seq2seq与Attention机制
学习目标
- 目标
- 掌握seq2seq模型特点
- 掌握集束搜索方式
- 掌握BLEU评估方法
- 掌握Attention机制
- 应用
- 应用Keras实现seq2seq对日期格式的翻译
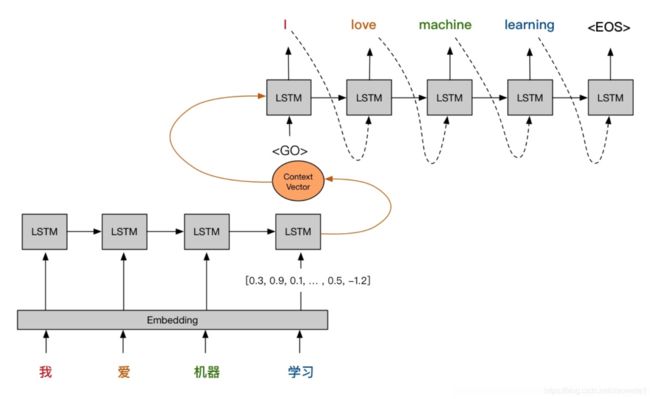
4.3.1 seq2seq
seq2seq模型是在2014年,是由Google Brain团队和Yoshua Bengio 两个团队各自独立的提出来。
4.3.1.1 定义
seq2seq是一个Encoder–Decoder 结构的网络,它的输入是一个序列,输出也是一个序列, Encoder 中将一个可变长度的信号序列变为固定长度的向量表达,Decoder 将这个固定长度的向量变成可变长度的目标的信号序列。

注:Cell可以用 RNN ,GRU,LSTM 等结构。
- 相当于将RNN模型当中的s^{0}s0输入变成一个encoder
4.3.1.2 条件语言模型理解
- 1、编解码器作用
- 编码器的作用是把一个不定长的输入序列x_{1},\ldots,x_{t}x1,…,xt,输出到一个编码状态CC
- 解码器输出y^{t}yt的条件概率将基于之前的输出序列y^{1}, y^{t-1}y1,yt−1和编码状态CC
argmax {P}(y_1, \ldots, y_{T'} \mid x_1, \ldots, x_T)argmaxP(y1,…,yT′∣x1,…,xT),给定输入的序列,使得输出序列的概率值最大。
- 2、根据最大似然估计,最大化输出序列的概率
{P}(y_1, \ldots, y_{T'} \mid x_1, \ldots, x_T) = \prod_{t'=1}^{T'} {P}(y_{t'} \mid y_1, \ldots, y_{t'-1}, x_1, \ldots, x_T) = \prod_{t'=1}^{T'} {P}(y_{t'} \mid y_1, \ldots, y_{t'-1}, {C})P(y1,…,yT′∣x1,…,xT)=∏t′=1T′P(yt′∣y1,…,yt′−1,x1,…,xT)=∏t′=1T′P(yt′∣y1,…,yt′−1,C)
由于这个公式需要求出:P(y^{1}|C) * P(y^{2}|y^{1},C)*P(y^{3}|y^{2},y^{2},y^{1},C)...P(y1∣C)∗P(y2∣y1,C)∗P(y3∣y2,y2,y1,C)...这个概率连乘会非常非常小不利于计算存储,所以需要对公式取对数计算:
\log{P}(y_1, \ldots, y_{T'} \mid x_1, \ldots, x_T) = \sum_{t'=1}^{T'} \log{P}(y_{t'} \mid y_1, \ldots, y_{t'-1}, {C})logP(y1,…,yT′∣x1,…,xT)=∑t′=1T′logP(yt′∣y1,…,yt′−1,C)
所以这样就变成了P(y^{1}|C)+ P(y^{2}|y^{1},C)+P(y^{3}|y^{2},y^{2},y^{1},C)...P(y1∣C)+P(y2∣y1,C)+P(y3∣y2,y2,y1,C)...概率相加。这样也可以看成输出结果通过softmax就变成了概率最大,而损失最小的问题,输出序列损失最小化。
4.3.1.3 应用场景
- 神经机器翻译(NMT)
- 聊天机器人
接下来我们来看注意力机制,那么普通的seq2seq会面临什么样的问题?
