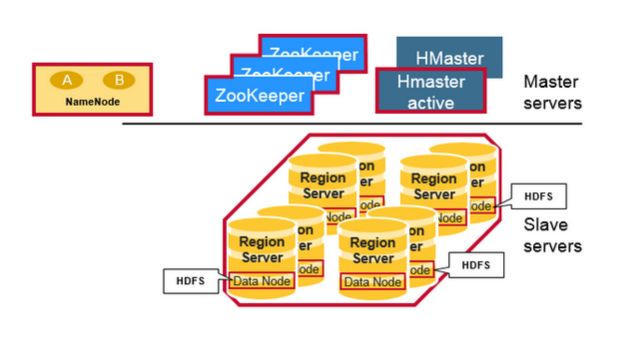
一.Hbase 架构的组件
- Region Server:提供数据的读写服务,当客户端访问数据时,直接和Region Server通信。
- HBase Master:Region的分配,.DDL操作(创建表,删除表)
- Zookeeper:是HDFS的一部分,维护一个活跃的集群状态
Hadoop DataNode存储着Region Server 管理的数据,所有的Hbase数据存储在HDFS文件系统中,Region Servers在HDFS DataNode中是可配置的,并使数据存储靠近在它所需要的地方,就近服务,当王HBASE写数据时时Local的,但是当一个region 被移动之后,Hbase的数据就不是Local的,除非做了压缩(compaction)操作。NameNode维护物理数据块的元数据信息。
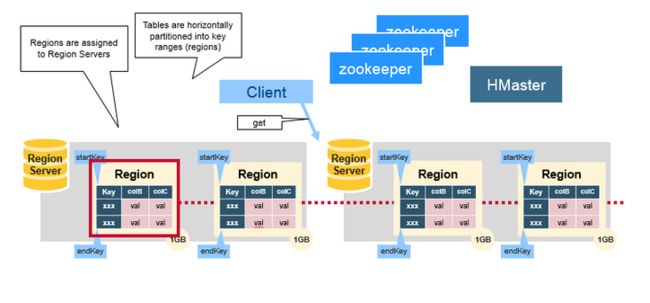
二.Regions
HBase Tables 通过行健的范围(row key range)被水平切分成多个Region, 一个Region包含了所有的,在Region开始键和结束之内的行,Regions被分配到集群的节点上,成为 Region Servers,提供数据的读写服务,一个region server可以服务1000 个Region。
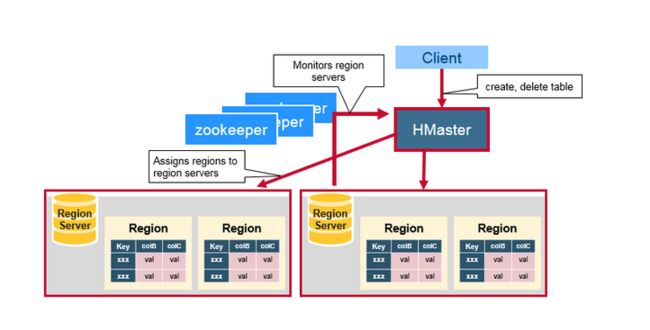
三.HBase HMaster
分配Region,DDL操作(创建表, 删除表)
协调各个Reion Server :
-在启动时分配Region、在恢复或是负载均衡时重新分配Region。
-监控所有集群当中的Region Server实例,从ZooKeeper中监听通知。
管理功能:
-提供创建、删除、更新表的接口。
四.ZooKeeper:协调器
Hbase使用Zookeeper作为分布式协调服务,来维护集群中的Server状态,ZooKeeper维护着哪些Server是活跃或是可用的。提供Server 失败时的通知。Zookeeper使用一致性机制来保证公共的共享状态,注意,需要使用奇数的三台或是五台机器,保证一致。
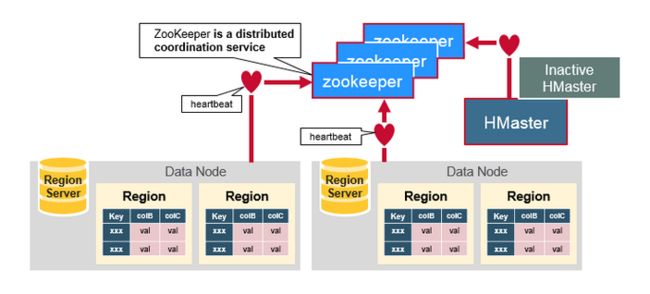
五、组件之间如何工作
