Spark学习笔记7-在eclipse里用scala编写spark程序(单机和集群运行)
1.下载eclipse
我下载的是带scala SDK的eclipse,下载地址如下:
http://scala-ide.org/download/sdk.html
我的要放在ubuntu下写程序,所以下载linux 64位的。 
下载完成后自行解压。
2.单机下运行WordCount程序
我要测试运行的是单词计数的程序。采用的文件来自/Users/xxm/Documents/soft/spark-1.5.2-bin-hadoop2.6/README.md,spark程序按空格将这个文件内容划分成单词,并计相同单词出现次数,并打印出来。
2.1创建scala工程
创建scala工程,工程名字为WordCount 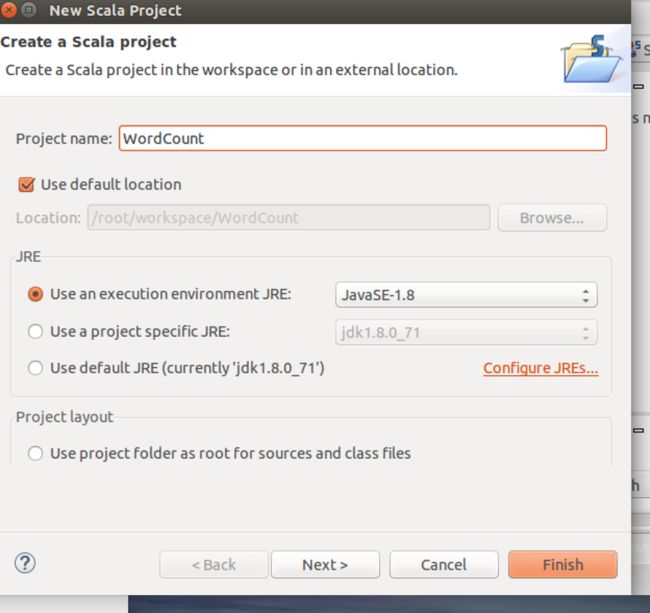
直接next到finsh。 
2.2 修改依赖的scala版本为scala2.10.x
默认下是scala 2.11.7,如下图: 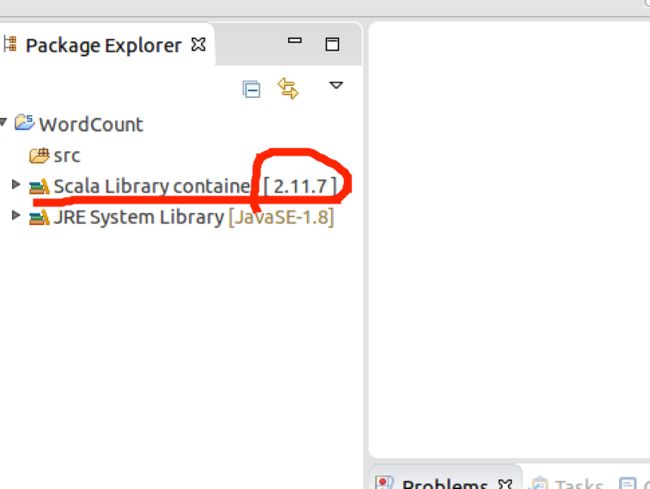
具体操作见下面图中所示:
先右键进入properties中 
按下图四步骤操作: 
完成后修改为2.10.6版本 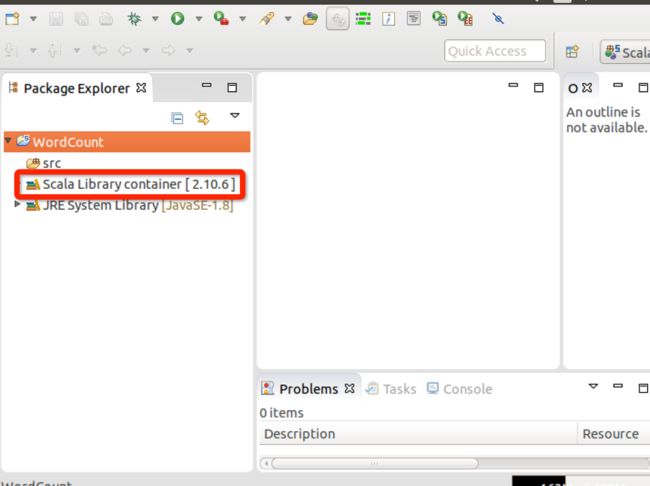
2.3 加入spark的jar包
jar包的目录如下所示: 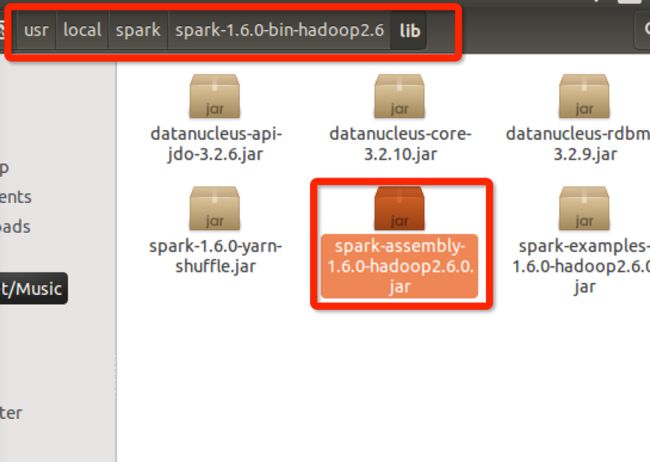
右键工程,在build path 中进入configure 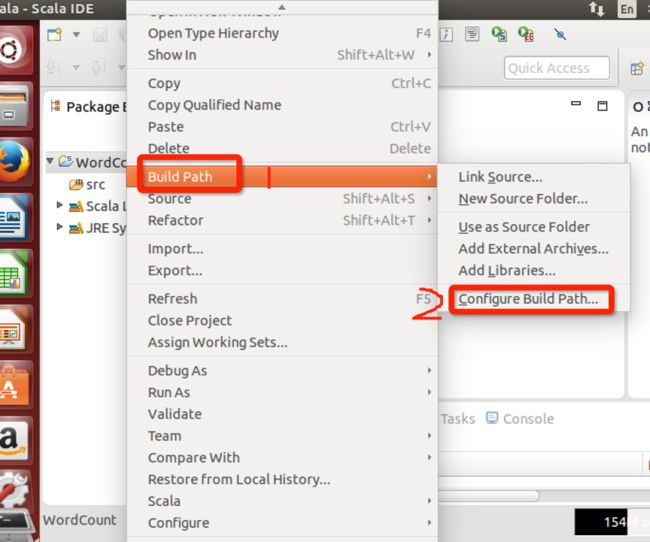
按下两幅图的顺序加入: 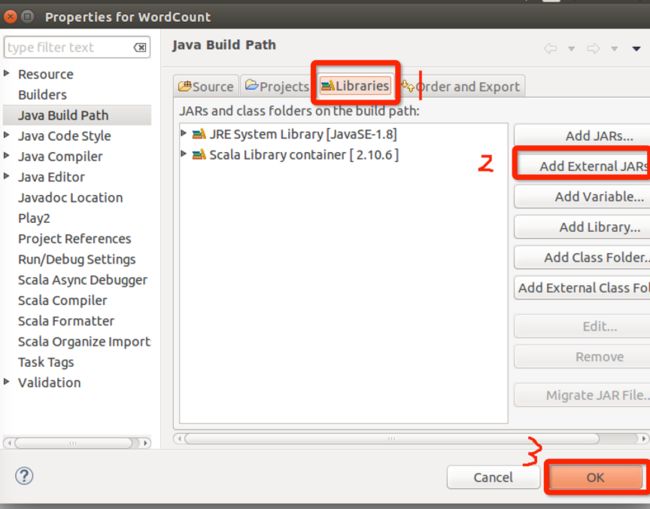

这个时候可以看到导入了spark的tar包 
2.4 在src下建立spark工程包
先建立一个package 
package名称为com.dt.spark 
再在包里创建scala类 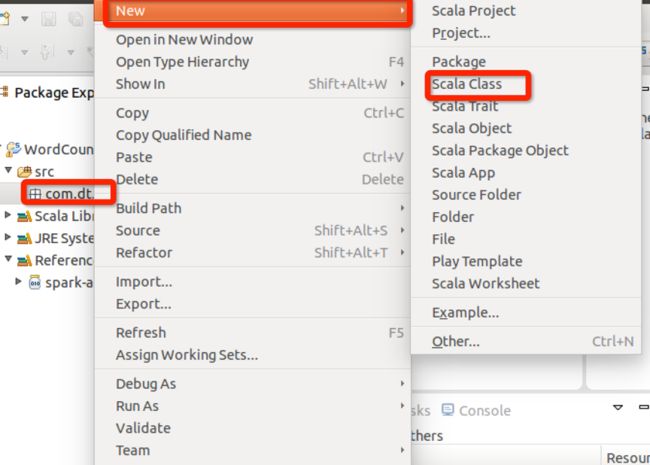
类名为WordCount 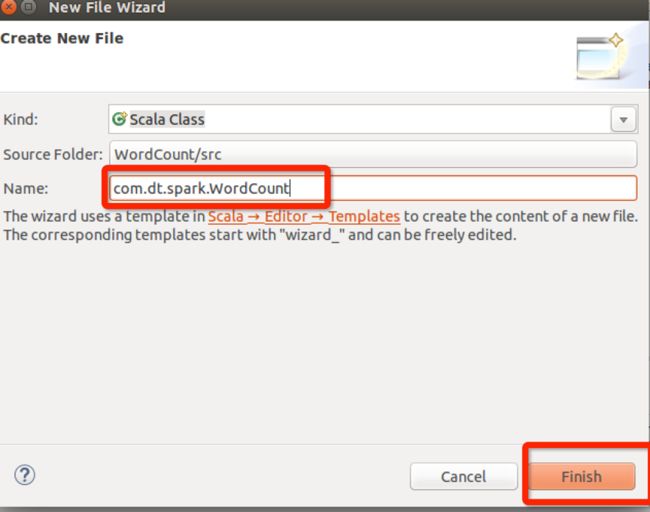
创建完成后,如下图所示: 
2.5 编写程序并运行
因为程序的入口函数是main,所以要先定义mian,同时把class修改为object。 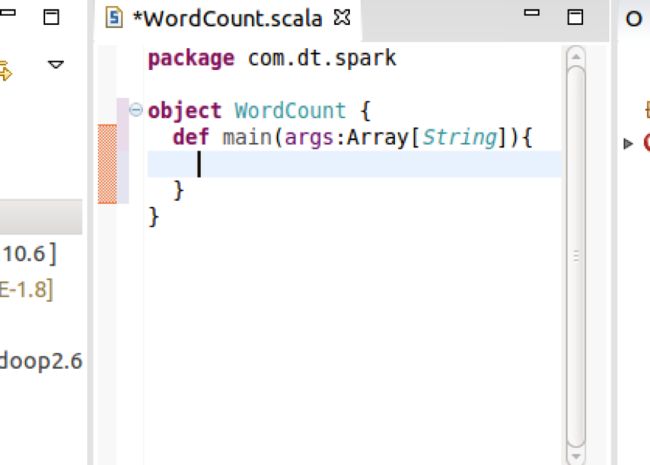
输入代码如下,并运行,结果在控制台中可以看到,结果是将单词都进行多计数。 
代码内容(加入注解,方便学习):
package com.dt.spark
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
/**
* 使用Scala开发本地测试的Spark WordCount程序
* 程序注释内容来自王家林的大数据视频
*/
object WordCount {
def main(args : Array[String]){
/**