4.3.2 注意力机制
4.3.2.1 长句子问题

对于更长的句子,seq2seq就显得力不从心了,无法做到准确的翻译,一下是通常BLEU的分数随着句子的长度变化,可以看到句子非常长的时候,分数就很低。

本质原因:在Encoder-Decoder结构中,Encoder把所有的输入序列都编码成一个统一的语义特征CC再解码,因此, CC中必须包含原始序列中的所有信息,它的长度就成了限制模型性能的瓶颈。当要翻译的句子较长时,一个CC可能存不下那么多信息,就会造成翻译精度的下降。
4.3.2.2 定义
- 建立Encoder的隐层状态输出到Decoder对应输出y所需要的上下文信息
- 目的:增加编码器信息输入到解码器中相同时刻的联系,其它时刻信息减弱

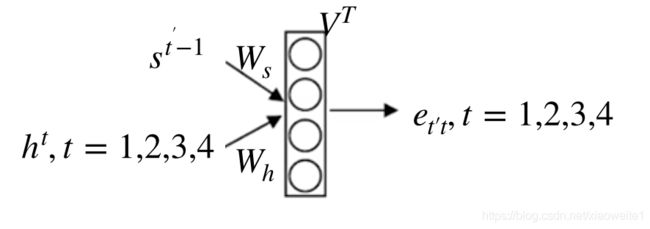
4.3.2.3 公式
注意上述的几个细节,颜色的连接深浅不一样,假设Encoder的时刻记为tt,而Decoder的时刻记为t^{'}t′。
-
1、{c}_{t'} = \sum_{t=1}^T \alpha_{t' t}{h}_tct′=∑t=1Tαt′tht
- \alpha_{t^{'}t}αt′t为参数,在网络中训练得到
- 理解:蓝色的解码器中的cell举例子
- \alpha_{4}{1}h_{1}+\alpha_{4}{2}h_{2} + \alpha_{4}{3}h_{3} + \alpha_{4}{4}h_{4} = c_{4}α41h1+α42h2+α43h3+α44h4=c4
-
2、\alpha_{t^{'}t}αt′t的N个权重系数由来?
- 权重系数通过softmax计算:\alpha_{t' t} = \frac{\exp(e_{t' t})}{ \sum_{k=1}^T \exp(e_{t' k}) },\quad t=1,\ldots,Tαt′t=∑k=1Texp(et′k)exp(et′t),t=1,…,T
- e_{t' t} = g({s}_{t' - 1}, {h}_t)= {v}^\top \tanh({W}_s {s} + {W}_h {h})et′t=g(st′−1,ht)=v⊤tanh(Wss+Whh)
- e_{t' t}et′t是由t时刻的编码器隐层状态输出和解码器t^{'}-1t′−1时刻的隐层状态输出计算出来的
- ss为解码器隐层状态输出,hh为编码器隐层状态输出
- v,W_{s},W_{h}v,Ws,Wh都是网络学习的参数
4.3.3 机器翻译案例
4.3.3.1 问题
使用简单的“日期转换”任务代替翻译任务,为了不然训练时间变得太长。
网络将输入以各种可能格式(例如“1958年8月29日”,“03/30/1968”,“1987年6月24日”)编写的日期,并将其翻译成标准化的机器可读日期(例如“1958 -08-29“,”1968-03-30“,”1987-06-24“)。使用seq2seq网络学习以通用机器可读格式YYYY-MM-DD输出日期。
4.3.3.2 相关环境与结果演示
pip install faker
pip install tqdm
pip install babel
pip install keras==2.2.4
- faker:生成数据包
- tqdm:python扩展包
- babel:代码装换器
- keras:更加方便简洁的深度学习库
- 为了快速编写代码
4.3.3.4 代码分析
-
Seq2seq():
- 序列模型类
- load_data(self,m):加载数据类,选择加载多少条数据
- init_seq2seq(self):初始化模型,需要自定义自己的模型
- self.get_encoder(self):定义编码器
- self.get_decoder(self):定义解码器
- self.get_attention(self):定义注意力机制
- self.get_output_layer(self):定义解码器输出层
- model(self):定义模型整体输入输出逻辑
- train(self, X_onehot, Y_onehot):训练模型
- test(self):测试模型
-
训练
if __name__ == '__main__':