Zookeeper一般在分布式系统中的成员之间协调共享的状态信息,Region Server和活跃的HMaster通过会话连接到Zookeeper,ZooKeeper维护短暂的阶段,通过心跳机制用于活跃的会话。
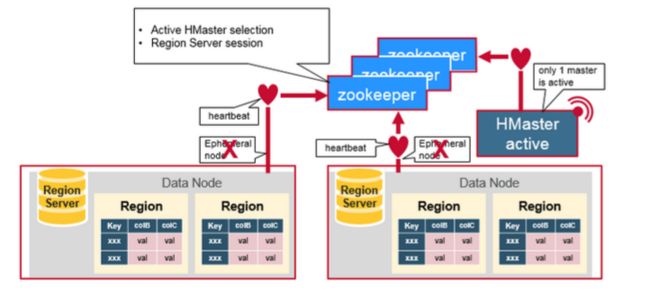
每个Region Server创建一个短暂的节点,HMaster监控这些节点发现可用的Region Server,同时HMaster 也监控这些节点的服务器故障。HMaster 通过撞见一个临时的节点,Zookeeper决定其中一个HMaster作为活跃的。活跃的HMaster 给ZooKeeper发送心跳信息,不活跃的HMaster在活跃的HMaster出现故障时,接受通知。
如果一个Region Server或是一个活跃的HMaster在发送心跳信息时失败或是出现了故障,则会话过期,相应的临时节点将被删除,监听器将因这些删除的节点更新通知信息,活跃的HMaster将监听Region Server,并且将会恢复出现故障的Region Server,不活跃的HMaster 监听活跃的HMaster故障,如果一个活跃的HMaster出现故障,则不活跃的HMaster将会变得活跃。
六 Hbase 的首次读与写
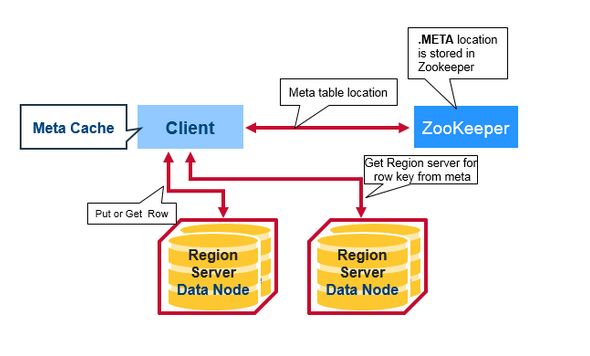
有一个特殊的Hbase 目录表叫做Meta表,它拥有Region 在集群中的位置信息,ZooKeeper存储着Meta表的位置。
如下就是客户端首次读写Hbase 所发生的事情:
1.客户端从Zookeeper的Meta表中获取Region Server。
2.客户端将查询 .META.服务器,获取它想访问的相对应的Region Server的行健。客户端将缓存这些信息以及META 表的位置。
3.护额端将从相应的Region Server获取行。
如果再次读取,客户端将使用缓存来获取META 的位置及之前的行健。这样时间久了,客户端不需要查询META表,除非Region 移动所导致的丢失,这样的话,则将会重新查询更新缓存。
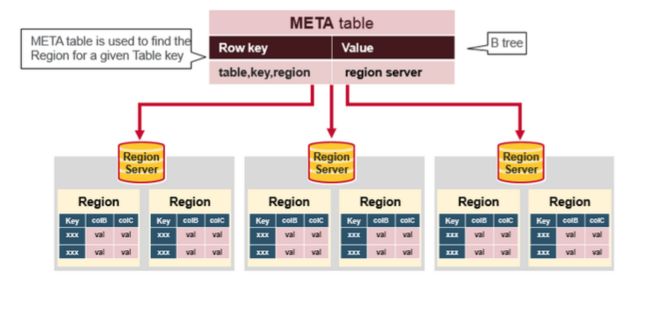
七 Hbase META表
META 表集群中所有Region的列表
.META. 表像是一个B树
.META. 表结构为:
- Key: region start key,region id
- Values: RegionServer
