最火的几个全网络预训练模型梳理整合(BERT、ALBERT、XLNet详解)
前言
过去两年可谓是NLP领域的高光年,自从18年BERT提出,狂刷了11项下游任务的记录之后,全网络预训练模型开启了NLP嵌入表示的新时代,真正意义上实现了自然语言处理的迁移学习。
作为一个刚入坑没多久的白中白,真心感叹自己接触太晚,但是又愁于感天动地的英文阅读能力,再加上原论文有些语句的描述实在是晦涩难懂,在翻阅大量博客和视屏之后,总算花了一整天时间,把过去几年最火的几个模型原理大致梳理明白了。借此写一篇博客,虽然许多内容参考了其他blog,但也是经过自己消化理解,按照自己的思路罗列的。目的只是为了把一些记下来的零散的东西梳理清楚,put all these things together。
文章的篇幅比较长,提及多个模型的要点,并将其按照顺序梳理,想要一次性读完有点困难。像我一样的初学者可以把这篇文章当做map,有些不懂的地方可以穿越到文末罗列的参考文章去,至于大佬…饶弟弟一命。
文章目录
- 前言
- 1. ELMO--上下文语境的提出
- 1.1 传统词嵌入的问题
- 1.2 ELMo的提出
- 1.3 ELMo的缺点
- 2. BERT--站在巨人的肩膀之上
- 2.1 诞生背景
- 2.2 Transformer--Attention is all your need
- 2.2.1 背景
- 2.2.2 直观理解Transformer
- 2.2.3 self-Attenton编码过程
- 2.2.4 Q、K、V的灵感来源
- 2.2.5 Multi-headed attention
- 2.2.6 其他细节
- 2.2.6.1 Position Encoding
- 2.2.6.2 残差连接&Layer Normalization
- 2.2.7 self-Attention解码过程
- 2.3 回到BERT
- 2.3.1 MLM--困难版完形填空
- 2.3.1.1 任务描述
- 2.3.1.2 带来的效果
- 2.3.2 NSP--简化版段落重排
- 2.3.2.1 任务描述
- 2.3.2.2 带来的效果
- 2.3.2.3 实现的细节
- 2.4 BERT的优点
- 3. ALBERT--BERT的“减肥计划”
- 3.1 诞生背景
- 3.2 ALBERT的参数压缩
- 3.2.1 Token Embedding
- 3.2.2 Attention&Feed-Forward
- 3.2.3 瘦身之后的结果
- 3.3 ALBERT在其他细节上的优化
- 3.3.1 SOP代替NSP
- 3.3.2 去除MLM中的drop out
- 4. Autoregressive vs Auto-encoding
- 4.1 定义
- 4.2 优缺点比较
- 5. XLNet--似乱非乱两相随
- 5.1 诞生初衷
- 5.2 Permutation Language model--似乱非乱
- 5.2.1 直观理解
- 5.2.2 实现细节
- 5.3 Two-Stream Self-Attention--两相随
- 5.3.1 位置信息的丢失
- 5.3.1.1 standard parameterization
- 5.3.1.2 new parameterization
- 5.3.2 双流自注意力
- 5.3.2.1 K、Q、V的分流
- 5.3.2.2 数学上的表达
- 6. 总结
- *2020-7-10凌晨更新*
- 参考资料
1. ELMO–上下文语境的提出
1.1 传统词嵌入的问题
不管是基于local训练的Word2vec,还是基于全局的Glove,传统词嵌入存在的一个很大的问题:一旦预训练词向量,就只能将其按照训练结果嵌入模型中,这样会导致词向量无法根据具体语境作动态的调整。比如说下面这个句子:
There is a traffic 'jam',so I began to eat my apple 'jam'.
第一个jam是堵塞,第二个jam是果酱。明显,两个单词的含义完全不同。如果仅仅只是将jam用同一个词向量表示,无疑给下游任务造成了巨大的噪声。因此传统词嵌入只能依据具体语境去训练Embedding(或者在有更多语料的相似语境训练),无法像CV一样做迁移学习(VGGNet)。
1.2 ELMo的提出
18年8月,AllenNLP提出了一个上下文相关模型–ELMo(Embeddings from Language Models),强调了上下文语境的重要性。

ELMo结构其实就是一个Bi-LSTM,他的输入是词向量列表(可以是Word2vec、Glove),把这些词向量先从左向右encoding得到一个token间的联系(图中红色),再从右到左(图中紫色),最后将这两部分拼接得到句子的context信息。

而这个拼接的过程异常简单,只是做了一个头尾连接,再加权求和得到一个融合了上下文语境的词向量(图中蓝色)。

1.3 ELMo的缺点
- 不完全双向:虽然明面上叫做Bi-LSTM,但其实只是两个单向的LSTM的隐藏层强行拼接之后做了一个线性组合,而这两个LSTM是分开计算的,并没有做到同时考虑上下文(注意,这里讲的是同时双向)
- 照镜子:又叫做“套娃”,也就是在执行预测的时候,某个位置的token可能已经提前察觉到了自己的信息,就如同照镜子一般。这个是考虑双向的模型都要面对的一个棘手问题,因为在ELMo训练的过程中,模型的task是预测下一个单词的概率分布,随着层数的增加,某个位置的单词在某个方向预测的时候可能会被底层间接地透露要预测的答案。

如上图,假如说现在要预测第二列第二行,那么这个cell获悉的信息将是下层B输出的内容,它左边是A,右边是CD,因此这个cell在预测的时候获知了A|CD
接下来如果要继续预测第二列第三行,还是依据下层的输出来预测,显然,它获悉了从左边过来的BCD,和从右边过来的AB|D,也就是将ABCD的信息全部透露给了这个cell,这对于模型的训练是不利的(考试作弊一般) - 需要有针对下游任务的接口:这是ELMo本身决定的,因为它是通过语言模型任务得到句子中单词的 embedding 表示,以此作为补充的新特征给下游任务使用,是一种基于特征的预训练(Feature-based Pre-Training <下文会讲到 BERT是一种 Fine-tuning 的模式 >)。也可以这样理解:ELMo是将每一层的隐藏向量加权求和得到最终的向量,每一层可以当作是一个独立的功能模块。例如,原论文中设定了两个隐层,第一隐层可以学到对词性、句法等信息,对此有明显需求的任务可以对第一隐层参数学到比较大的值;第二隐层更适合对词义消歧有需求的任务,从而对特定任务可以分配更高权重。
- LSTM的长期依赖:这个是LSTM,或者说是RNN一直以来存在的一个问题,虽然说LSTM利用偷窥孔连接的机制很大程度上缓解了这个问题,但是并没有从根本上解决反向传播过程中的梯度消失。
- 基于LSTM的模型特征抽取能力偏弱:这点是通过和Transformer比较得出的,下文将会提到(没有比较就没有伤害)
2. BERT–站在巨人的肩膀之上
2.1 诞生背景
BERT在ELMo提出的同年9月正式发表,本来ELMo就因为训练慢、效率不高被一些人摒弃,BERT一出算是彻底凉了。BERT的全称是Deep Bidirectional Transformers for Language Understanding,硬取了名字缩写BERT,目的是刚好和ELMo在一部国外很火的动画片里面撞名,也算是对ELMo的一种致(tong)敬(qing)了吧。
下图,红色小不点是ELMo,黄色长脸冲顶一字眉的是BERT

