参考来自: http://tech.meituan.com/spark-tuning-basic.html
Spark的持久化级别
官网描述: http://spark.apache.org/docs/latest/rdd-programming-guide.html
| 持久化级别 | 含义解释 |
|---|---|
| MEMORY_ONLY | 使用未序列化的Java对象格式,将数据保存在内存中。如果内存不够存放所有的数据,则数据可能就不会进行持久化。那么下次对这个RDD执行算子操作时,那些没有被持久化的数据,需要从源头处重新计算一遍。这是默认的持久化策略,使用cache()方法时,实际就是使用的这种持久化策略。 |
| MEMORY_AND_DISK | 使用未序列化的Java对象格式,优先尝试将数据保存在内存中。如果内存不够存放所有的数据,会将数据写入磁盘文件中,下次对这个RDD执行算子时,持久化在磁盘文件中的数据会被读取出来使用。 |
| MEMORY_ONLY_SER | 基本含义同MEMORY_ONLY。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC。 |
| MEMORY_AND_DISK_SER | 基本含义同MEMORY_AND_DISK。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC。 |
| DISK_ONLY | 使用未序列化的Java对象格式,将数据全部写入磁盘文件中。 |
MEMORY_ONLY_2, MEMORY_AND_DISK_2, 等等. 对于上述任意一种持久化策略,如果加上后缀_2,代表的是将每个持久化的数据,都复制一份副本,并将副本保存到其他节点上。这种基于副本的持久化机制主要用于进行容错。假如某个节点挂掉,节点的内存或磁盘中的持久化数据丢失了,那么后续对RDD计算时还可以使用该数据在其他节点上的副本。如果没有副本的话,就只能将这些数据从源头处重新计算一遍了。
如何选择一种最合适的持久化策略
默认情况下,性能最高的当然是MEMORY_ONLY,但前提是你的内存必须足够足够大,可以绰绰有余地存放下整个RDD的所有数据。因为不进行序列化与反序列化操作,就避免了这部分的性能开销;对这个RDD的后续算子操作,都是基于纯内存中的数据的操作,不需要从磁盘文件中读取数据,性能也很高;而且不需要复制一份数据副本,并远程传送到其他节点上。但是这里必须要注意的是,在实际的生产环境中,恐怕能够直接用这种策略的场景还是有限的,如果RDD中数据比较多时(比如几十亿),直接用这种持久化级别,会导致JVM的OOM内存溢出异常。
如果使用MEMORY_ONLY级别时发生了内存溢出,那么建议尝试使用MEMORY_ONLY_SER级别。该级别会将RDD数据序列化后再保存在内存中,此时每个partition仅仅是一个字节数组而已,大大减少了对象数量,并降低了内存占用。这种级别比MEMORY_ONLY多出来的性能开销,主要就是序列化与反序列化的开销。但是后续算子可以基于纯内存进行操作,因此性能总体还是比较高的。此外,可能发生的问题同上,如果RDD中的数据量过多的话,还是可能会导致OOM内存溢出的异常。
如果纯内存的级别都无法使用,那么建议使用MEMORY_AND_DISK_SER策略,而不是MEMORY_AND_DISK策略。因为既然到了这一步,就说明RDD的数据量很大,内存无法完全放下。序列化后的数据比较少,可以节省内存和磁盘的空间开销。同时该策略会优先尽量尝试将数据缓存在内存中,内存缓存不下才会写入磁盘。
通常不建议使用DISK_ONLY和后缀为_2的级别:因为完全基于磁盘文件进行数据的读写,会导致性能急剧降低,有时还不如重新计算一次所有RDD。后缀为_2的级别,必须将所有数据都复制一份副本,并发送到其他节点上,数据复制以及网络传输会导致较大的性能开销,除非是要求作业的高可用性,否则不建议使用。
shuffle 概念
来自: https://www.cnblogs.com/rxingyue/p/7113178.html
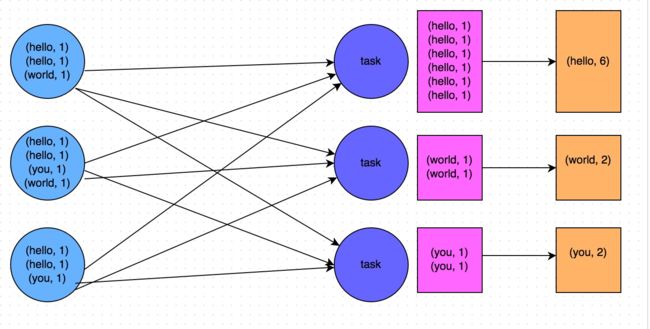
Shuffle是MapReduce框架中的一个特定的phase,介于Map phase和Reduce phase之间,当Map的输出结果要被Reduce使用时,输出结果需要按key哈希,并且分发到每一个Reducer上去,这个过程就是shuffle。由于shuffle涉及到了磁盘的读写和网络的传输,因此shuffle性能的高低直接影响到了整个程序的运行效率。

多个计算节点之间写数据 读数据 的过程
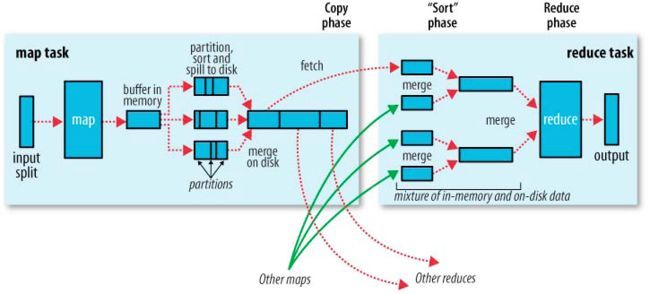