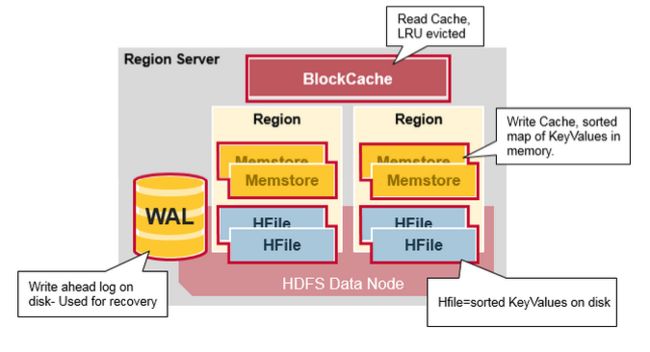
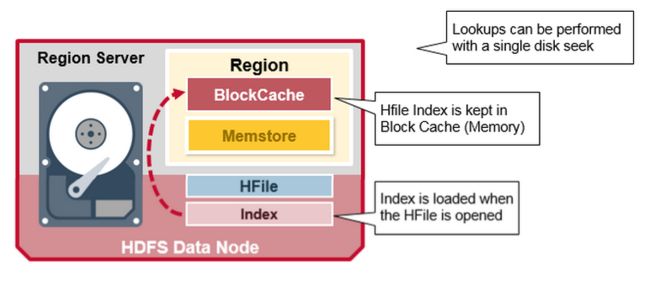
八 Region Server 的组件
Region Server 运行在HDFS DataNode上,并有如下组件:
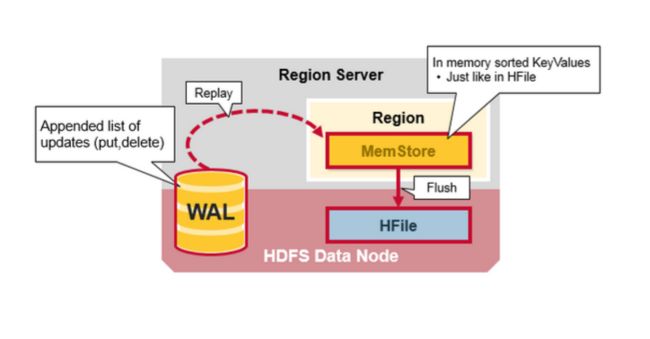
WAL:Write Ahead Log 提前写日志是一个分布式文件系统上的文件,WAL存储没有持久化的新数据,用于故障恢复,类似Oracle 的Redo Log。
BlockCache:读缓存,它把频繁读取的数据放入内存中,采用LRU
MemStore:写缓存,存储来没有来得及写入磁盘的新数据,每一个region的每一个列族有一个MemStore
Hfiles :存储行,作为键值对,在硬盘上。
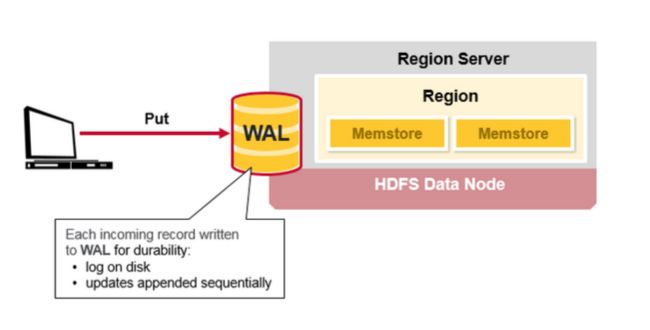
 Hbase 写步骤1:
Hbase 写步骤1:
当客户端提交一个Put 请求,第一步是把数据写入WAL:
-编辑到在磁盘上的WAL的文件,添加到WAL文件的末尾
-WAL用于宕机恢复
 Hbase 写步骤2
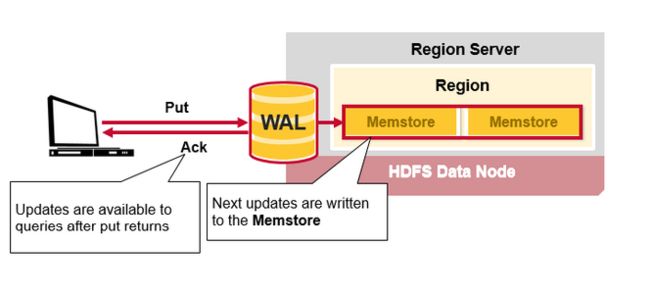
Hbase 写步骤2
一旦数据写入WAL,将会把它放到MemStore里,然后将返回一个ACk给客户端
MemStore
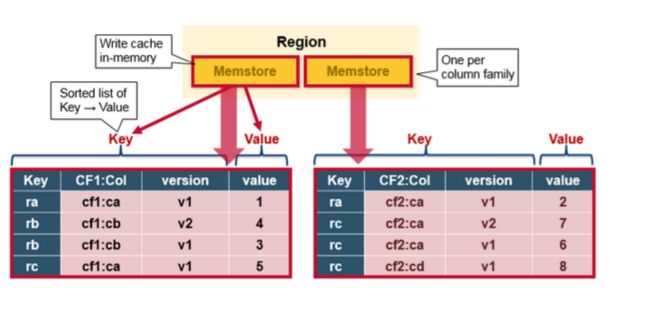
MemStore 存储以键值对的方式更新内存,和存储在HFile是一样的。每一个列族就有一个MemStore ,以每个列族顺序的更新。
HBase Region 刷新(Flush)
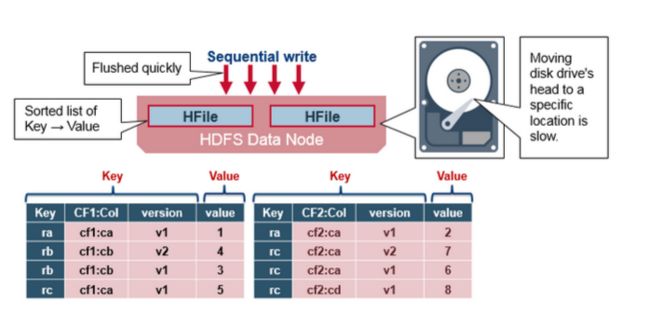
当MemStore 积累到足够的数据,则整个排序后的集合被写到HDFS的新的HFile中,每个列族使用多个HFiles,列族包含真实的单元格,或者是键值对的实例,随着KeyValue键值对在MemStores中编辑排序后,作为文件刷新到磁盘上。
注意列族是有数量限制的,每一个列族有一个MemStore,当MemStore满了,则进行刷新。它也会保持最后一次写的序列号,这让系统知道直到现在都有什么已经被持久化了。
最高的序列号作为一个meta field 存储在HFile中,来显示持久化在哪里结束,在哪里继续。当一个region 启动后,读取序列号,最高的则作为新编辑的序列号。