s2s = Seq2seq()
X_onehot, Y_onehot = s2s.load_data(10000)
s2s.init_seq2seq()
s2s.train(X_onehot, Y_onehot)
整个数据集特征值的形状: (10000, 30, 37)
整个数据集目标值的形状: (10000, 10, 11)
查看第一条数据集格式:特征值:9 may 1998, 目标值: 1998-05-09
[12 0 24 13 34 0 4 12 12 11 36 36 36 36 36 36 36 36 36 36 36 36 36 36
36 36 36 36 36 36] [ 2 10 10 9 0 1 6 0 1 10]
one_hot编码: [[0. 0. 0. ... 0. 0. 0.]
[1. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
...
[0. 0. 0. ... 0. 0. 1.]
[0. 0. 0. ... 0. 0. 1.]
[0. 0. 0. ... 0. 0. 1.]] [[0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0.]
[1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
[1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]]
Epoch 1/1
100/10000 [..............................] - ETA: 10:52 - loss: 23.9884 - dense_1_loss: 2.3992 - dense_1_acc: 0.3200 - dense_1_acc_1: 0.0000e+00 - dense_1_acc_2: 0.0100 - dense_1_acc_3: 0.1300 - dense_1_acc_4: 0.0000e+00 - dense_1_acc_5: 0.0400 - dense_1_acc_6: 0.0900 - dense_1_acc_7: 0.0000e+00 - dense_1_acc_8: 0.3500 - dense_1_acc_9: 0.1100
200/10000 [..............................] - ETA: 5:27 - loss: 23.9289 - dense_1_loss: 2.3991 - dense_1_acc: 0.2550 - dense_1_acc_1: 0.0000e+00 - dense_1_acc_2: 0.0050 - dense_1_acc_3: 0.1150 - dense_1_acc_4: 0.0950 - dense_1_acc_5: 0.0250 - dense_1_acc_6: 0.1150 - dense_1_acc_7: 0.0800 - dense_1_acc_8: 0.3400 - dense_1_acc_9: 0.1050
- 测试
if __name__ == '__main__':
s2s = Seq2seq()
X_onehot, Y_onehot = s2s.load_data(10000)
s2s.init_seq2seq()
s2s.train(X_onehot, Y_onehot)
# s2s.test()
source: 1 March 2001
output: 2001-03-01
4.3.3.5 代码编写
- 1、模型一些参数确定
def __init__(self, Tx=30, Ty=10, n_x=32, n_y=64):
# 定义网络的相关参数
self.model_param = {
"Tx": Tx, # 定义encoder序列最大长度
"Ty": Ty, # decoder序列最大长度
"n_x": n_x, # encoder的隐层输出值大小
"n_y": n_y # decoder的隐层输出值大小和cell输出值大小
}
对于加载数据来说,我们不需要去进行编写逻辑了,看一下大概的逻辑.
