SpringBoot2.x入门:使用JPA
前提
这篇文章是《SpringBoot2.x入门》专辑的「第9篇」文章,使用的SpringBoot版本为2.3.1.RELEASE,JDK版本为1.8。
这篇文章会介绍一下SpringBoot如何引入和使用JPA。JPA,即Java Persistence API,是一个基于O/R(对象关系)映射的标准规范(目前最新版本是JPA2.x)。所谓规范即只定义标准规则(如注解、接口),不提供实现,软件提供商可以按照标准规范来实现,而使用者只需按照规范中定义的方式来使用,而不用和软件提供商的实现打交道。
❝也就是说,JPA是一套规范,无论你使用哪种JPA实现,对于使用上或者编码上是一样的,不会因为提供商的改变而影响了使用
❞
JPA的主要功能是通过注解或者XML文件描述对象 - 关系表的映射关系,并且将运行时的实体对象持久化到数据源中。JPA提供的功能如下:
ORM映射元数据管理定义统一的持久化
API定义查询语言
JPQL
目前,JPA的主流实现框架有Hibernate、EclipseLink、TopLink和OpenJPA等等。「SpringBoot中使用的JPA实现是基于Hibernate进行整合的」。
引入JPA
在BOM版本管理下,直接引入spring-boot-starter-data-jpa和相关依赖就行:
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-jdbc
org.springframework.boot
spring-boot-starter-data-jpa
mysql
mysql-connector-java
项目的整体结构如下:
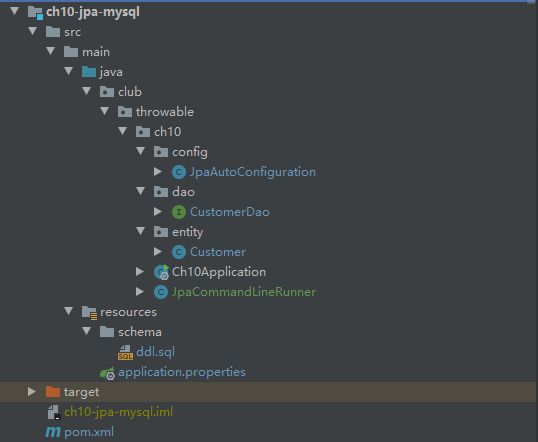
其中:
JpaAutoConfiguration是配置类。CustomerDao为DAO类。Customer为需要映射的实体类。
schema/ddl.sql的内容如下:
USE local;
DROP TABLE IF EXISTS customer;
CREATE TABLE customer
(
id BIGINT UNSIGNED AUTO_INCREMENT PRIMARY KEY COMMENT '主键',
first_name VARCHAR(8) NOT NULL COMMENT '姓氏',
last_name VARCHAR(8) NOT NULL COMMENT '名字',
age SMALLINT NOT NULL COMMENT '年龄',
create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
edit_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间'
) COMMENT '客户表';
细说各项配置
个人认为JPA的配置项和需要注意的地方比使用MyBatis的配置项要多,这里单独使用一个章节详细分析每种配置项和需要注意的地方。首先,需要在配置类中明确定义两组扫描的目录路径或者类:「JPA仓库(一般是DAO类)和受到JPA管理的实体类(Managed Entity)」。笔者编写的JpaAutoConfiguration如下:
@Configuration
// 定义实体类的扫描路径
@EntityScan(basePackages = "club.throwable.ch10.entity")
// 定义仓库类的扫描路径
@EnableJpaRepositories(basePackages = "club.throwable.ch10.dao")
// 审计支持
@EnableJpaAuditing
public class JpaAutoConfiguration {
// 这里的任务执行器的参数需要自行斟酌
@Bean
public ThreadPoolTaskExecutor taskExecutor() {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
taskExecutor.setCorePoolSize(10);
taskExecutor.setMaxPoolSize(10);
taskExecutor.setThreadNamePrefix("TaskExecutorWorker-");
taskExecutor.setQueueCapacity(100);
return taskExecutor;
}
}
这样JPA在Spring上下文加载阶段就能提前加载对应的实体类和仓库类进行预处理。这里还定义了一个TaskExecutor是因为JPA支持异步查询,而异步查询使用到@Async注解,@Async注解依赖到任务执行器,后文会分析。接着看实体类Customer:
@Data
@Entity
@Table(name = "customer")
// 审计支持
@EntityListeners(AuditingEntityListener.class)
