Deep Sliding Shapes for Amodal 3D Object Detection in RGB-D Images(CVPR2016)(1)
论文:https://arxiv.org/pdf/1511.02300.pdf
代码:https://github.com/shurans/DeepSlidingShape
Abstract
我们专注于RGB-D图像中的三维3D对象检测的任务,其目的在于以完整的程度以度量形式生成对象的3D边界框。 我们介绍了深度滑动形状Deep Sliding Shapes,这是一种3D ConvNet方法,它将RGB-D图像中的3D体积场景作为输入并输出3D对象边界框。 在我们的方法中,我们首先提出了3D区域提议网络(RPN)来学习几何形状的对象性objectness?和联合对象识别网络(ORN)joint Object Recognition Network (ORN)来提取3D中的几何特征和2D中的颜色特征。 特别是,我们通过训练两个不同比例的amodal RPN和ORN来回归3D边界框来处理各种大小的物体。实验表明,我们的算法在mAP中优于现有技术 13.8,比原始滑动形状快200倍。
1 Introduction
典型的物体检测可以预测物体的类别以及物体可见部分the visible part在图像平面上的2D边界框。虽然这种类型的结果对于某些任务(例如对象检索)是有用的,但对于在真实3D世界中进行任何进一步推理是相当不可取的。在本文中,我们专注于RGB-D图像中的三维物体检测任务,其目的是产生一个物体的3D边界框,无论截断或遮挡 truncation or occlusion,都能在物体的全部范围内提供真实世界的尺寸。例如,在机器人应用的感知操纵循环中,这种识别更有用。但为添加新维度(深度Depth)用来预测会显着扩大搜索空间,并使任务更具挑战性。
可靠且价格合理的RGB-D传感器(例如,Microsoft Kinect)的到来使我们有机会来实现这一关键任务。然而,将二维检测结果简单地转换 naively converting为3D并不能很好地工作(见表3和[10])。为了充分利用深度信息,提出了滑动形状[25]来在3D空间中滑动3D检测窗口。虽然它受到手工制作功能的限制,但这种方法自然地制定了3D任务。
或者,深度RCNN [10]采用2D方法:通过将深度视为彩色图像的额外通道来检测2D图像平面中的对象,然后使用ICP将3D模型拟合到2D检测窗口内的点对齐。鉴于问题的现有2D和3D方法,很自然地会问:哪种表示更适合3D模拟对象检测,2D或3D?目前,以2D为中心的深度RCNN优于以3D为中心的滑动形状。但也许深度RCNN的优势来自于使用精心设计的深度网络预先训练过的ImageNet,而不是它的2D表示。是否有可能通过利用3D深度学习获得优雅但更强大的3D方法?
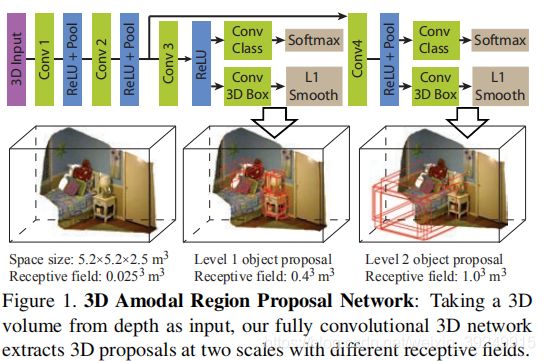
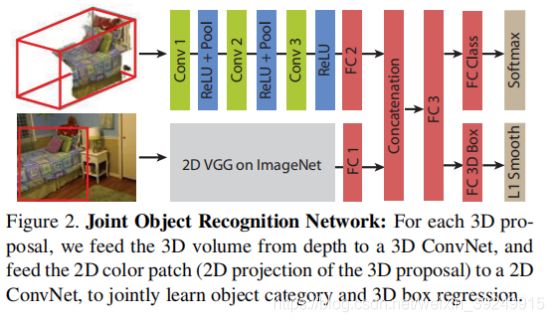
在本文中,我们介绍了Deep Sliding Shapes,这是一个完整的3D方法,用于学习使用3D卷积神经网络(ConvNets)的对象建议和分类器object proposals and classifiers。我们第一个提出了3D区域提议网络(RPN),它将3D体积场景作为输入并输出3D对象提议(图1)。它旨在为不同尺度的物体以两种不同的比例生成整个物体的建议。我们第一个还提出了联合目标识别网络(PRN),它使用2D ConvNet从颜色中提取图像特征,以及3D ConvNet从深度中提取几何特征(图2)。该网络也是第一个直接从3D提案中回归对象的3D边界框的网络。大量实验表明,我们的3DConvNets可以比2D表示(例如Depth-RCNN中的HHA)学习更强大的编码几何形状(表3)的表示。我们的算法也比Depth-RCNN和原始的Sliding Shapes快得多,因为它只需要在测试时在GPU中进行一次ConvNets前向传递。