- 2、加载数据
- 加载的代码逻辑在nmt_utils当中
- from nmt_utils import *
- 加载的代码逻辑在nmt_utils当中
添加一些参数到model_param中
# 添加特征词个不重复个数以及目标词的不重复个数
self.model_param["x_vocab"] = x_vocab
self.model_param["y_vocab"] = y_vocab
self.model_param["x_vocab_size"] = len(x_vocab)
self.model_param["y_vocab_size"] = len(y_vocab)
我们先看整个训练的逻辑,并从中来实现整个模型的定义,计算逻辑
dataset:[('9 may 1998', '1998-05-09'), ('10.09.70', '1970-09-10')]
x_vocab:翻译前的格式对应数字{' ': 0, '.': 1, '/': 2, '0': 3, '1': 4, '2': 5, '3': 6, '4': 7,...........}
y_vocab:翻译后的格式对应数字{'-': 0, '0': 1, '1': 2, '2': 3, '3': 4, '4': 5, '5': 6, '6': 7, '7': 8, '8': 9, '9': 10}
# 添加特征词个不重复个数以及目标词的不重复个数
self.model_param["x_vocab"] = x_vocab
self.model_param["y_vocab"] = y_vocab
self.model_param["x_vocab_size"] = len(x_vocab)
self.model_param["y_vocab_size"] = len(y_vocab)
-
3、训练步骤
-
- (1)定义好网络的输入输出格式
- (2)定义好优化器(选择Adam,参数lr=0.005, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.001)
- from keras.optimizers import Adam
- model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
- (3)模型训练,
- model.fit(inputs, outputs, epochs=1,batch_size=100)
def train(self, X_onehot, Y_onehot):
"""
训练
:param X_onehot: 特征值的one_hot编码
:param Y_onehot: 目标值的one_hot编码
:return:
"""
# 利用网络结构定义好模型输入输出
model = self.model()
opt = Adam(lr=0.005, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.001)
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
s0 = np.zeros((10000, self.model_param["n_y"]))
c0 = np.zeros((10000, self.model_param["n_y"]))
outputs = list(Y_onehot.swapaxes(0, 1))
# 输入x,以及decoder中LSTM的两个初始化值
model.fit([X_onehot, s0, c0], outputs, epochs=1, batch_size=100)
return None
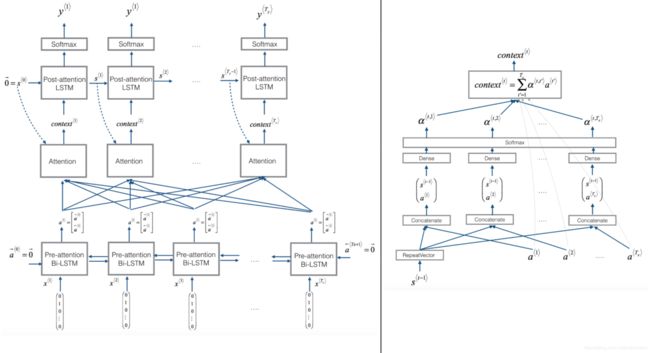
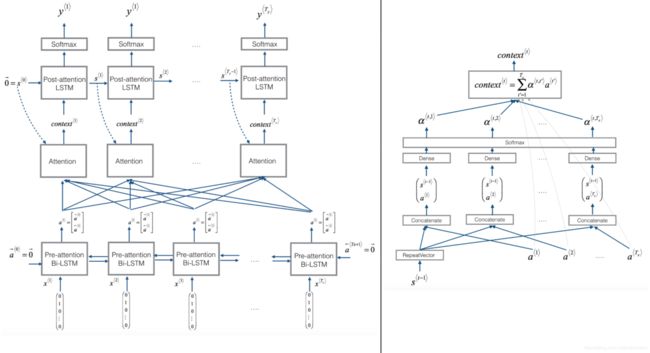
- (1)定义网络好的输入到输出流程
- 步骤1、定义模型的输入
- 步骤2:使用encoder的双向LSTM结构得输出a
- 步骤3:循环decoder的Ty次序列输入,获取decoder最后输出
- 1: 定义decoder第t'时刻的注意力结构并输出context
- context = self.computer_one_attention(a, s)(需要实现Attention结构的计算过程)
- 2: 对"context" 和初始两个状态s0,c0输入到deocder当中,返回两个输出
- s, _, c = self.decoder(context, initial_state=[s, c])
- 3: 应用 Dense layere获取deocder的t'时刻的输出 out = self.output_layer(s)
- 1: 定义decoder第t'时刻的注意力结构并输出context
- 步骤 4: 创建model实例,定义输入输出
- from keras.models import Model