* 第1步:创建Spark的配置对象SparkConf,设置Spark程序的运行时的配置信息,
* 例如说通过setMaster来设置程序要链接的Spark集群的Master的URL,如果设置
* 为local,则代表Spark程序在本地运行,特别适合于机器配置条件非常差(例如
* 只有1G的内存)的初学者 *
*/
val conf = new SparkConf()//创建SparkConf对象
conf.setAppName("Wow,My First Spark Programe")//设置应用程序的名称,在程序运行的监控界面可以看到名称
conf.setMaster("local")//此时,程序在本地运行,不需要安装Spark集群
/**
* 第2步:创建SparkContext对象
* SparkContext是Spark程序所有功能的唯一入口,无论是采用Scala、Java、Python、R等都必须有一个SparkContext
* SparkContext核心作用:初始化Spark应用程序运行所需要的核心组件,包括DAGScheduler、TaskScheduler、SchedulerBackend
* 同时还会负责Spark程序往Master注册程序等
* SparkContext是整个Spark应用程序中最为至关重要的一个对象
*/
val sc = new SparkContext(conf)//创建SparkContext对象,通过传入SparkConf实例来定制Spark运行的具体参数和配置信息
/**
* 第3步:根据具体的数据来源(HDFS、HBase、Local FS、DB、S3等)通过SparkContext来创建RDD
* RDD的创建基本有三种方式:根据外部的数据来源(例如HDFS)、根据Scala集合、由其它的RDD操作
* 数据会被RDD划分成为一系列的Partitions,分配到每个Partition的数据属于一个Task的处理范畴
*/
val lines = sc.textFile("/Users//xxm//Documents//soft//spark-1.5.2-bin-hadoop2.6//README.md",1)//读取本地文件并设置为一个Partion
/**
* 第4步:对初始的RDD进行Transformation级别的处理,例如map、filter等高阶函数等的编程,来进行具体的数据计算
* 第4.1步:讲每一行的字符串拆分成单个的单词
*/
val words = lines.flatMap{line => line.split(" ")}//对每一行的字符串进行单词拆分并把所有行的拆分结果通过flat合并成为一个大的单词集合
/**
* 第4步:对初始的RDD进行Transformation级别的处理,例如map、filter等高阶函数等的编程,来进行具体的数据计算
* 第4.2步:在单词拆分的基础上对每个单词实例计数为1,也就是word => (word, 1)
*/
val pairs = words.map{word => (word,1)}
/**