HBase HFile
数据存储在HFile,HFile 存储键值,当MemStore 积累到足够的数据,整个排序的键值集合会写入到HDFS中新的HFile 中。这是一个顺序的写,非常快,能避免移动磁头。
HFile 的结构
HFile 包含一个多层的索引,这样不必读取整个文件就能查找到数据,多层索引像一个B+树。
- 键值对以升序存储
- 在64K的块中,索引通过行健指向键值对的数据。
- 每个块有自己的叶子索引
- 每个块的最后的键被放入到一个中间索引中。
- 根索引指向中间索引。
trailer (追踪器)指向 meta的块,并在持久化到文件的最后时被写入。trailer 拥有 bloom过滤器的信息以及时间范围(time range)的信息。Bloom 过滤器帮助跳过那些不含行健的文件,时间范围(time range)则跳过那些不包含在时间范围内的文件。
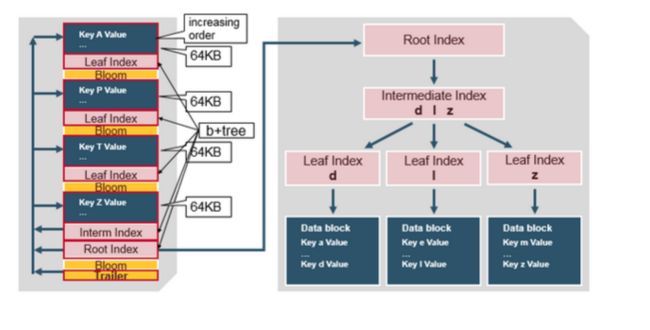
HFile Index
索引是在HFile 打开并放入内存中时被加载的,这允许在单个磁盘上执行查找。
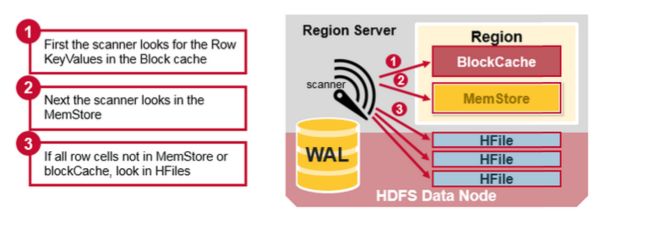
HBase 读合并
一个行的键值单元格可以被存储在很多地方,行单元格已经被存储到HFile中、在MemStore最近被更新的单元格、在Block cache最佳被读取的单元格,所以当你读取一行数据时,系统怎么能把相对应的单元格内容返回呢?一次读把block cache, MemStore, and HFiles中的键值合并的步骤如下:
- 首先,扫描器(scanner )在读缓存的Block cache寻找行单元格,最近读取的键值缓存在Block cache中,当内存需要时刚使用过的(Least Recently Used )将会被丢弃。
- 接下来,扫描器(scanner)将在MemStore中查找,以及在内存中最近被写入的写缓存。
- 如果扫描器(scanner)在MemStore 和Block Cache没有找到所有的数据,则HBase 将使用 Block Cache的索引以及bloom过滤器把含有目标的行单元格所在的HFiles 加载到内存中。
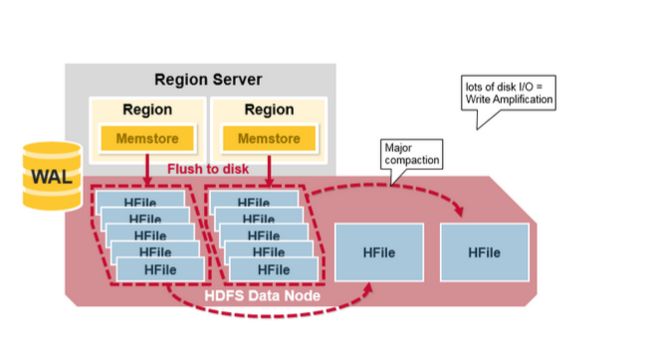
每个MemStore有许多HFiles 文件,这样对一个读取操作来说,多个文件将不得不被多次检查,势必会影响性能,这种现象叫做读放大(read amplification)。