def model(self):
"""
定义模型获取模型实例
:param model_param: 网络的相关参数
:param seq2seq:网络结构
:return: model,Keras model instance
"""
# 步骤1、定义模型的输入
# 定义decoder中隐层初始状态值s0以及cell输出c0
X = Input(shape=(self.model_param["Tx"], self.model_param["x_vocab_size"]), name='X')
# 定义deocder初始化状态
s0 = Input(shape=(self.model_param["n_y"],), name='s0')
c0 = Input(shape=(self.model_param["n_y"],), name='c0')
s = s0
c = c0
# 定义装有输出值的列表
outputs = []
# 步骤2:使用encoder的双向LSTM结构得输出a
a = self.encoder(X)
# 步骤3:循环decoder的Ty次序列输入,获取decoder最后输出
# 包括计算Attention输出
for t in range(self.model_param["Ty"]):
# 1: 定义decoder第t'时刻的注意力结构并输出context
context = self.computer_one_attention(a, s)
# 2: 对"context" vector输入到deocder当中
# 获取cell的两个输出隐层状态和,initial_state= [previous hidden state, previous cell state]
s, _, c = self.decoder(context, initial_state=[s, c])
# 3: 应用 Dense layere获取deocder的t'时刻的输出
out = self.output_layer(s)
# 4: 将decoder中t'时刻的输出装入列表
outputs.append(out)
# 步骤 4: 创建model实例,定义输入输出
model = Model(inputs=(X, s0, c0), outputs=outputs)
return model
- 3、模型初始化模型结构定义
- 在训练中有一些模型结构,所以现需要定义这些结构统一初始化,这些模型结构作为整个Seq2Seq类的属性,初始化逻辑。
def init_seq2seq(self):
"""
初始化网络结构
:return:
"""
# 添加encoder属性
self.get_encoder()
# 添加decoder属性
self.get_decoder()
# 添加attention属性
self.get_attention()
# 添加get_output_layer属性
self.get_output_layer()
return None
- 定义编解码器、Attention机制、输出层
Keras是一个高级神经网络API,用Python编写,能够在TensorFlow之上运行。它的开发重点是实现快速实验。能够以最小的延迟从想法到结果是进行良好研究的关键。
如果您需要深度学习库,请使用Keras:允许简单快速的原型设计(通过用户友好性,模块化和可扩展性)
- 编码器
- 编码器:使用双向LSTM(隐层传递有双向值传递)
- from keras.layers import LSTM, Bidirectional
- LSTM(units, return_sequences=False,name="")
- units: 正整数, units状态输出的维度
- return_sequences:布尔类型 是否返回输出序列
- return:LSTM layer
- Bidirectional(layer, merge_mode='concat')
- 对RNN、LSTM进行双向装饰
- layer:RNN layer或者LSTM layer
- merge_mode:将RNN/LSTM的前向和后向输出值进行合并
- {'sum', 'mul', 'concat', 'ave', None}
def get_encoder(self):
"""
定义编码器结构
:return:
"""
# 指定隐层值输出的大小
self.encoder = Bidirectional(LSTM(self.model_param["n_x"], return_sequences=True, name='bidirectional_1'), merge_mode='concat')
return None
- 解码器
- return_state: 布尔,是否返回输出以及状态值
- if return_state: 第一个值是output. 后面的值是状态值shape 为 (batch_size, units).