* 第4步:对初始的RDD进行Transformation级别的处理,例如map、filter等高阶函数等的编程,来进行具体的数据计算
* 第4.3步:在每个单词实例计数为1基础之上统计每个单词在文件中出现的总次数
*/
val wordCounts = pairs.reduceByKey(_+_)//对相同的Key,进行Value的累计(包括Local和Reducer级别同时Reduce)
wordCounts.foreach(wordNumberPair => println(wordNumberPair._1 + " : " +wordNumberPair._2))//在命令行中打印该结果
sc.stop()//记得关闭创建的SparkContext对象
}
}输出结果:
ackage : 1
For : 2
Programs : 1
processing. : 1
Because : 1
The : 1
cluster. : 1
its : 1
[run : 1
APIs : 1
have : 1
Try : 1
computation : 1
through : 1
several : 1
This : 2
"yarn-cluster" : 1
graph : 1
Hive : 2
storage : 1
["Specifying : 1
To : 2
page](http://spark.apache.org/documentation.html) : 1
Once : 1
application : 1
prefer : 1
SparkPi : 2
engine : 1
version : 1
file : 1
documentation, : 1
processing, : 1
the : 21
are : 1
systems. : 1
params : 1
not : 1
different : 1
refer : 2
Interactive : 2
R, : 1
given. : 1
if : 4
build : 3
when : 1
be : 2
Tests : 1
Apache : 1
./bin/run-example : 2
programs, : 1
including : 3
Spark. : 1
package. : 1
1000).count() : 1
Versions : 1
HDFS : 1
Data. : 1
>>> : 1
programming : 1
Testing : 1
module, : 1
Streaming : 1
environment : 1
run: : 1
clean : 1
1000: : 2
rich : 1
GraphX : 1
["Third : 1
Please : 3
is : 6
run : 7
URL, : 1
threads. : 1
same : 1
MASTER=spark://host:7077 : 1
on : 6
built : 1
against : 1
[Apache : 1
tests : 2
examples : 2
at : 2
optimized : 1
usage : 1
using : 2