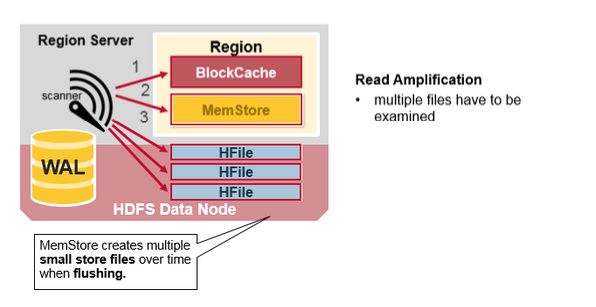
HBase 辅压缩(minor compaction)
HBase将会自动把小HFiles 文件重写为大的HFiles 文件,这个过程叫做minor compaction。
辅助压缩减少文件的数量,并执行合并排序。

HBase 主压缩(Major Compaction)
主压缩将会合并和重写一个region 的所有HFile 文件,根据每个列族写一个HFile 文件,并在这个过程中,删除deleted 和expired 的单元格,这将提高读性能。
然而因为主压缩重写了所有的文件,这个过程中将会导致大量的磁盘IO操作以及网络拥堵。我们把这个过程叫做写放大(write amplification)。
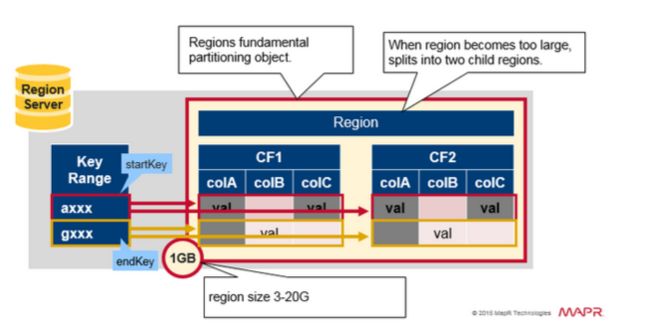
Region = 相邻的键
- 一个表将被水平分割为一个或多个Region,一个Region包含相邻的起始键和结束键之间的行的排序后的区域。
- 每个region默认1GB
- 一个region的表通过Region Server 向客户端提供服务
- 一个region server可以服务1000 个region
Region 分裂
初始时一个table在一个region 中,当一个region 变大之后,将会被分裂为2个子region,每个子Region 代表一半的原始Region,在一个相同的 Region server中并行打开。
然后把分裂报告给HMaster。因为需要负载均衡的缘故,HMaster 可能会调度新的Region移动到其他的Server上。
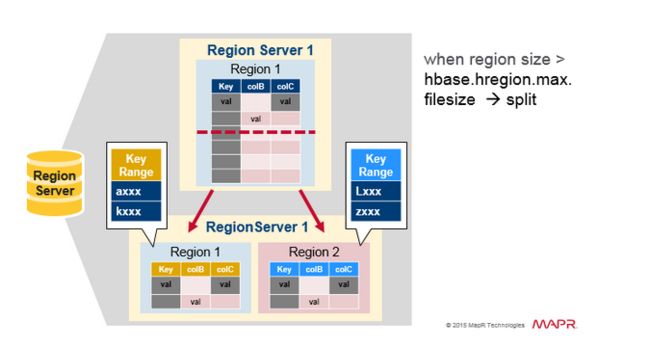
读负载均衡(Read Load Balancing)
分裂一开始发生在相同的region server上,但是由于负载均衡的原因。HMaster 可能会调度新的Region被移动到其他的服务器上。
导致的结果是新的Region Server 提供数据的服务需要读取远端的HDFS 节点。直到主压缩把数据文件移动到Regions server本地节点上,Hbase数据当写入时是本地的,
但是当一个region 移动(诸如负载均衡或是恢复操作等),它将不会是本地的,直到做了主压缩的操作(major compaction.)
