Mac电脑安装Mangodb数据库,实现一个简单的Python页面爬虫
Mangodb百度百科
使用Mac电脑有很多的软件没有Mac版本导致软件无法安装,但是有的软件有mac版本,安装方式也比Windows平台复杂。比如现在我们想在Mac电脑安装mangodb数据库,首先我们需要安装Mangodb服务端。
下面我们就来Mongodb:mac 安装和使用MongoDB。根据操作步骤安装之后却报错了:
MacBook-Pro:~ guotianhui$ mongod
2019-08-01T13:32:13.194+0800 I CONTROL [main] Automatically disabling TLS 1.0, to force-enable TLS 1.0 specify --sslDisabledProtocols 'none'
2019-08-01T13:32:13.255+0800 I CONTROL [initandlisten] MongoDB starting : pid=2855 port=27017 dbpath=/data/db 64-bit host=MacBook-Pro.local
2019-08-01T13:32:13.255+0800 I CONTROL [initandlisten] db version v4.0.11
2019-08-01T13:32:13.255+0800 I CONTROL [initandlisten] git version: 417d1a712e9f040d54beca8e4943edce218e9a8c
2019-08-01T13:32:13.255+0800 I CONTROL [initandlisten] allocator: system
2019-08-01T13:32:13.255+0800 I CONTROL [initandlisten] modules: none
2019-08-01T13:32:13.255+0800 I CONTROL [initandlisten] build environment:
2019-08-01T13:32:13.255+0800 I CONTROL [initandlisten] distarch: x86_64
2019-08-01T13:32:13.255+0800 I CONTROL [initandlisten] target_arch: x86_64
2019-08-01T13:32:13.256+0800 I CONTROL [initandlisten] options: {}
2019-08-01T13:32:13.259+0800 I STORAGE [initandlisten] exception in initAndListen: IllegalOperation: Attempted to create a lock file on a read-only directory: /data/db, terminating
2019-08-01T13:32:13.259+0800 I NETWORK [initandlisten] shutdown: going to close listening sockets...
2019-08-01T13:32:13.260+0800 I NETWORK [initandlisten] removing socket file: /tmp/mongodb-27017.sock
2019-08-01T13:32:13.260+0800 I CONTROL [initandlisten] now exiting
2019-08-01T13:32:13.260+0800 I CONTROL [initandlisten] shutting down with code:100
百度以下是因为没有授权导致的创建数据库失败了,通过下面的命令来进行创建Mangodb数据库进行授权:
sudo chmod 777 /data/db
授权需要输入mac管理员密码,然后再开启mongodb服务端就可以成功了。
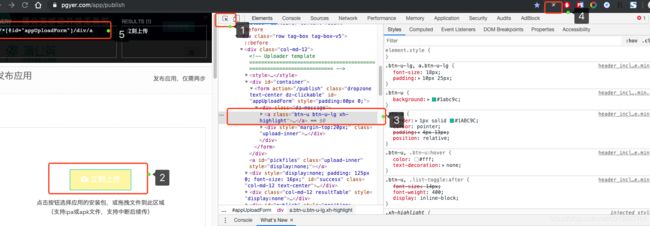
在浏览器输入下面这个地址http://localhost:27017/,如果显示下面的界面就说明你的Mongodb服务端已经安装成功了。
 下面就需要安装Robomongo客户端,也就是mongoGUI界面端,下载Robomongo需要链接外网地址。
下面就需要安装Robomongo客户端,也就是mongoGUI界面端,下载Robomongo需要链接外网地址。
下载之后一键安装,然后链接本地的数据库就可以关联Mongodb服务端了。
到这里就把Mac版本的Mangodb安装好了。
使用以下Python命令创建一个py爬虫:
Scrapy 命令
创建一个项目
scrapy startproject XXX
打开项目创建一个爬虫
scrapy genspider XXX xxx.com
在项目目录创建一个脚本启动程序
from scrapy.cmdlineimport execute
execute("scrapy crawl lianjia".split())
比如我们新建一个Py爬虫项目,然后在Terminal命令行运行下面命令:
scrapy startproject testSpider
就会发现在项目的根目录下创建了一个爬虫项目:

然后我们需要进入这个爬虫项目的根目录,然后使用下面的命令在项目的根目录下创建一个针对某个网址的爬虫:
cd testSpider
scrapy genspider baidu baidu.com
然后我们通过在项目的根目录下创建一个启动爬虫的脚本:
from scrapy.cmdline import execute
execute("scrapy crawl testSpider".split())
爬虫配置
需要更改项目settings.py配置:
1)第19行,打开之后配置成你系统浏览器的USER_AGENT,这里不配置的话会被默认是机器人访问。
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
2)第22行,打开,设置为False.
