt:分类用的网络
在D:\caffe-master目录下建立train_cifar10(1).bat文件,输入以下脚本:

.\Build\x64\Release\caffe.exetrain --solver=D:/caffe-master/examples/cifar10/cifar10_quick_solver_lr1.prototxt --snapshot=D:/caffe-master/examples/cifar10/cifar10_quick_iter_4000.solverstate.h5
pause
双击运行得到下面的结果:

在D:\caffe-master\examples\cifar10目录下创建文件synset_words.txt,并写入以下脚本:

Step5测试:
在D:\caffe-master目录下建立文件test_cifar10.bat,并写入以下信息:

Build\x64\Release\caffe.exetest -model examples/cifar10/cifar10_quick_train_test.prototxt -weights examples/cifar10/cifar10_quick_iter_4000.caffemodel.h5-iterations 100
pause
双击后得到预测结果:

测试准确率为0.7147
在D:\caffe-master目录下建立文件test_cifar10(1).bat,并写入以下信息:

Build\x64\Release\caffe.exetest -model examples/cifar10/cifar10_quick_train_test.prototxt -weightsexamples/cifar10/cifar10_quick_iter_5000.caffemodel.h5 -iterations 100
pause
双击后得到预测结果:

测试准确率为0.7544
在D:\caffe-master目录下建立文件cifar10_class.bat,并写入以下信息:

D:\caffe-master\Build\x64\Release\classification.exeD:\caffe-master\examples\cifar10\cifar10_quick.prototxt D:\caffe-master\examples\cifar10\cifar10_quick_iter_4000.caffemodel.h5D:\caffe-master\examples\cifar10\mean.binaryprotoD:\caffe-master\examples\cifar10\synset_words.txtD:\caffe-master\examples\images\cat_gray.jpg
pause
双击后得到分类结果:

猫的概率0.3202
在D:\caffe-master目录下建立文件cifar10_class(1).bat,并写入以下信息:
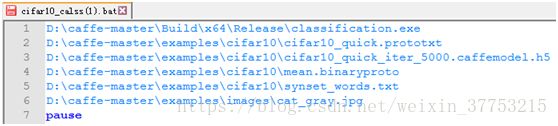
D:\caffe-master\Build\x64\Release\classification.exeD:\caffe-master\examples\cifar10\cifar10_quick.prototxt D:\caffe-master\examples\cifar10\cifar10_quick_iter_5000.caffemodel.h5D:\caffe-master\examples\cifar10\mean.binaryproto D:\caffe-master\examples\cifar10\synset_words.txtD:\caffe-master\examples\images\cat_gray.jpg
pause
双击后得到分类结果:

猫的概率为0.5034.
从分类结果可以看出,训练迭代次数越多,那么最后测试的准确率越高,同时分类的结果也越好。