 HDFS数据复制
HDFS数据复制
所有的读写操作发生在主节点上,HDFS 复制WAL和HFile 块,HFile复制是自动发生的,HBase 依赖HDFS提供数据的安全,
当数据写入HDFS,本地化地写入一个拷贝,然后复制到第二个节点,然后复制到第三个节点。
WAL 文件和 HFile文件通过磁盘和复制进行持久化,那么HBase怎么恢复还没来得及进行持久化到HFile中的MemStore更新呢?
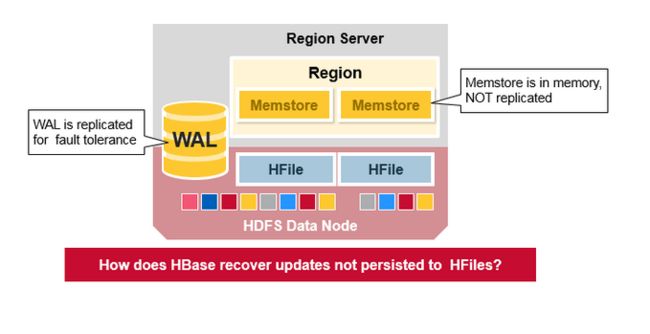 HBase 故障恢复
HBase 故障恢复
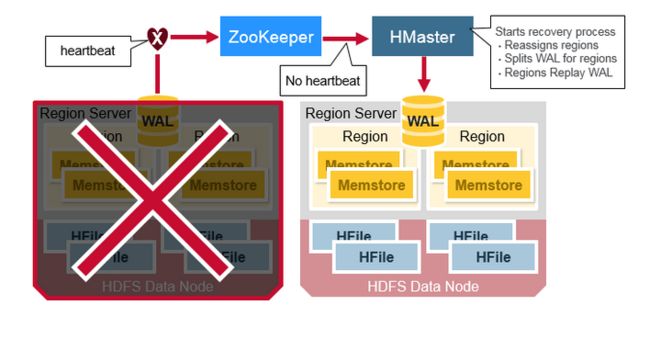
当一个RegionServer 挂掉了,坏掉的Region 不可用直到发现和恢复的步骤发生。Zookeeper 决定节点的失败,然后失去region server的心跳。
然后HMaster 将会被通知Region Server已经挂掉了。
当HMaster检查到region server已经挂掉后,HMaster 将会把故障Server上的Region重写分配到活跃的Region servers上。
为了恢复宕掉的region server,memstore 将不会刷新到磁盘上,HMaster 分裂属于region server 的WAL 到单独的文件,
然后存储到新的region servers的数据节点上,每个Region Server从单独的分裂的WAL回放WAL。来重建坏掉的Region的MemStore。
 数据恢复
数据恢复
WAL 文件包含编辑列表,一个编辑代表一个单独的put 、delete.Edits 是按时间的前后顺序排列地写入,为了持久化,增加的文件将会Append到WAL 文件的末尾。
当数据在内存中而没有持久化到磁盘上时失败了将会发生什么?通过读取WAL将WAL 文件回放,
添加和排序包含的edits到当前的MemStore,最后MemStore 刷新将改变写入到HFile中。
HBase架构的优点:
强一致模型:当写返回,所有的读将看到一样的结果
自动扩展:Regions 随着数据变大将分裂,使用HDFS传播和复制数据
内建的恢复机制:使用WAL
和Hadoop的集成
HBase架构的缺点:
WAL回放较慢
故障恢复较慢
主压缩导致IO瓶颈。