public class Customer {
@Id
@GeneratedValue(strategy = IDENTITY)
private Long id;
@Column(name = "first_name")
private String firstName;
@Column(name = "last_name")
private String lastName;
@Column(name = "age")
private Integer age;
@Column(name = "create_time")
@CreatedDate
// java.util.Date
private Date createTime;
@Column(name = "edit_time")
@LastModifiedDate
// java.util.Date
private Date editTime;
}
❝笔者发现了spring-boot-starter-data-jpa对DATETIME类型的column映射的实体字段中的日期时间类型目前只支持org.joda.time.DateTime, org.joda.time.LocalDateTime, java.util.Date, java.lang.Long, long类型,不支持JSR310中的OffsetDateTime、java.time.LocalDateTime等等。
❞
这里用到的JPA注解为:
@Entity:标记此类为JPA管理的实体类。@Table:配置实体类与数据库表的映射关系,也包括索引信息等。@Id与@GeneratedValue:标记主键字段和创建主键值的策略,这里指自增策略。@Column:标记类的属性与数据库表列的映射关系,也包括一些行为配置。@CreatedDate:审计功能支持,标记属性为创建日期,会基于当前时间戳为INSERT操作的对象对应的属性赋值。@LastModifiedDate:审计功能支持,标记属性为最后修改日期,会基于当前时间戳为UPDATE操作的对象对应的属性赋值。
这里其实还有很多未提及到的JPA注解,如@CreatedBy和@LastModifiedBy,可以自行了解和使用。
❝JPA提供审计功能支持,主要包括四个注解:@CreatedDate、@LastModifiedDate、@CreatedBy和@LastModifiedBy,需要在全局配置类通过注解@EnableJpaAuditing开启支持,而实体类中需要添加@EntityListeners(AuditingEntityListener.class)注解。@CreatedBy和@LastModifiedBy则需要通过钩子接口AuditorAware的实现进行注入,获取对应的创建者和最后修改者的填充属性值。
❞
接着看CustomerDao:
public interface CustomerDao extends JpaRepository {
List queryByAgeBetween(Integer min, Integer max);
/**
* 分页
*/
List queryByFirstName(String firstName, Pageable pageable);
/**
* limit
*/
List queryTop5ByFirstName(String firstName);
/**
* 统计
*/
long countByFirstName(String firstName);
/**
* 流式查询
*/
Streamable findByFirstNameContaining(String firstName);
Streamable findByLastNameContaining(String lastName);
/**
* 异步查询
*/
@Async
Future findTop1ByFirstName(String firstName);
@Async
CompletableFuture> findOneByFirstName(String firstName, Pageable pageable);
@Async
ListenableFuture> findOneByLastName(String lastName, Pageable pageable);
}
JPA提供十分高级的API,会根据方法名和参数通过语义解释去拼接SQL、参数赋值和结果封装,这些复杂的过程开发者可以无感知。如果想窥探JPA这些方法的实现,可以看看SimpleJpaRepository的源码。原则上,开发者在开发仓库类的时候,只需要继承org.springframework.data.repository.Repository的子类即可:
@Indexed
public interface Repository {
}
Repository接口或者其子接口都是双泛型标识符的接口,其中第一个泛型参数一般是实体类,而第二个泛型参数一般是主键类型。Repository接口一族的继承关系如下:
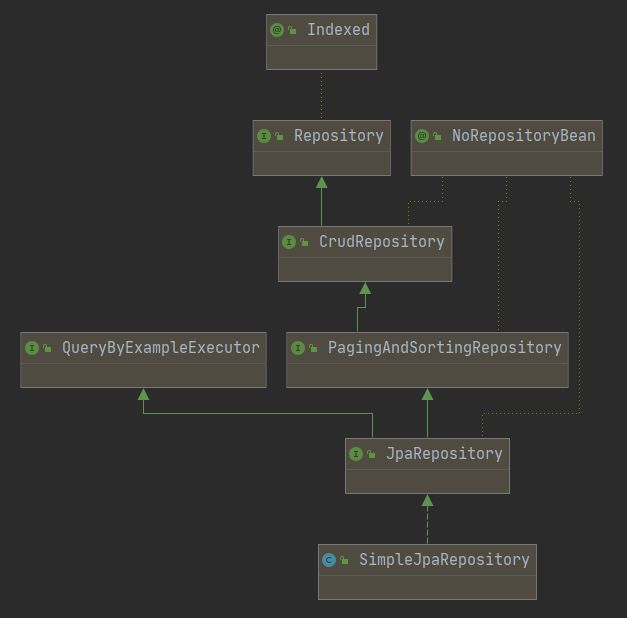
处于越底层的子类,拥有的API就越丰富,这里「推荐仓库类继承JpaRepository即可」。最后看配置文件application.properties中的JPA配置项:
server.port=9100
spring.datasource.url=jdbc:mysql://localhost:3306/local?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false
spring.datasource.username=root
spring.datasource.password=root
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.schema=classpath:schema/ddl.sql
spring.datasource.initialization-mode=always
# 这里需要定义数据库的方言,笔者用的是MySql8.x
spring.jpa.database-platform=org.hibernate.dialect.MySQL8Dialect
# 定义数据库类型
spring.jpa.database=mysql
# 是否打印SQL,一般建议生产环境设置为false,开发或者测试环境可以设置为true
spring.jpa.show-sql=true
spring.jpa.show-sql配置项建议在测试和开发环境设置为true,在生产环境设置为false,避免过多的日志影响了生产环境的应用性能。
测试JPA的方法
为了保证测试数据集的完整性,每次跑单个测试方法之前都重置表里面的数据:
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest(classes = Ch10Application.class)
public class CustomerDaoTest {
@Autowired
private CustomerDao customerDao;
@Autowired
private ObjectMapper objectMapper;
private String toJsonString(Object o) {
try {
return objectMapper.writeValueAsString(o);
} catch (Exception ignore) {
}
return null;
}
// 每个实例方法执行前插入9条数据
@Before
public void setUp() throws Exception {
for (int i = 1; i < 10; i++) {
Customer newCustomer = new Customer();
newCustomer.setFirstName("张");
newCustomer.setLastName(i + "狗");
newCustomer.setAge(10 + i);
Customer result = customerDao.saveAndFlush(newCustomer);
log.info("保存{}成功...", result);
}
}
// 每个实例方法执行后清空表数据
@After
public void tearDown() throws Exception {
customerDao.deleteAll();
}
......省略其他测试方法
}
「测试queryByAgeBetween:」
@Test
public void queryByAgeBetween() {
// SQL模板:select [封装别名的子句] from customer customer0_ where customer0_.age between ? and ?
List customers = customerDao.queryByAgeBetween(11, 13);
log.info("queryByAgeBetween,result:{}", toJsonString(customers));
Assert.assertEquals(11, (long) customers.get(0).getAge());
Assert.assertEquals(13, (long) customers.get(customers.size() - 1).getAge());
}
「测试queryByFirstName:」
@Test
public void queryByFirstName() {
// 这里好神奇,分页Pageable的page从0开始,不是认知中的1
// SQL模板:select [封装别名的子句] from customer customer0_ where customer0_.first_name=? limit ?, ?