BERT的灵感来源是OpenAI在17年发布过的一篇名为“Attention is all your need”论文中提到的Transformer模型,刚好ELMo又率先提出了上下文语境这一关键的概念,给BERT的诞生创造了非常好的条件。所以可以这样说–BERT是站在巨人的肩膀之上的。
BERT利用了Transformer中的encoder代替了传统的LSTM,所以它的结构可以被看做是一种堆叠的Transformer。
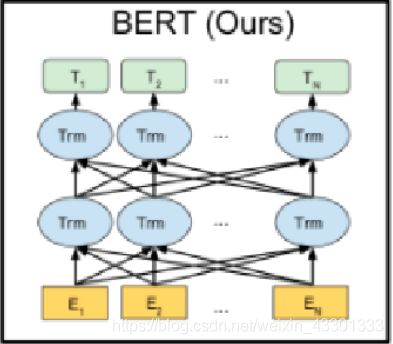
由于Transformer是BERT的一个至关重要的概念,因此下面重点介绍一下Transformer模型。
2.2 Transformer–Attention is all your need
2.2.1 背景
Transformer由17年一篇著名论文“Attention is All Your Need”提出(敢这么取title的也真的不多),现在是谷歌云TPU推荐的参考模型.。在论文中,作者提出了一种全新的注意力机制-- self-Attention,做到了仅仅利用Attention代替了传统的RNN(作者还大力诟病RNN,从title也可以看出其不屑),实现了快速并行计算,挖掘了DNN的特性。其模型结构特别适用于MNT,能够大程度地提升翻译的准确率。
2.2.2 直观理解Transformer
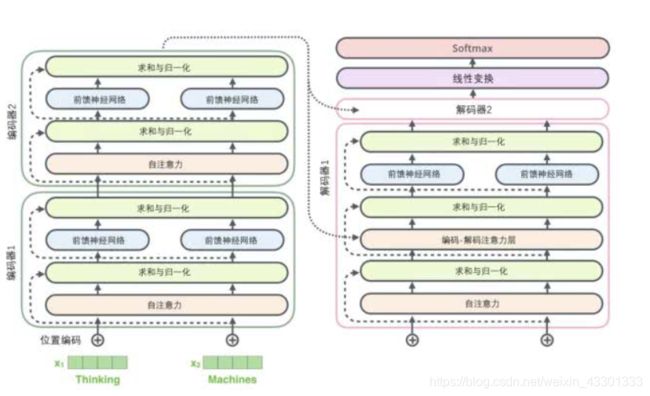
Transformer主要分为两个部分:编码组件+解码组件,这点和传统的RNN编码、解码的结构很像,但是内部结构完全不同。

编码组件由多个encoder(编码器)堆叠而成(原论文中是6个,也可以换成其他数量)
每个encoder又有两个子层,分别是 FFN(前馈神经网络) + self-Attention(自注意力层)

FFN就是再熟悉不过的MLP(多层感知器架构),重点和创新点就在于self-Attention层。它的输入是一个单词经过词嵌入处理的句子,也就是一个词向量列表(下图中的 x,论文中是512维),输出是结合了句子本身上下文注意力之后的融合向量(下图中 z)。

什么叫做融合了自身上下文注意力?比方说现在有一个句子:
The animal didn’t cross the street because 'it' was too tired
对于我们学过英语的人来说,我们心里很清楚句子里的那个 ‘it’ 指代的是前文的 ‘animal’,不是‘apple’,也不是 ‘Tom’;而它现在的状态是‘tired’,不是‘excited’,也不是‘sexy’.因为我们知道在处理‘it’这个单词的时候,应该把注意力投入到哪里。把注意力这个抽象的概念可视化就可以得到下面这幅图:

如图,颜色越深说明这个单词和‘it’的关系越大,投入的注意力自然就越多。从图中可以看出,“The”、“animal”是和“it”关系最大的,这符合常理。
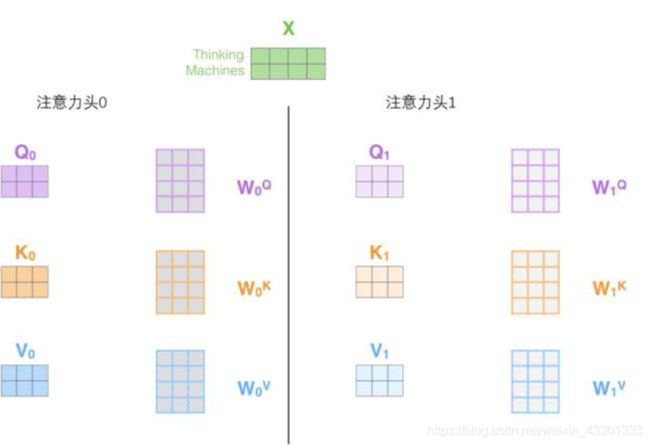
而从x到z的过程,就要借助self-Attention层的三个隐藏的权重矩阵—WQ (查询矩阵)、WK(键矩阵) 、WV(值矩阵)
2.2.3 self-Attenton编码过程
- 首先对于输入的词向量列表x1 x2…xn,我们将其和self-Attention层的三个权重矩阵WQ 、WK 、WV 相乘,得到三种中间向量Q (查询向量) K(键向量)V(值向量)。例如我们现在有两个单词:“Thinking”和“Machines”的初始词向量x1和x2,我们做的操作如下:

可能到这里你会觉得很懵逼,为什么要有这三个中间向量?这里先卖个关子,下文会解释其中的原因。 - 接下来我们将用Q和K这两个中间向量来计算self-Attention的分数。比方说我们想要知道“Thinking”这个单词应该对句子上下文的其他单词投入多少注意力,我们要做的就是计算Q1*K1、Q1*K2,然后把这两个分数除以一个常数(目的是为了让梯度更稳定),再经过softmax归一化,如下图

经过计算,“Thinking”自己和自己的关系最近,self-Attention分数达到0.88,这个值就代表了之前我们可视化过的 注意力程度(8是论文中使用的键向量的维数64的平方根,这里也可以使用其它值,8只是默认值)
- 最后,我们将上面得到的归一化之后的分数和第一步获得的中间向量V1 V2相乘求和,随后就得到了“Thinking”这个单词在该层的自注意力向量z1,如下图。