我们的设计充分利用了3D的优势。因此,我们的算法自然受益于以下五个方面:首先,我们可以预测3D边界框,而无需从额外的CAD数据??拟合模型的额外步骤。这样可以简化 pipeline,加快速度并提高性能,因为网络可以直接优化最终目标。其次,由于遮挡,视野受限以及由于投影导致的大尺寸变化,因此在2D中建模生成和识别非常困难。但在3D中,由于来自同一类别的物体通常具有相似的物理尺寸,并且遮挡物的偏差落在窗外the distraction from occluders falls outside the window,我们的3D滑动窗口建议生成可以自然地支持amodal检测。第三,通过在3D中表现形状,我们的ConvNet有机会在更好的对齐空间中学习有意义的3D形状特征。第四,在RPN中,感受野自然地以现实世界的尺度表示,这指导了我们的结构设计。最后,我们可以通过使用Manhattan world假设来定义边界框方向,从而利用简单的3D上下文先验。
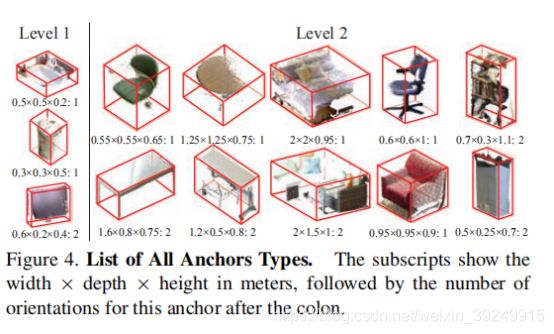
虽然机会令人鼓舞,但3D物体检测也存在一些独特的挑战。首先,3D体积表示需要更多的内存和计算。为了解决这个问题,我们建议将3D区域提议网络与作为输入的低分辨率整个场景分开,并为每个对象分配具有高分辨率输入的对象识别网络。其次,3D物理对象边界框的大小比2D像素为基础的边界框(由于摄影和数据集偏差due to photography and dataset bias)[16]更复杂。为了解决这个问题issue,我们提出了一个多尺度的区域建议网络,它使用不同的感受域来预测不同大小的建议。第三,虽然深度的几何形状非常有用,但它们的信号频率通常低于彩色图像中的纹理信号。为了解决这个问题,我们提出了一种简单但有原则的方法来联合合并jointly incorporate来自通过投影3D区域提议而得到的2D图像补丁的颜色信息。
1.1 Related works
Deep ConvNets彻底改变了基于2D图像的对象检测。 RCNN [8],快速RCNN [7]和更快的RCNN [18]是最成功的现有技术的三次iterations。 除了仅预测对象的可见部分之外,[14]进一步扩展RCNN以估计整个对象的amodal框。 但他们的结果是二维的,只估计物体的高度,而我们想要desire一个三维的模式盒子。 受到2D成功的启发,该文章提出了一个集成的3D检测管道,可以使用3D ConvNets为RGB-D图像利用3D几何线索。
RGB-D图像中的2D物体检测器:RGB-D图像的2D物体检测方法将深度视为附加外部通道添加到RGB图像,使用手工制作的特征[9],稀疏编码[2,3] ],或递归神经网络[23]。 Depth-RCNN [11,10]是第一个在RGB-D图像上使用深度ConvNets的物体检测器。 他们通过将深度图编码为附加到彩色图像的三个额外通道(具有地心编码Geocentric Encoding:视差,高度和角度)来扩展用于基于颜色的对象检测的RCNN框架[8]。 [10]通过将3D CAD模型与识别结果对齐,扩展了Depth-RCNN以生成3D边界框。 [12]通过交叉模型监督转移进一步改善了结果。 对于3D CAD模型分类 3D CAD model classification,[26]和[20]采用基于视图的深度学习方法,将3D形状渲染为rendering2D图像。