ROBOTSTXT_OBEY = False
3)设置执行间隔:
DOWNLOAD_DELAY = 1
4)第67行,设置数据库存储类配置:
ITEM_PIPELINES = {
'testSpider.pipelines.MysqlPipeline': 300,
}
这里使用了Mongodb进行存储,所以对应的存储类pipelines.py需要改成同一个类名。
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
from pymysql import connect
class MongoPipeline(object):
def open_spider(self, spider):
self.client = pymongo.MongoClient()
def process_item(self, item, spider):
self.client.room.lianjia.insert(item)
return item
def close_spider(self, spider):
self.client.close()
class MysqlPipeline(object):
def open_spider(self, spider):
self.client = connect(host="localhost", prot=3306, user="root", password="123456", db="room", charset="utf8")
self.cursor = self.client.cursor()
def process_item(self, item, spider):
args=[]
return item
def close_spider(self, spider):
self.cursor.close()
self.client.close()
这些都配置好以后就可以开始些数据解析类,也就是你的Spider数据解析类:
# -*- coding: utf-8 -*-
import scrapy
class LianjiaSpider(scrapy.Spider):
name = 'lianjia'
allowed_domains = ['lianjia.com']
start_urls = ['https://bj.lianjia.com/ershoufang/pg{}/'.format(num) for num in range(1, 2)]
def parse(self, response):
urls = response.xpath('//div[@class="info clear"]/div[@class="title"]/a/@href').extract()
for url in urls:
yield scrapy.Request(url, callback=self.parse_info)
def parse_info(self, response):
total = response.xpath(
'concat(//span[@class="total"]/text(),//span[@class="unit"]/span/text())').extract_first()
unitPriceValue = response.xpath('string(//span[@class="unitPriceValue"])').extract_first()
xiao_qu = response.xpath('//div[@class="communityName"]/a[1]/text()').extract_first()
qu_yu = response.xpath('string(//div[@class="areaName"]/span[@class="info"])').extract_first()
base = response.xpath('//div[@class="base"]//ul')
hu_xing = base.xpath('./li[1]/text()').extract_first()
lou_ceng = base.xpath('./li[2]/text()').extract_first()
mian_ji = base.xpath('./li[3]/text()').extract_first()
zhuang_xiu = base.xpath('./li[9]/text()').extract_first()
gong_nuan = base.xpath('./li[last()-2]/text()').extract_first()
chan_quan = base.xpath('./li[last()]/text()').extract_first()
transaction = response.xpath('//div[@class="transaction"]//ul')
yong_tu = transaction.xpath('./li[4]/span[2]/text()').extract_first()
nian_xian = transaction.xpath('./li[last()-3]/span[2]/text()').extract_first()
di_ya = response.xpath('string(//*[@id="introduction"]/div/div/div[2]/div[2]/ul/li[7]/span[2])').extract_first()
yield {
"total": total,
"unitPriceValue": unitPriceValue,
"xiao_qu": xiao_qu,
"qu_yu": qu_yu,
"hu_xing": hu_xing,
"lou_ceng": lou_ceng,
"mian_ji": mian_ji,
"zhuang_xiu": zhuang_xiu,
"gong_nuan": gong_nuan,
"chan_quan": chan_quan,
"yong_tu": yong_tu,
"nian_xian": nian_xian,
"di_ya": di_ya,
}
然后你就可以开启爬虫脚本,进行数据爬取。
数据爬取的规则定义需要用到XPath插件,这是一个谷歌浏览器的插件,用来定位元素内容的插件。
Xpath百度百科:XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。
Xpath语法:XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。
1)节点(Node)
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
2)选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
下面列出了最有用的路径表达式:
表达式 描述
nodename 选取此节点的所有子节点。
/ 从根节点选取。
// 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
. 选取当前节点。
.. 选取当前节点的父节点。
@ 选取属性。
3)谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。谓语被嵌在方括号中。
实例
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
路径表达式 结果
/bookstore/book[1] 选取属于 bookstore 子元素的第一个 book 元素。
/bookstore/book[last()] 选取属于 bookstore 子元素的最后一个 book 元素。
/bookstore/book[last()-1] 选取属于 bookstore 子元素的倒数第二个 book 元素。
/bookstore/book[position()<3] 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。
//title[@lang] 选取所有拥有名为 lang 的属性的 title 元素。
//title[@lang='eng'] 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。
/bookstore/book[price>35.00] 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。
/bookstore/book[price>35.00]/title 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。
4)选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
通配符 描述
* 匹配任何元素节点。
@* 匹配任何属性节点。
node() 匹配任何类型的节点。
5)XPath 轴
轴可定义相对于当前节点的节点集。
如何使用Xpath插件定位页面元素呢?我们拿蒲公英上传APK为例:
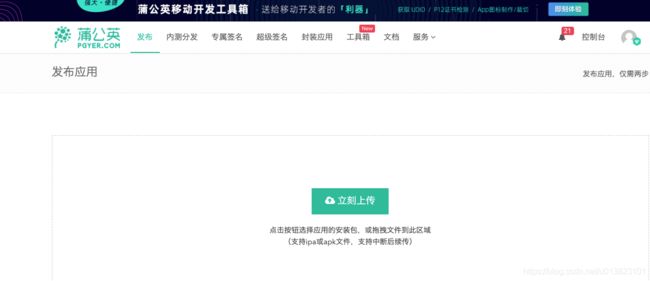
打开页面之后,登录蒲公英账户之后就到了上传Apk文件页面。现在我们按F12,查看网页源代码之后,点击源码右上角的按钮,然后选中需要定位的网页页面元素,获取到Xpath路径就可以用这个路径来确定这个页面元素了。