2.2.4 Q、K、V的灵感来源
很多blog在谈及这三个向量的时候总是顺理成章地带过,很少有解释的。其实这三个中间向量对应三个概念:Queries、Key、Value,其灵感来自于早期的文件检索。
比如说我们现在要检索的内容是“iron man”,而我们的文件库中有下面的信息:
Key : Value
‘iron man’: 史塔克
‘thunder’ : 索尔
‘spider’ : 帕克
这个时候Q就是我们要查询的内容‘iron man’,利用Q分别和文件库中的K1 K2 K3相乘得到一个相似程度的分数,比方说结果是0.73 0.07 0.20,根据这个分数查找到我们需要检索的内容,即“iron man --史塔克” 。
self-Attention就是运用了这个灵感,来计算每个单词和其他单词之间的关联程度,即自注意力大小。
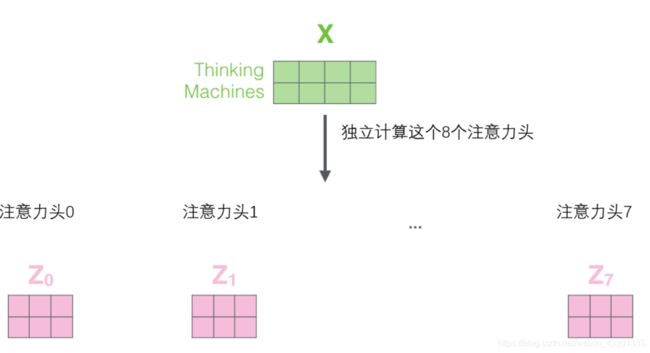
2.2.5 Multi-headed attention
到现在为止,你应该已经对Transformer的核心概念有了直观的理解。事实上,为了能够从不同角度捕捉不同的关联程度,Transformer利用了一种"多头"的self-Attention机制。即一个self-Attention层拥有多组WQ 、WK 、WV ,每组分别用于不同的特征提取。
下面这幅图是之前已经见过的注意力可视化:

如果把橘色当作是“it”指代名词的投入注意力程度,那么也可以用其他颜色,从其他角度,来展示其他单词和"it"关系的远近。比方说下面的绿色就可以表示“it”现在所处状态:

可以看到和“it”关系最大的是‘tired’,同样我们可以把其他head都可视化:

也就是说,每个“头”都将生成一组独立的z
而Multi-headed attention最后做的就是把所有“头”通过一个高纬度的矩阵W0 put together

把上述整个过程放到一起:
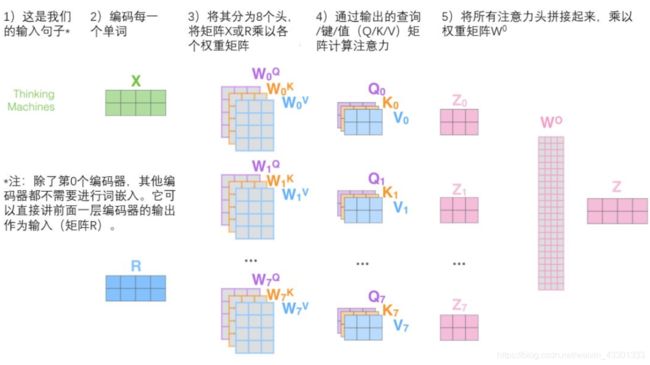
到此,我们对self-Attention层也算是彻底讲清楚了
2.2.6 其他细节
2.2.6.1 Position Encoding
由于self-Attention的机制,使其不能像RNN那样捕捉到token之间的空间、序列关系,即很有可能会丢失位置信息。比方说:
我吃坏了'东西',得去拉'肚子' vs 我吃坏了'肚子',得去拉'东西'
如果仅仅利用self-Attention,很有可能模型会对上述两个句子产生混淆(显然后者并不那么文雅…),因为“肚子”、“东西”这两个名词和“吃”、"拉"两个动词之间貌似并没有很强的关联性(别问我为什么没有关联性,问就是奥里给!)
解决的办法就是引入一个新的Embedding:Position Encoding(位置编码),而Transformer采用的是正弦波,目的是为了模拟信号的周期变化。这种周期性的循环一定程度上会加强模型的泛化能力。

通过将融入Position Encoding之后的向量可视化,可以观察到两个token的空间距离越近,他们位置编码的点积结果就越大,这也符合逻辑。

当然,也可以选择其他的Position Encoding策略,甚至可以一开始把Position Encoding随机初始化,通过训练来更新(BERT的做法)
2.2.6.2 残差连接&Layer Normalization
除了到目前为止介绍的"多头机制"和position encoding,作者还建议再self-Attetion上使用Residul(残差)和Layer Normalization(层正则化),这些也都不是必须的,但是作者建议使用。
-
Residual:残差最初是出现在CV中的ResNet,用于解决网络层数过深导致训练无法收敛的问题。具体细节可以参考其他blog.这里不作过多赘述。

-
Layer Normalization:层正则是Toronto Univercity于16年提出的,它和我们最熟悉的Batch Normalization使用的方法一模一样。只不过这里是对每一层的结果 at 求出均值和方差,而不是对Batch.
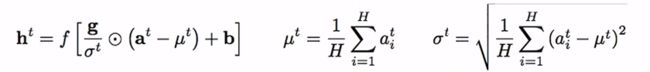
至于这两者之间的区别可以用下面这张图体现(红色是Batch,黄色是Layer):

也就是说在进行Layer Normalization的时候,我们并不去关心Batch中其他的向量,只关心当前一层进行正则化,从而避免了和Batch的强相关(Batch normalization则是以Batch为单位求均值、方差,进行正则划)原论文:Layer Normalization
最终,一个完整的encoder将会是这样:

2.2.7 self-Attention解码过程
解码器和编码器的工作原理几乎相同。编码器的顶端最后会输出一个包含K、V的注意力向量集合,这个向量集将被为给解码器的“编码解码注意力层”,这些层可以帮助解码器关注输入序列哪些位置需要被添加注意力。
解码器最终的输出将会经过一个softmax的转换,得到下一个要吐出来的单词的概率分布(其实就是个Language Model了)。具体细节这里不再过多赘述,若觉得有地方显得模糊可以参考blog:
图解Transformer(完整版)
Transformer的最终结构如下图:
2.3 回到BERT
上文花了大量笔墨介绍Transformer,因为它对于BERT来说是一个关键点,到这里相信你已经对BERT的核心-Transformer有了比较直观的理解了,接下来对于BERT的理解也将变得简单。
PS:如果你对 Transformer还有不清楚的,建议跳转到文末,查询对应的 blog,或者自行查阅资料。
基于ELMo和Transformer,BERT想要做的就是 既保留ELMo的序列结构,又拥有Transformer的真正双向的特点,和它的并行计算的能力,从而进一步增加词向量模型泛化能力,充分描述字符级、词级、句子级甚至句间关系特征。因此,BERT采用了一种“Bi-Transformer”的整体结构.