graphs : 1
talk : 1
Shell : 2
class : 2
abbreviated : 1
directory. : 1
README : 1
computing : 1
overview : 1
`examples` : 2
example: : 1
## : 8
N : 1
set : 2
use : 3
Hadoop-supported : 1
tests](https://cwiki.apache.org/confluence/display/SPARK/Useful+Developer+Tools). : 1
running : 1
find : 1
contains : 1
project : 1
Pi : 1
need : 1
or : 4
Big : 1
Java, : 1
high-level : 1
uses : 1
: 1
Hadoop, : 2
available : 1
requires : 1
(You : 1
see : 1
Documentation : 1
of : 5
tools : 1
using: : 1
cluster : 2
must : 1
supports : 2
built, : 1
system : 1
build/mvn : 1
Hadoop : 4
this : 1
Version"](http://spark.apache.org/docs/latest/building-spark.html#specifying-the-hadoop-version) : 1
particular : 3
Python : 2
Spark : 14
general : 2
YARN, : 1
pre-built : 1
[Configuration : 1
locally : 2
library : 1
A : 1
locally. : 1
sc.parallelize(1 : 1
only : 1
Configuration : 1
following : 2
basic : 1
# : 1
changed : 1
More : 1
which : 2
learning, : 1
See : 1
./bin/pyspark : 1
also : 5
first : 1
should : 2
"yarn-client" : 1
[params]`. : 1
for : 12
documentation : 3
[project : 2
mesos:// : 1
Maven](http://maven.apache.org/). : 1
setup : 1
//spark.apache.org/> : 1
latest : 1
your : 1
MASTER : 1
example : 3
distribution. : 1
scala> : 1
DataFrames, : 1
provides : 1
configure : 1
distributions. : 1
can : 6
About : 1
instructions. : 1
do : 2
easiest : 1