- return_state: 布尔,是否返回输出以及状态值
def get_decoder(self):
"""
定义解码器结构
:return:
"""
# 定义decoder结构,指定隐层值的形状大小,return_state=True
self.decoder = LSTM(self.model_param["n_y"], return_state=True)
return None
- 输出层
- from keras.layer import Dense
- 指定一个普通的全连接层,并且可以指定激活函数
- Dense(units, activation=None)
- 神经元个数(输出大小)
- activation=None:激活函数
def get_output_layer(self):
"""
定义输出层
:return: output_layer
"""
# 对decoder输出进行softmax,输出向量大小为y_vocab大小
self.output_layer = Dense(self.model_param["y_vocab_size"], activation=softmax)
return None
- computer_one_attention函数实现:attention层结构
- 1、定义结构
- 2、实现输入输出结果
- \alpha_{t' t} = \frac{\exp(e_{t' t})}{ \sum_{k=1}^T \exp(e_{t' k}) },\quad t=1,\ldots,Tαt′t=∑k=1Texp(et′k)exp(et′t),t=1,…,T
- e_{t' t} = g({s}_{t' - 1}, {h}_t)= {v}^\top \tanh({W}_s {s} + {W}_h {h})et′t=g(st′−1,ht)=v⊤tanh(Wss+Whh)
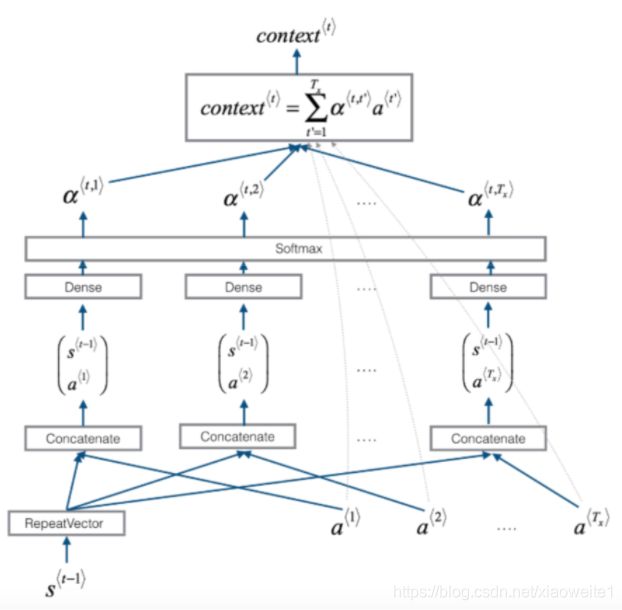
- from keras.layers import RepeatVector, Concatenate, Dot, Activation
def get_attention(self):
"""
定义Attention的结构
:return: attention结构
"""
# 定义RepeatVector复制成多个维度
repeator = RepeatVector(self.model_param["Tx"])
# 进行矩阵拼接
concatenator = Concatenate(axis=-1)
# 进行全连接层10个神经元
densor1 = Dense(10, activation="tanh", name='Dense1')
# 接着relu函数
densor2 = Dense(1, activation="relu", name='Dense2')
# softmax
activator = Activation(softmax,
name='attention_weights')
# context计算
dotor = Dot(axes=1)
# 将结构存储在attention当中
self.attention = {
"repeator": repeator,
"concatenator": concatenator,
"densor1": densor1,
"densor2": densor2,
"activator": activator,
"dotor": dotor
}
return None
- Attention输入输出逻辑
- 使用Attention结构去实现输入到输出的逻辑
def computer_one_attention(self, a, s_prev):
"""
利用定义好的attention结构计算中的alpha系数与a对应输出
:param a:隐层状态值 (m, Tx, 2*n_a)
:param s_prev: LSTM的初始隐层状态值, 形状(sample, n_s)
:return: context
"""
# 使用repeator扩大数据s_prev的维度为(sample, Tx, n_y),这样可以与a进行合并
s_prev = self.attention["repeator"](s_prev)
# 将a和s_prev 按照最后一个维度进行合并计算
concat = self.attention["concatenator"]([a, s_prev])
# 使用densor1全连接层网络计算出e
e = self.attention["densor1"](concat)
# 使用densor2增加relu激活函数计算
energies = self.attention["densor2"](e)
# 使用"activator"的softmax函数计算权重"alphas"
# 这样一个attention的系数计算完成
alphas = self.attention["activator"](energies)
# 使用dotor,矩阵乘法,将 "alphas" and "a" 去计算context/c
context = self.attention["dotor"]([alphas, a])
return context
- 4、测试逻辑
- model.load_weights(path):加载模型
def test(self):
"""
测试
:return:
"""
model = self.model()
model.load_weights("./models/model.h5")
example = '1 March 2001'