为了达到这个目的,BERT就必须解决ELMo遗留的问题,尤其是如何解决照镜子的难题,这对于任何一个想要同时考虑双向的模型来说都是绕不过去的。
因此,BERT将其训练的任务分为两个部分:MLM(Masked language Model)+ NSP(Next Sentence Prediction)
2.3.1 MLM–困难版完形填空
2.3.1.1 任务描述
Masked language Model(随机掩盖原词)这个任务是这样的:给定一句话,随机将这句话中15%的token给Mask掉,然后利用剩下的token去预测被Mask掉的原词。
由于Mask这个操作是与训练过程中引入的,对于下游的NLP具体任务来说,Mask并不存在,因此BERT在Mask的位置按照一定比例进行了如下操作来更改token:
- 80%的概率用“[Mask]”特殊标记掩盖 -------------------------------This sexy gril is my [Mask]
- 10%的概率用语料中的随机采样来的token替换原词-----------------This sexy boy is my girlfriend
- 10%的概率不做任何替换----------------------------------------------This sexy gril is my girlfriend
2.3.1.2 带来的效果
这个任务带来的好处是会迫使模型去理解上下文,并且赋予了模型一定程度的纠错能力。这很好理解,就和我们自己高中的时候刷完型一样,为了填空,我们必须仔细地斟酌上下文地语境,根据语境去预测这个Mask是动词、名词或者形容词?动词的话时态如何,是否第三人称单数?名词的话是否是单复数+s?更何况这还不是一般的完形填空,因为MLM的机制,不仅可能把原词Mask了,更可怕的是会出现随机替换的现象(比方说上面的 This sexy boy is my girlfriend),这无疑是一种困难版地完形填空,给人的感觉就仿佛是在有意刁难。但是正是这种刁难,让模型的训练变得十分有效果,它必须尽全力去观测上下文,时态、指代…
而BERT的每一个cell采用的是Transformer,这很大地促动了模型对于任务的达成。因为我们已经知道,Transformer擅长的就是通过Multi-head来抽取语料中不同的上下文特征。

2.3.2 NSP–简化版段落重排
2.3.2.1 任务描述
Next Sentence Prediction(下一个句子预测)这个任务是这样的:给定一个句对,通过对这两句话的分析,判断第二句话是否真的是第一句话在原文中的下一句。
训练时,句对的第二句将会以50%的概率从全部文本(注意这里的“全部文本”,下文介绍的ALBERT抓住了这一点进行了优化)中随机抽取,剩下50%的概率选取第一个句子在原文中的真正的下一句。
熟悉Word2vec的同学可能会想到负采样,其实这里也是一样,即随机抽选一个负样本,在挑出正样本,通过二分类进行预测,只不过NSP是建立在sentence-level之上的。
2.3.2.2 带来的效果
正是由于sentence-level的加入,BERT在一些需要依赖句子级信息的NLP下游任务中迸发了很强的潜力,(QA、SLI…)而不是仅仅学到一堆token级别的词向量,这点也很好地解决了ELMo中,需要根据下游任务调整各层隐藏层权重的问题。
2.3.2.3 实现的细节
- [SEP]&[CLS] :为了实现sentence-level,BERT在每个input前面加了特殊标记 [CLS] ,在每个句子的结尾部分加了另一个特殊标记 [SEP] 。
[SEP] 很好理解,作为一个句子结尾的记号,关键在于对 [CLS] 的理解。 [CLS] 的作用其实就是将整个句对/句子的上层抽象信息作为最终的最高隐层输入softmax中。
就拿一个句对来说,通过BERT的上下文信息提取,让Transformer对 [CLS] 进行深度encoding,由于Transformer是可以无视空间和距离地把全局信息encoding进每个位置的,因此 [CLS] 最终将会提取到有关于两个句对之间的高层抽象关系。
如下图,提取的有关于句对的信息将会被输入到一个分类器,输出预测结果。

- Position embedding:和Transformer一样,BERT也会丢失一些token之间的空间距离关系。在Transformer中,Posisuijiction encoding是采用了正弦波,而BERT显得简单粗暴,直接将Position encoding随机初始化,通过反向传播更新。
- Segment embedding:由于是sentence-level,所以输入中还必须加入一个flag来区分两个句子。最简单的做法是加0/1区分。
所以总结一下,BERT做的事情就是把Token Embedding、Position embedding、Segment embedding粗暴地concat(没错,就是直接concat),并且在句子/句对中加上了 [SEP]&[CLS] 两个标记。把上述put together就是类似与下面这幅图:

PS.对于BERT直接将三个Embedding暴力concat的做法,其实是有很多争论的,有兴趣可以点击下面这个链接,参与讨(zui)论(pao):
神仙打架传送门
2.4 BERT的优点
相较于ELMo,BERT的成功总结一下有下面几点:
- 同时双向:这点得益于Transformer的self-Attention.
- 遮住了镜子:禁止套娃。在介绍ELMo的时候提到过,双向条件会让每个词在多层次语境中间接地看到自己。而BERT解决这个问题的一个杀招就是MLM,即掩码。MLM这个任务被加入到BERT的训练,产生的效果就是直接把镜子遮住了,或者说直接把自己给遮住了。
在预测15%被Mask掉的token时,模型根本没办法,或者说根本不敢去相信自己察觉到的信息,因为很有可能这个信息是个错误的引导(典型的DAE LM,引入噪音,增加鲁棒,下文会提到) - 模型更加复杂化:采用两种任务联合训练的模式,使得模型输出的每个字、词都尽可能地、全面地、准确地刻画出文本的整体信息,为后续的fine-tuning做了更多有效的工作。另外不得不提的一点是,BERT相较于ELMo,拥有更多的训练数据和模型参数。(参数过多其实也是一个潜在的缺点,而ALBERT的优化也抓住了这一点,下文会介绍)
至于BERT的缺点,将会在下文介绍XLNet之前罗列。
3. ALBERT–BERT的“减肥计划”
3.1 诞生背景
ALBERT是19年由Google蓝振忠等人发表的一种轻量级BERT,是BERT众多变体中的一种。可谓是将原先的BRET进行了一次“大瘦身”。其最初的设计灵感来源于卷积视觉中的AlexNet(因为蓝振忠博士在研究生阶段就是做CV出身的),旨在通过将BERT中的模型参数大幅度减少,解决参数过多超出内存导致无法将网络加深、加宽的问题。
下图展示了AlexNet在网络加深情况下,模型效果的变化,可以看出随着模型深度增加,其精度也在大幅上升。