Distributions"](http://spark.apache.org/docs/latest/hadoop-third-party-distributions.html) : 1
no : 1
how : 2
works : 1
`./bin/run-example : 1
Note : 1
individual : 1
spark:// : 1
It : 2
Scala : 2
Alternatively, : 1
an : 3
variable : 1
submit : 1
machine : 1
thread, : 1
them, : 1
detailed : 2
stream : 1
And : 1
distribution : 1
return : 2
Thriftserver : 1
./bin/spark-shell : 1
"local" : 1
start : 1
You : 3
Spark](#building-spark). : 1
one : 2
help : 1
with : 4
print : 1
Party : 1
Spark"](http://spark.apache.org/docs/latest/building-spark.html). : 1
data : 1
wiki](https://cwiki.apache.org/confluence/display/SPARK). : 1
in : 5
-DskipTests : 1
downloaded : 1
versions : 1
online : 1
Guide](http://spark.apache.org/docs/latest/configuration.html) : 1
comes : 1
[building : 1
Python, : 2
Many : 1
building : 3
Running : 1
from : 1
way : 1
Online : 1
site, : 1
other : 1
Example : 1
analysis. : 1
sc.parallelize(range(1000)).count() : 1
you : 4
runs. : 1
Building : 1
higher-level : 1
protocols : 1
guidance : 3
a : 10
guide, : 1
name : 1
fast : 1
SQL : 2
will : 1
instance: : 1
to : 14
core : 1
: 67
web : 1
"local[N]" : 1
programs : 2
package.) : 1
that : 3
MLlib : 1
["Building : 1
shell: : 2
Scala, : 1
and : 10
command, : 2
./dev/run-tests : 1
sample : 1 3.spark集群下运行WordCount
上面我完成了spark在单机中的运行,下面我来将程序修改,打包成jar,放到spark集群中运行。这里我运行的集群时1个Master,2个Worker。