source = string_to_int(example, self.model_param["Tx"], self.model_param["x_vocab"])
source = np.expand_dims(np.array(list(map(lambda x:
to_categorical(x, num_classes=self.model_param["x_vocab_size"]),
source))), axis=0)
s0 = np.zeros((10000, self.model_param["n_y"]))
c0 = np.zeros((10000, self.model_param["n_y"]))
prediction = model.predict([source, s0, c0])
prediction = np.argmax(prediction, axis=-1)
output = [dict(zip(self.model_param["y_vocab"].values(), self.model_param["y_vocab"].keys()))[int(i)] for i in prediction]
print("source:", example)
print("output:", ''.join(output))
return None
4.3.4 集束搜索(Beam Search)
4.3.4.1 问题引入
我们在找到一个合适的句子的时候,一个很直观的方法是在生成第一个词y^{1}y1分布之后,根据条件语言模型挑选出最有可能的第一个词y^{1}y1 ,然后生成第二个词y^{2}y2的概率分布挑选第二个词y^{2}y2,依此类推,始终是选择每一个最大概率的词,这种方法在机器翻译领域其实并不管用,我们来举个例子
法语句子"Jane visite l'Afrique en septembre."
翻译1-Jane is visiting Africa in September.
翻译2-Jane is going to be visiting Africa in September.
翻译1显然比翻译2要更好,更加简洁的表达了意思。
如果该算法挑选了 y^{1},y^{2}y1,y2, ('Jane' , 'is'),那么在英语中"is going"更加常见,因此在选择 y^{3}y3 ='going',于是对于合适的句法来说"Jane is visiting"相比"Jane is going"会有更高的概率使用,所以有时候真正需要的是一次性挑选整个单词序列y^{1},y^{2},y^{3},...,y^{t}y1,y2,y3,...,yt 使得整体的条件概率最大。
4.3.4.2 集束搜索流程
- 定义:在Beam Search中有一个参数B,叫做beam width(集束宽),用来表示在每一次筛选时挑top B的结果。
例子说明:

- 第一次:选出概率最大的三个词
- 第二次:选择上一步三个词,每个词对应三个概率最大的词(可能存在重复)
- ....
假设只有两步,那么得到9个结果。最终我们要从中选出三组结果
- is fine
- in alright
- at alright
那么这三个句子就是我们需要的结果。
4.3.5 BLEU-机器翻译的自动评估方法
对于上述筛选的结果我们可以让一些语言专家进行评估选出最合适的。当然有大量人力也是可以这样去做,但是我们希望系统能够自动选择一个最合适的翻译句子。需要提供两个
- 1、衡量机器翻译结果越接近人工翻译结果的数值指标
- 2、一套人工翻译的高质量参考译文
4.3.5.1 定义
BLEU的全名为:bilingual evaluation understudy(双语互译质量评估辅助工具),它是用来评估机器翻译质量的工具。
- 判断两个句子的相似程度
4.3.5.2 N-gram Precision(多元精度得分)方法
- N-gram Precision(多元精度得分)
这里的N是什么意思,我们通过一个例子来理解一下。
候选翻译: the the the the the the the
参考翻译: the cat is on the mat
参考翻译: there is a cat on the mat
两个句子,S1和S2,S1里头的词出现在S2里头越多,就说明这两个句子越一致。记做\frac{number1}{number2}number2number1。上面例子,候选翻译的词7个词the都在参考翻译中出现,记做分子得分7,候选翻译一共就7个词,分母为7。7/7=1,该候选翻译显然不行!!这个时候N=1,选出一个词
- 改进
- 原因:常用词干扰、选词的粒度太小(the)
- 使用N-gram,多元词组:{“the cat”, “cat is”, “is on”, “on the”, “the mat”}
1、同样还是一个词的时候的改进
- 过滤常见词(the on is ...so on)
- 公式计算(分子)
- Count_{w_i,j}^{clip} = min(Count_{w_i},Ref_{j}\_Count_{w_i})Countwi,jclip=min(Countwi,Refj_Countwi)
- 统计候选区域
- Count_{w_i}Countwi:候选翻译中单词w_iwi出现过的个数,如上表就是对“the”的计数为7
- Ref_{j}\_Count_{w_i}Refj_Countwi:词w_iwi在第个jj参考翻译里出现的次数
- {Count}^{clip} = max(Count_{w_i,j}^{clip}), i=1,2,{...}Countclip=max(Countwi,jclip),i=1,2,...