3.2 ALBERT的参数压缩
蓝振忠博士和其组内成员分析了BERT的参数组成,将模型参数分为两部分:
- Token Embedding-----------约占20%
- Attention Feed-forward-----约占80%
因此,蓝博决定从上面两个方向去对BERT参数进行改动。
3.2.1 Token Embedding
在Token Embedding层,BERT的做法是将每个token的one-hot编码连入一个高维的平坦层。如下图:
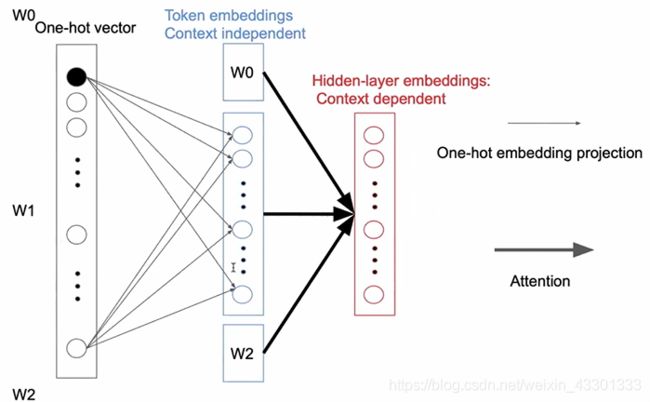
这种做法带来的副作用是很明显的:
- 反向传播更新参数,只能更新hot的那一个点,过于稀疏(比方说词表长度为3W,每次却只能更新一个)
- Token Embedding 时,每个token还是上下文无关的(context independent)而没有融合上下文信息的token,其含义其实是非常简单的(你可以理解成词与词之间是正交的,one-hot之间毫无关联),因此没有必要将其展成那么高的维度。
因此可以采用如下方法将Token Embedding层参数减少:

在Token Embedding的过程中,先将向量压缩成一个低维的表示,在真正需要进行Attention操作之前,再把Token Embedding的维度提升。这样的做法会带来两个好处:
- size减小:Token Embedding size维度减少.上图中最左边的那一层需要通过和一个矩阵相乘得到第二层,一旦第二层维度减少这个矩阵参数也自然变少。
- 参数转移:很明显,对于BERT来说,其参数有用的部分是集中在context dependent的层上,而不涉及context的Token EMbedding 拥有的大量参数是浪费的。一旦将这部分参数减少,就可以将后面的Hidden-layer embeddings 加深(上图红色层),提高参数的利用率。
所以这一步通过将原本一个高纬度网络分解为两个较低维度的中间网络,实现了从O(V x H)到O(V x E + E x H)的转变(E是远小于H的)

通过实验验证得到结果(采用多个下游任务取Average进行评估):

可以看到实验结果表示,在模型性能基本不变的情况下(0.6%),Token Embedding层的参数减少了80%以上。
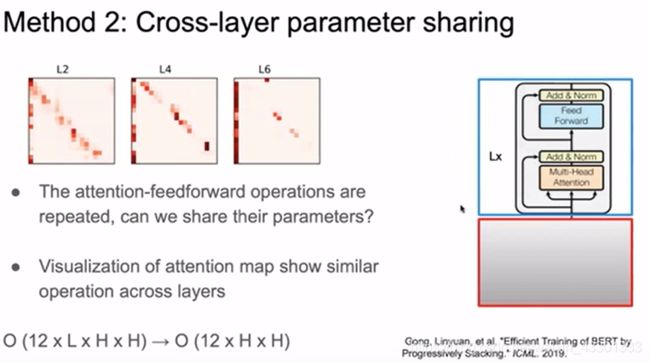
3.2.2 Attention&Feed-Forward
蓝博参考了论文“Efficient training of bert by progressively stacking”对 Attention&Feed-Forward 层可视化的结果,发现对于encoder的各层,其参数在结构上呈现一种相似性(下图中的第一列其实就是[CLS]标记,每一个encoder层除了参数大小不一样,分布结构上呈现很强的一致性):

原论文:Efficient training of bert by progressively stacking
如果能够把所有 Attention&Feed-Forward 层的参数进行共享,那么BERT模型的参数又将是下降一个数量级的
实验得出的结果如下:

在模型深度保持不变的前提下,将 Attention&Feed-Forward 层的所有参数共享,使得参数从原先的108M降低到了31M,而精度并没有太大的降低(2.5%)

如果再观察地仔细一点,会发现只共享FFN参数的精度和将attention&FFN所有参数共享的精度几乎一致(0.3%),而FFN参数一旦共享,精度就会下降比较明显。说明精度的降低主要是因为FFN参数的共享。从这个角度来看,Attetion层的参数完全可以放心大胆共享
但是考虑到Attention层的参数占整个encoder的不到3/8,因此蓝博决定将所有参数进行共享。
3.2.3 瘦身之后的结果
在上述两种方法实行基础上,得到的实验结果:

最终,ALBERT将Token Embedding 层参数从原先E=768降低到E=128,并将Attention&Feed-Forward层的所有参数进行共享。将BERT最开始108M的参数压缩到12M,同时精度仅掉了2.2%!
随后,兰博团队将压缩之后的网络进行了大规模的加宽、加深,并且进行了长时间的训练。最终的结果如下:
 最终30%参数减少的情况下,还提升了ALBERT 3.5%的精度,这个结果可以说是非常不错的了。但是这样做的代价同样很昂贵,ALBERT花了BERT3倍的时间才将模型训练至收敛。(因为毕竟网络被加宽加深,模型变得比BERT还要复杂,而这些新增的参数还是需要被更新,更何况这些参数还都是被refine共享过的,所以在计算上没有地方可以偷懒。一种典型的以时间换空间的做法)
最终30%参数减少的情况下,还提升了ALBERT 3.5%的精度,这个结果可以说是非常不错的了。但是这样做的代价同样很昂贵,ALBERT花了BERT3倍的时间才将模型训练至收敛。(因为毕竟网络被加宽加深,模型变得比BERT还要复杂,而这些新增的参数还是需要被更新,更何况这些参数还都是被refine共享过的,所以在计算上没有地方可以偷懒。一种典型的以时间换空间的做法)
3.3 ALBERT在其他细节上的优化
除了将BERT的体积大幅减少,ALBERT还针对BERT隐藏的一些缺点进行了修正。
3.3.1 SOP代替NSP
我们知道BERT的sentence-level实现的很重要的一点就是进行了NSP(Next Sentence Prediction)。其意图是为了训练模型对句子连续性的把握,但是对于负样本的采样,BERT的策略却是从整个语料库中随机抽取样本,这将会带来一个潜在的问题:网络很有可能学到句对间topic的判别,而不是句对连续性的把握。显然,前者的难度远低于后者,但是这并不是BERT的本意。这也就是为何在许多下游任务中,将NSP这个任务去掉,BERT产生的性能反而更好的原因。
ALBERT做出的一个很重要的改进就是强制让模型去辨别句对连续性,即SOP(Sentence Oder Prediction),而它采用的策略极其简单—负样本的获得,是通过正样本两个句对顺序的颠倒。看似简单的操作,却保障了负样本的两个句子是从属于同一个topic,而句序是明显错误的效果。
下图是SOP代替了NSP之后产生的效果:

可以看到SOP不管是在真正的SOP任务上,精度达到86.5%,同时对于真正的下游NSP任务,效果也不是很差,达到了78.9%(蓝色框)。但是NSP明显只能在NSP任务上取得high score(一方面也是因为这样的任务更简单)
3.3.2 去除MLM中的drop out
这个操作其实不难理解。可以从两个角度去解释:
- BERT的训练本就是基于大量的网络文本、书籍文献。从这个角度讲,BERT其实完全没有必要去担心over fitting.由于MLM本身就是一个非常有难度的任务(困难版完形),没必要再去添加噪声刁难它,只要拥有足够的算力,BERT理论上只会越学越好。
- MLM这个操作其实已经引入了很强的噪声(DAE LM),从这个角度看,drop out 也只是多此一举。
在去掉了drop out 之后,下游任务貌似只有轻微的提升:

但是它带来的内存上的优化却是十分明显的:

红色框圈起来的地方是去除drop out之前,可以明显看出其内存占用更高(每一个条纹宽度是去除drop out之后的三倍左右)。这也是可以解释的,因为drop out 会产生许多临时变量,而这些变量对于ALBERT来说是没有用处的。
4. Autoregressive vs Auto-encoding
前文已经将BERT、ALBERT的大致内容介绍了,为了介绍最后一个XLNet,必须先知道两个很重要的概念:Autoregressive 和 Auto-encoding。从XLNet的关注点,去分析这两大范式的优缺点。
4.1 定义
- Autoregressive(自回归模型):自回归是时间序列分析或者信号处理领域喜欢用的一个术语。可以直接理解成语言模型,即一种基于上文预测下文,或者基于下文预测上文的语言模型。典型的代表是GPT、ELMo.
- Auto-encoding(自编码模型):什么叫做自编码?说的通俗一点,其实就是一个自个儿和自个儿玩的模型(自己和自己下棋,自己和自己对唱…玩着玩着棋艺就变高了,玩着玩着唱功就变好了)。最开始自编码的提出是想要通过一个深度网络,对数据进行压缩成低纬,之后解压缩还原原始数据,目的为了获得输入数据的更加有效的表示。但是这样的一种模式非常适用于无监督的pre-training.
和CV不同,在NLP领域,我们不得不面对的一个问题就是我们有大量的数据,可是我们没有标注。正是由于这个原因,完全无监督预训练网络对于许多label稀少的下游任务来说十分重要,而Auto-encoding这种LM则正是NLP迁移学习的一个理想模型,就如本文开篇说的那样。而BERT就是Auto-encoding的一个典型代表。不仅如此,BERT采用了MLM,在输入层加入一定的噪音,是一种典型的DAE LM(Denoising Autoencoder)。
4.2 优缺点比较
- Autoregressive:自回归模型的一般形式可以用下面这幅图表示

自回归模型旨在利用序列的单向迭代,通过已知的上文信息Pθ(Xt | X
优点:
- training和fine-tuning具有一致性,天然匹配某些下游任务。(文本生成类,一个个往外面吐字的,如机器翻译、摘要…)
- 模型没有基于条件独立假设(目标函数中用的是"="符号,从概率的角度讲这个性质很好,这点需要和Auto-encoding进行对比)。
缺点:
-
- 无法实现同时双向(这点已经强调很多次了)
- Auto-encoding:自编码模型表示如下图
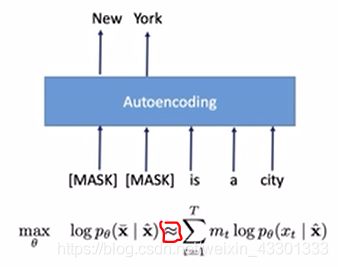
由于是DAE LM,因此在目标函数中加了一个mt,取值为[0,1],作用相当于对被Mask掉的单词的开关。
有人可能会注意到,这里的目标函数和Autoregressive不一样,很重要的一点是Auto-encoding的目标函数中间用的是约等于符号。这是因为等号右边式子的值并不服从product rule(条件概率的乘法法则),所以Auto-encoding模型具有独立性假设。
比方说上图,把句字New York is a city的New York给mask了,目标是预测被遮住的New York,即求得 P(New York|is a city) 并将其最大化(先不考虑log)。这里先把“is a city”当作是一个整体,把它用C代替,“New"和“York“分别用A、B表示。所以我们的目标就是max P(AB|C)。
为了计算这个联合概率,假设事件A和事件B是条件独立的,即P(AB|C)≈P(A|C)*P(B|C)
放到上面这个句子,也就是P(New York|is a city)≈P(New|is a city)*P(York|is a city)。但是很明显,对于"New”、"York"来说,离开了其中任何一个,另一个剩下的也失去了原本含义,因为本身这两个token是属于一个单词的。在遇到这种情况时,Auto-encoding的条件独立假设就会存在比较严重的问题,因为它强行将token之间原本可能存在的关联性给打破了。接下来列一下Auto-encoding的优缺点。
优点:
-
- 同时双向
缺点:
- 模型基于条件独立假设
- training和fine-tuning不一致(因为在训练过程中引入了特殊的掩码Mask,这是下游任务不存在的)
从这里可以发现,Autoregressive 和 Auto-encoding之间的优缺点刚好反一下,那么有没有一种模型,可以兼顾Autoregressive 和 Auto-encoding的优点呢?这也就是XLNet的诞生初衷。
5. XLNet–似乱非乱两相随
5.1 诞生初衷
在XLNet诞生之前,预训练方面存在着两大阵营,分别是以ELMo、GPT一众为代表的AR(Auto regressive) 和以BERT为首的 AE(Auto-encoding)。这两大阵营都存在着各自的优点和缺点,但是其优缺点大致上呈现一种互补关系。为了能够同时兼顾这两大范式的优点,19年Google brain结合了当时最先进的自回归模型Transformer-XL,提出了一种采用泛化自回归,克服BERT等自编码模型缺点的新模型—XLNet.
XLNet一出,BERT之前连战11项的巅峰记录被无情刷了下去。XLNet在20 个任务上超过了BERT的表现,并在18个任务上取得了当前最佳效果,其中包括了包括机器问答、自然语言推断、情感分析和文档排序。
那么XLNet到底是采用了什么方法进行AR与AE的融合的呢?
归根到底一句话:似乱非乱两相随
5.2 Permutation Language model–似乱非乱
XLNet采用的是自回归模型,同时运用了BERT引以为傲的MLM训练模式,即给定一个句子,将其中的一部分单词进行Mask,然后利用剩下的句子信息去还原被mask的单词。由于是采用自回归,BERT这种自编码模型的两个缺点:训练与下游不协调、独立性假设损失关联性, XLNet就可以很自然地避开。那么XLNet要解决的首要问题就是如何实现同时双向融合。
为了解决这个难题,XLNet想出了一个聪明的点子----Permutation Language model(乱序语言模型)。
5.2.1 直观理解
所谓乱序,道理很简单,就是把输入的句子进行全排列,每一种排列方式进行一次Mask预测,最后取所有全排列下的期望值。比方说现在输入的句子是:boy next door,把’next‘用Mask替换掉,如果不采用全排列,直接将输入喂给AR,也就是"boy [Mask] door",那么模型只能单向地提取到"boy"的信息。
而Permutation Language model要做的就是将上述的句子产生3!种排列情况:
boy [Mask] door
boy door [Mask]
[Mask] boy door
[Mask] door boy
door [Mask] boy
door boy [Mask]
对于每一种排列,单向地计算[Mask]位置的原词概率,计算的公式就是之前讲过的AR的product rule.