3D物体检测器:滑动形状Sliding Shapes[25]是一个3D物体探测器,它以3D形式运行滑动窗口,直接对每个3D窗口进行分类。 但是,该算法使用手工制作的功能,并且该算法使用许多示例分类器,因此它非常慢。 最近,[32]还提出了RGB-D图像上的 the Clouds of Oriented Gradients feature。 在本文中,我们希望通过3D ConvNets改进这些手工制作的特征代表,这些代表可以从数据中学习强大的3D和颜色特征。
3D特征学习:HMP3D [15]引入了一种分层稀疏编码技术,用于RGB-D图像和3D点云数据的无监督学习特征。该特征在合成CAD数据集上进行训练,并在RGB-D视频中的场景标记任务上进行测试。相比之下,我们需要使用深度学习技术来学习3D特征的有监督方式,这些技术被证明对基于图像的特征学习更有效。
3D深度学习:3D ShapeNets [29]引入了用于建模3D形状的3D深度学习,并证明了可以从大量3D数据中学习强大的3D特征。最近的一些着作[17,1,5,13]也提取了用于CAD模型检索和分类的深度学习功能。虽然这些作品令人鼓舞,但它们都没有专注于RGB-D图像中的3D物体检测。
区域提案:对于2D对象提议,先前的方法[27,1,11]主要基于合并分段结果。最近,更快的RCNN [18]引入了一种更高效,更有效的基于ConvNet的配方,激励我们使用ConvNets学习3D对象。对于3D对象提议,[4]介绍了一种MRF公式,其中包含针对街景中几个对象类别的手工制作的特征。我们希望使用ConvNets从数据中学习一般场景的3D对象。
1.2 Encoding 3D Representation
我们需要回答3D深度学习的第一个问题是:如何编码3D空间以呈现给ConvNets?对于彩色图像,输入自然是像素颜色的2D阵列。对于深度图,深度RCNN [10,11]提出将深度编码为具有三个通道的2D彩色图像。虽然它有利于将预先训练好的ConvNets用于彩色图像[12],但我们希望能够在3D中自然地编码几何形状,从而保留空间局部性。此外,与使用手工制作的3D特征[5,31]的方法相比,我们希望能够将3D几何体编码 encodes the 3D geometry为尽可能原始的表示,并让ConvNets从原始数据中学习最具辨别力的特征。
为了编码用于识别的3D空间,我们建议采用方向截断的符号距离函数(TSDF“截断有符号距离函数”(truncated signed distance function,简称TSDF))。给定3D空间,我们将其划分为等间距的3D体素网格。每个体素中的值被定义为体素中心与来自输入深度图的表面之间的最短距离。图3显示了一些例子。为了对表面点的方向进行编码,而不是单个距离值,我们提出了一个方向性TSDF,用于在每个体素中存储三维向量[dx,dy,dz],以记录三个方向到最近的表面点的距离。该值被剪切为2β,其中β是每个维度中的网格大小。值的符号表示单元格是在表面的前面还是后面。
为了进一步加速TSDF计算,采用一个近似,我们也可以使用投影TSDF而不是精确的TSDF,其中最近的点仅在相机的视线上找到。投影TSDF的计算速度更快,但与准确的TSDF识别相比,在经验上 empirically更差(见表2)。我们还尝试了其他编码,我们发现所提出的方向性TSDF优于所有其他替代方案(见表2)。请注意,我们还可以通过将RGB值附加到每个体素来对此3D体积表示中的颜色进行编码[28]。
未完,待续!!请见Deep Sliding Shapes for Amodal 3D Object Detection in RGB-D Images(CVPR2016)(2)