- 作用:选出候选翻译在参考翻译中最大的计数
- Count_{w_i,j}^{clip}Countwi,jclip:第jj个参考翻译,w_{i}wi计数
- Count^{clip}Countclip:在所有参考翻译中的w_iwi综合计数
- Count_{w_i,j}^{clip} = min(Count_{w_i},Ref_{j}\_Count_{w_i})Countwi,jclip=min(Countwi,Refj_Countwi)
仍然以上面的例子来看:Ref_{1}\_Count_{'the'}=2Ref1_Count′the′=2,则Count_{'the',1}^{clip}=min(7,2)=2Count′the′,1clip=min(7,2)=2,Count_{'the',2}^{clip}=1Count′the′,2clip=1,所以综合计数为Count^{clip}=max(1,2)=2Countclip=max(1,2)=2,分母不变,仍是候选句子的n-gram个数。这里分母为7。得分P = 2/7=0.28
2、多个改进的多元精度(modified n-gram precision)进行组合
n-gram下的可以衡量翻译的流程性,当我们对不同尺度的词进行统计出来,计算精度的时候,结果为

随着n-gram的增大,精度得分总体上成指数下降的。采取几何加权平均,并且将各n-gram的作用视为等重要的,即取权重服从均匀分布:p_{ave}=\sqrt[\sum_{n=1}^{N}w_{n}]{\prod_{n=1}^Np_{n}^{w_{n}}}=\frac{1}{\sum_{n=1}^{N}w_{n}}exp(\sum_{i=1}^{N}w_{n}*log^{p_{n}})=exp(\frac{1}{N}*\sum_{i=1}^{N}log^{p_{n}})pave=∑n=1Nwn√∏n=1Npnwn=∑n=1Nwn1exp(∑i=1Nwn∗logpn)=exp(N1∗∑i=1Nlogpn)
上面图的理解就为:p_{ave}=exp(\frac{1}{4}*(log^{p_{1}}+log^{p_{2}}+log^{p_{3}}+log^{p_{4}}))pave=exp(41∗(logp1+logp2+logp3+logp4))
3、进行短句惩罚
候选翻译: the cat
参考翻译: the cat is on the mat
参考翻译: there is a cat on the mat
这样就很容易的高分,所以就需要一个有效的乘惩罚机制。我们设c为候选翻译,r为参考翻译。则有下面的公式
BP=\lbrace^{1,ifc>r}_{e^{1-\frac{r}{c}},ifc \leq r}BP={e1−cr,ifc≤r1,ifc>r
4、最终BLEU值得计算公式
BLEU=BP*exp(\sum_{n=1}^{N}w_{n}*log^{p_{n}})BLEU=BP∗exp(∑n=1Nwn∗logpn)
4.3.6 总结
- 掌握seq2seq模型特点
- 掌握集束搜索方式
- 掌握BLEU评估方法
- 掌握Attention机制