最后将6种排列的结果取一个期望,由于所有的排列情况都被考虑进去,在预测过程中,Mask的位置就已经获得了上下文的全部信息。
XLNet就是通过这种将输入顺序打乱重排的方法,来实现基于AR的同时双向。
当然,在实际训练的过程中,由于输入的长度会很大,因此计算所有排列情况实际上是不可行的,这会产生巨大的时间消耗。因此XLNet每次只在全排列中取一部分。
5.2.2 实现细节
在实现这个乱序采样的过程中,XLNet做的并不是真的将输入打乱顺序,而是采用了打乱order的方法。具体过程如下图:

ZT 表示所有order组成的集合。拿之前那个例子来说就是:
boy [Mask] door ---------【1,2,3】
boy door [Mask] --------【1,3,2】
[Mask] boy door----------【2,1,3】
[Mask] door boy-----------【2,3,1】
door [Mask] boy-----------【3,2,1】
door boy [Mask]---------【3,1,2】
ZT ={【1,2,3】、【1,3,2】、【2,1,3】、【2,3,1】、【3,2,1】、【3,1,2】}
而每次要做的,就是从ZT 中抽取一个order Z ,比方说 Z =【2,3,1】,然后用这个order去计算Mask位置的概率:P(boy door next)=P(boy)*P(door|boy)*P(next|boy door)
然后重复上述抽样过程。
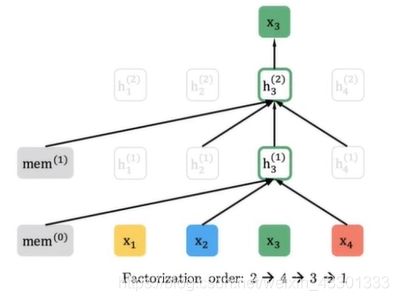
再详细一点,假如说现在输入有四个单词,被Mask的是3号位置的单词,我们可以看一下不同order下的不同处理。
如果现在随机抽到的order是【3,2,4,1】,那么这个过程就会像下图。由于现在的order里,3是第一个,所以它获取不到任何信息,因此计算 h3(1) 只会用到一个默认的cell–mem。

假设order是【2,4,3,1】,那么计算 h3(1) 将会需要2、4的信息:
【1,4,2,3】:

【4,3,1,2】:

所以可以看到,所谓的打乱并不会真的改变输入序列的顺序,只是将order随机打乱,再根据order去获得预测Mask需要考虑位置。因此可以说Permutation Language Model是 似乱非乱.
另外,XLNet在实现不同的order上采用的是 Attention Mask 矩阵,例如【3,2,4,1】,他的 Attention Mask 矩阵就是下面这幅图:

比方说现在要预测4,那么需要考虑的上文是3和2, Attention Mask 矩阵的第4行就只有2,3两列是1,其他地方是0;再比如要预测3,这个order下3前面没有任何信息,所以 Attention Mask 矩阵的第三行全为0.
5.3 Two-Stream Self-Attention–两相随
5.3.1 位置信息的丢失
到目前位置,我们可以看到,利用全排序的XLNet既解决了自编码模型的缺点,又能同时捕捉上下文信息。那么它是否已经是没有问题存在的了呢?答案是否定的。
5.3.1.1 standard parameterization
我们知道,标准的AR目标函数是长这幅样子的:

比方说:P(ABC)=P(A)*P(B|A)*P(C|AB)即product rule。这个式子其实可以简化成下面的这种形式:P(ABC)=hθ(A:B) * e(C)
hθ函数用于将A与B包含的信息经过线性转换融合为张量,e函数则将C也转换成张量的形式,即AB融合的张量与C张量做点积。因为 P(A)*P(B|A)*P(C|AB)的含义不就是在考虑A与B的条件下,计算C吗。所以可以通过这种转化为张量的方式,以hθ(A:B) 和 e( C )点积,得到两个张量的相近程度。这从逻辑上是可以解释的。
所以,上述AR的标准目标函数还可以转化成下面这种形式:

X1:t-1表示的是t位置之前的所有时间步,经过hθ转化为张量和e( C)点积。由于等式左边是概率,因此我们将点积结果经过softmax的归一化,变成概率的形式。
这样的标准形式存在的一个问题就是会导致位置信息的丢失。
比方说现在的输入是这样一个句子:
哈利 波特 是 一个 优秀的 魔法师
假设我们运气不好,Mask的时候"哈利"、"波特"两个字刚好都被遮住了。
[Mask] [Mask] 是 一个 优秀的 魔法师
随后我们按照XLNet的做法对order集合 ZT 进行抽样,我们运气又很差,抽到下面这个排列:
是 一个 优秀的 魔法师 [Mask] [Mask]
由于被预测的两个Mask都被排在最后两个字,因此在从左到右计算任何一个位置的Mask时,计算出来的"哈利"和"波特"概率结果是一模一样的(如果现在问你这两个Mask哪个是"哈利",你也不知道了,这就是乱序带来的问题)。
5.3.1.2 new parameterization
为了解决位置信息丢失的问题,XLNet在标准目标函数的基础上加了一个位置信息 Zt (区别于之前的order集合 ZT ),得到了新的目标函数:

所以这个位置信息 Zt 应该怎样结合到我们的输入里面去呢?
回忆一下BERT,BERT也会遇到有关于位置信息丢失的情况(我吃坏了'东西',得去拉'肚子' vs 我吃坏了'肚子',得去拉'东西'),而它采用的做法十分暴力,直接将position Embedding 和输入的Token Embedding直接拼接。那么是否在XLNet里也可以把位置信息(position Embedding)和内容信息(Token Embedding)直接结合呢?
假如说现在的order是【3,2,4,1】,如果我们想要去预测位置2(这里偷不到图,只能手画了…怕乱,所以只画了一部分)