shuffle 是划分 DAG 中 stage 的分界线, 也是影响spark性能的关键,
map类算子是窄依赖, 不会产生shuffle(即不会重新分区)。宽依赖包括reduceByKey、join、distinct、repartition等shuffle算子,例如, rdd.map(x => (x, 1)).reduceByKey(_ + _).foreach(println), 这个job因为有reduce,所以有一个shuffle过程,那么reduceByKey之前的是一个stage,执行shuffleMapTask,输出shuffle所需的数据,reduceByKey到最后是一个stage , foreach(println)是action操作, 会触发生成一个Job, 然后这个Job根据shuffle前后拆分为两个stage。
RDD的partition 分区越多, Map-Redue 过程中产生的Shuffle write和 Shuffle Fetch 也会越多, 一般partition的大小设为core数量的 2~3倍为宜。
shuffle 优化
- 避免使用shuffle类算子
mapJoin 替换掉 reduceJoin, 具体做法就是利用broadcast广播小数据, 然后利用Map算子就可以完成Join操作, 具体做法有两种:
(1) 利用spark.sql的broadcast广播表
import org.apache.spark.sql.functions.broadcast
broadcast(df1).join(df2, Seq(..., ...))
注意: spark.sql.autoBroadcastJoinThreshold设置表广播的阈值,如果有需求且内存足够,可以将该值提高,默认10M
(2) 转换成RDD操作。
Broadcast Join的条件有以下几个:
- 被广播的表需要小于spark.sql.autoBroadcastJoinThreshold所配置的值,默认是10M (或者加了broadcast join的hint)
- 基表不能被广播,比如left outer join时,只能广播右表
看起来广播是一个比较理想的方案,但它有没有缺点呢?也很明显。这个方案只能用于广播较小的表,否则数据的冗余传输就远大于shuffle的开销;另外,广播时需要将被广播的表现collect到driver端,当频繁有广播出现时,对driver的内存也是一个考验。
Broadcast与map进行join代码示例
// 传统的join操作会导致shuffle操作。
// 因为两个RDD中,相同的key都需要通过网络拉取到一个节点上,由一个task进行join操作。
val rdd3 = rdd1.join(rdd2)
// Broadcast+map的join操作,不会导致shuffle操作。
// 使用Broadcast将一个数据量较小的RDD作为广播变量。
val rdd2Data = rdd2.collect()
val rdd2DataBroadcast = sc.broadcast(rdd2Data)
// 在rdd1.map算子中,可以从rdd2DataBroadcast中,获取rdd2的所有数据。
// 然后进行遍历,如果发现rdd2中某条数据的key与rdd1的当前数据的key是相同的,那么就判定可以进行join。
// 此时就可以根据自己需要的方式,将rdd1当前数据与rdd2中可以连接的数据,拼接在一起(String或Tuple)。
val rdd3 = rdd1.map(rdd2DataBroadcast...)
// 注意,以上操作,建议仅仅在rdd2的数据量比较少(比如几百M,或者一两G)的情况下使用。
// 因为每个Executor的内存中,都会驻留一份rdd2的全量数据。
- 使用map-side预聚合的shuffle操作
如果因为业务需要,一定要使用shuffle操作,无法用map类的算子来替代,那么尽量使用可以map-side预聚合的算子。
所谓的map-side预聚合,说的是在每个节点本地对相同的key进行一次聚合操作,类似于MapReduce中的本地combiner。map-side预聚合之后,每个节点本地就只会有一条相同的key,因为多条相同的key都被聚合起来了。其他节点在拉取所有节点上的相同key时,就会大大减少需要拉取的数据数量,从而也就减少了磁盘IO以及网络传输开销。通常来说,在可能的情况下,建议使用reduceByKey或者aggregateByKey算子来替代掉groupByKey算子。因为reduceByKey和aggregateByKey算子都会使用用户自定义的函数对每个节点本地的相同key进行预聚合。而groupByKey算子是不会进行预聚合的,全量的数据会在集群的各个节点之间分发和传输,性能相对来说比较差。