3.1 修改单机程序成可在集群中运行
先创建一个新文件,将local的设置去除,在末尾打印程序部分加速collect。如下图3步骤: 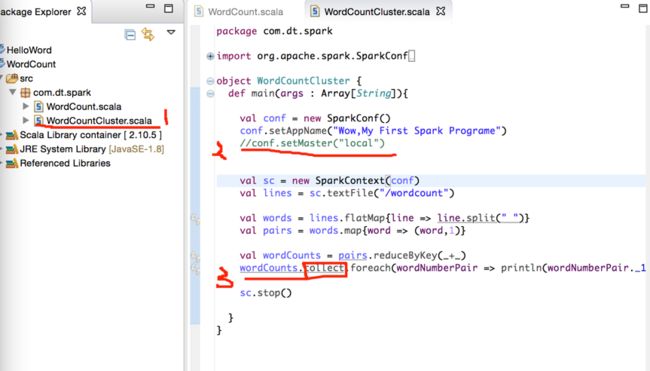
完整代码如下:
package com.dt.spark
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object WordCountCluster {
def main(args : Array[String]){
val conf = new SparkConf()
conf.setAppName("Wow,My First Spark Programe")
//conf.setMaster("local")
val sc = new SparkContext(conf)
val lines = sc.textFile("/wordcount")
val words = lines.flatMap{line => line.split(" ")}
val pairs = words.map{word => (word,1)}
val wordCounts = pairs.reduceByKey(_+_)
wordCounts.collect.foreach(wordNumberPair => println(wordNumberPair._1 + " : " +wordNumberPair._2))
sc.stop()
}
}3.2 程序导出成jar文件
修改好程序后,程序导出成jar文件,文件名为WordCount.jar,文件放到/root/Documents/SparkApps/目录下,如下图: 
3.3 本地文件复制到集群中
将本地的README.md文件复制到集群的/wordcount文件夹里(如何创建文件夹可看,笔记6),操作如下图: 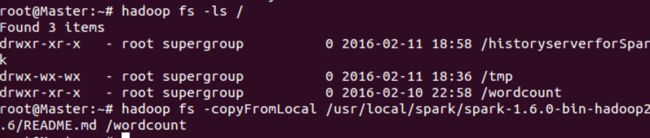
3.4 运行程序
在spark的bin目录下提交程序,程序如下:
./spark-submit --class com.dt.spark.wordCountCluster --master spark://Master:7077 /root/Documents/SparkApps/WordCount.jar![]()
运行后结果如下: 
到这里集群运行spark程序就完成了。
3.5 编写脚步来运行这个程序
创建文件,名称为WordCount.sh,如下图: 
打开文件,写入内容,如下: 
保存并关闭。
设置WordCount.sh文件权限。(系统默认下自己编写的shell是没有直接运行的权限多,所以这一步不能少) ![]()
运行: ![]()
运行后的结果和前面相同。
3.6 在master:18080中查看历史运行记录
如下图,可以查看到,运行了2次作业。 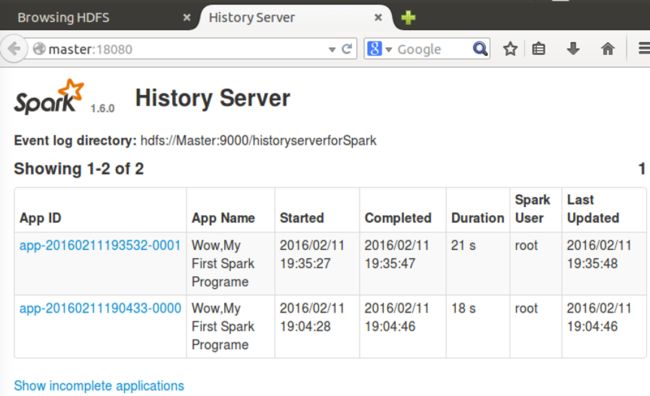
还可以查看作业的DAG图。 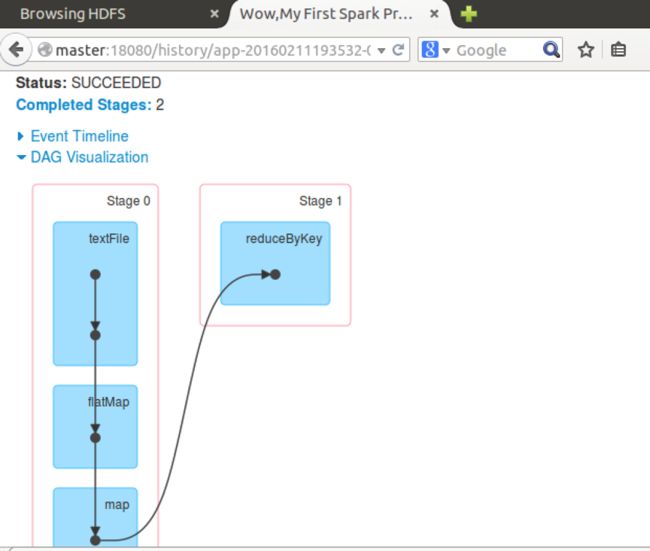
XianMing