由于2前面只有一个3,那么我们只需要获得3的信息,同时我们也需要获得2的位置信息,因此X2需要向高层仅传递位置信息,而不能透露有关于2的内容。也就是说现在面临的情况是:我们需要将位置信息和内容信息分开。
5.3.2 双流自注意力
正是由于需要将位置信息和内容信息分开,XLNet使用了一种叫做Two-Stream Self-Attention(双流自注意力)的方法。它将每个Transformer cell分为两个部分:
- content representation:包含了所有上下文信息(内容+位置)
- query representation:仅包含了当前的位置信息
所以还是之前的那个例子,现在的模型将会变成如下(画的丑了点,将就一下…):
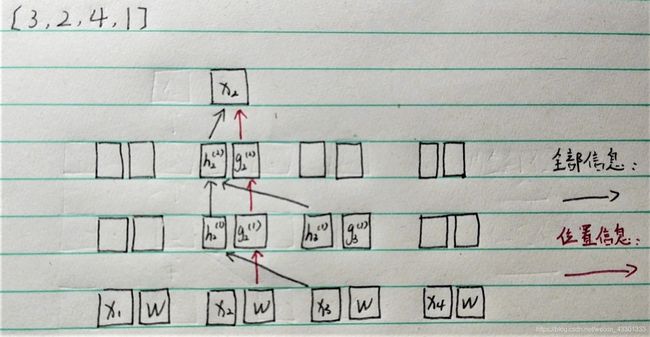
红色的路径表示位置信息的传播,黑色的是全部信息,可以看到实现双流自注意力之后,XLNet可以做到不向模型透露内容的前提下,加入有关于预测位置的位置信息。
5.3.2.1 K、Q、V的分流
上面为了简单,将每一个Transformer cell看作是两部分,实际上XLNet实现双流用到了之前讲到过的,self-Attention层的三个中间矩阵:WK、WQ、WV
为了实现双流自注意力,XLNet的做法是将Mask仅与 WQ 做点积,而将其与WK WV 完全隔绝。
这样的做法不难理解,因为之前讲过,Transformer的每一个输出 Z ,其内容来源是 V1:t ,通过将 V 与一个分数加权求和得到 Z , 而这个分数是来自Q K 的点积再经过归一得到的概率,以此分配每个 V 的权重。因此对于上层来说,V 是内容信息的组成,而 K 是分配注意力权重的依据。所以这两个信息自然不能混入有关Mask的内容。

比如上面这幅图,黑线代表全部信息,后面三个词的全部信息将会传给K与V;红线、蓝线分别代表位置和内容,第一个词仅内容信息传递给K、V,而其全部信息是作为查询向量传入Q的。
这种做法还有另一个好处,由于K、V无法获得有关于Mask的信息,使得BERT之前存在的与下游任务fine-tuning不一致的问题也得到了解决。因此这种做法也可以应用到BERT中。
5.3.2.2 数学上的表达
最后给出h、g函数的数学表达:
对于content representation而言,它和传统的Transformer一样,是包含了所有上下文信息的表示,计算公式如下:

对应使用的Attention mask矩阵:

而对于query representation,他的数学表达式:

对应的Attention mask矩阵:

可以看到,它的对角线是空的,因为每个位置只能包含当前位置信息。
到这里为止,有关于XLNet的主要内容也算是介绍好了,其实还有一部分关于Transformer-XL的细节这里没有提及,碍于篇幅暂且省略(其实是懒 )。具体细节如果还有不明白的可以参考下面这篇blog:
XLNet原理解读
有关于XLNet具体细节可以尝试阅读原论文:
XLNet: Generalized Autoregressive Pretraining for Language Understanding
6. 总结
我夜观天象,掐指一算,看到这里之人必定是骨骼精奇,若是给打通了任督二脉,还不得飞上天去
首先,能看到这里的说明朋友你耐心不错,还是想感谢一下的。这篇文章将近两万字,也花了自己一天一夜,中间没怎么休息。刚开始也想过把文章分成5篇,但是考虑到发文初衷就是为了能够把有关BERT的前因后果,往来始终串起来,若是打散,就失去了梳理、整合的初心。还是想通过这篇文章,一方面让自己做个总结,另一方面帮助到一些像我一样的小白。很多内容都是自己花了心思的,渴求能够把一些核心的思想直观通俗地表达出去。
有关于这些前沿的模型,光看blog是不够的,只有摸过论文、代码才能正真get好多细节。
另外,自己是初学,可能有很多地方理解或者描述地不到位的,还望指正。
2020-7-10凌晨更新
凌晨突然看到一条推送,chris(cs224n那个快乐的老爷爷)报告指出,BERT能够学到句法结构信息。他的团队通过将BERT吐出来的 contextual embedding投射到低维空间(为了避免特定语境造成的干扰),随后在这些低纬embedding上生成一棵最小生成树,发现这棵树的结构居然和人工句法分析标注的树形很相近(如下图)
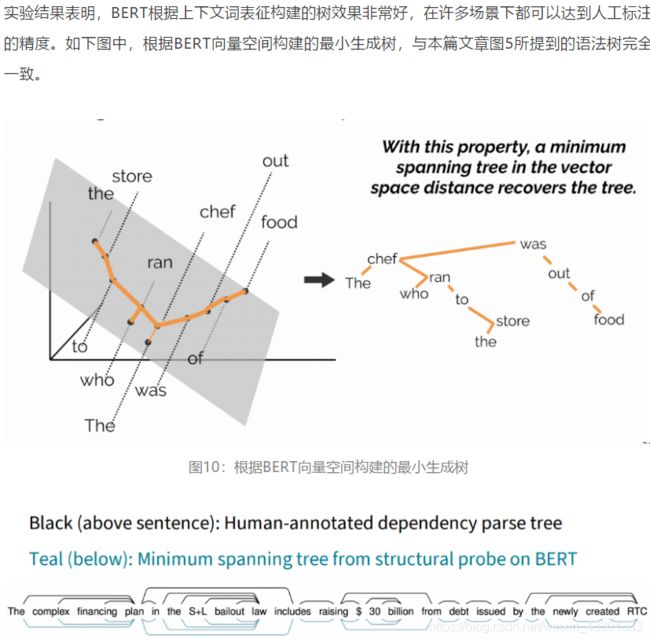
同时,通过对multi self-attention某些头的attention分数进行分析,他们也发现BERT某些头还能够学到依存句法和共指特征,而这些本就是我们人类期望LM能够学到的hand-crafted的语法特征,BERT成功学到了;这些很可能得益于他的自监督训练。(还是只能说明BERT那两个自监督训练太巧妙了,因为模型架构再复杂、巧妙只是提升了模型能够达到的上限,而预训练的任务则驱动模型达到他的最佳性能,帮助他触碰到他的上限)
参考资料
- The Illustrated BERT、EMLo and co
- 【NLP】彻底搞懂BERT
- 图解Transformer(完整版)
- 详解BERT阅读理解
- BERT的[CLS]有什么用
- bert系列二:《BERT》论文解读
- NLP:自回归(Autoregressive LM)与自编码语言模型(Autoencoder LM)
- 贪心科技NLP公开课程
- 关于BERT,面试官们都怎么问?
- 最通俗易懂的XLNET详解
- XLNet原理解读
- 斯坦福大学Christopher Manning:Transformer语言模型为什么能取得突破