List customers = customerDao.queryByFirstName("张", PageRequest.of(1, 4));
log.info("queryByFirstName,result:{}", toJsonString(customers));
Assert.assertEquals(4, customers.size());
for (Customer customer : customers) {
Assert.assertEquals("张", customer.getFirstName());
}
}
「测试queryTop5ByFirstName:」
@Test
public void queryTop5ByFirstName() {
// SQL模板:select [封装别名的子句] from customer customer0_ where customer0_.first_name=? limit ?
List customers = customerDao.queryTop5ByFirstName("张");
log.info("queryTop5ByFirstName,result:{}", toJsonString(customers));
Assert.assertEquals(5, customers.size());
for (Customer customer : customers) {
Assert.assertEquals("张", customer.getFirstName());
}
}
「测试countByFirstName:」
@Test
public void countByFirstName() {
// SQL模板:select count(customer0_.id) as col_0_0_ from customer customer0_ where customer0_.first_name=?
Assert.assertEquals(9L, customerDao.countByFirstName("张"));
}
「测试findByFirstNameContaining:」
@Test
public void findByFirstNameContaining() {
// SQL模板:select [封装别名的子句] from customer customer0_ where customer0_.first_name like ? escape ?
Streamable stream = customerDao.findByFirstNameContaining("张");
List customers = stream.stream().collect(Collectors.toList());
Assert.assertEquals(9, customers.size());
for (Customer customer : customers) {
Assert.assertEquals("张", customer.getFirstName());
}
}
「测试findByLastNameContaining:」
@Test
public void findByLastNameContaining() {
// SQL模板:select [封装别名的子句] from customer customer0_ where customer0_.last_name like ? escape ?
Streamable stream = customerDao.findByLastNameContaining("狗");
List customers = stream.stream().collect(Collectors.toList());
Assert.assertEquals(9, customers.size());
for (Customer customer : customers) {
Assert.assertEquals("张", customer.getFirstName());
}
}
「测试findTop1ByFirstName:」
@Test
public void findTop1ByFirstName() throws Exception {
// SQL模板:select [封装别名的子句] from customer customer0_ where customer0_.first_name=? limit ?
Future future = customerDao.findTop1ByFirstName("张");
Assert.assertNotNull(future.get());
Assert.assertEquals(future.get().getFirstName(), "张");
}
「测试findOneByFirstName:」
@Test
public void findOneByFirstName() throws Exception {
// SQL模板:select [封装别名的子句] from customer customer0_ where customer0_.first_name=? limit ?
CompletableFuture> future = customerDao.findOneByFirstName("张", PageRequest.of(0, 1));
List customers = future.get();
Assert.assertNotNull(customers);
Assert.assertEquals(1, customers.size());
Assert.assertEquals(customers.get(0).getFirstName(), "张");
}
「测试findOneByLastName:」
@Test
public void findOneByLastName() throws Exception {
ListenableFuture future = customerDao.findOneByLastName("1狗", PageRequest.of(0, 1));
Assert.assertNotNull(future.get());
Assert.assertEquals(future.get().getFirstName(), "张");
}
最后两个方法findOneByFirstName和findOneByLastName需要注意,这里的方法命名其实不规范,如果包含findOneXX或者queryOneYY则严格要求查询的结果集必须只包含一个目标对象实例,另外,如果入参中包含了分页参数Pageable的实例,则方法返回的结果必须是集合类型(List)。
小结
JPA提供了完整的ORM功能,一般称为"全自动SQL",比起需要完全编写SQL的JDBC驱动或者"半自动SQL"的MyBatis来说,开发效率确实会比较高,对于不喜欢编写SQL的开发者真是一大福音。而由于JPA提供了高层次的API封装,有些比较新的特性是可以尝鲜的,例如可以结合@Async注解返回Future实例还有流式查询,然而它的执行效率肯定要比更低层次的面向SQL编码的框架低。当然,JPA也提供了编写原生SQL的API。至于选用全自动SQL、半自动SQL还是完全的面向JDBC开发,取决于对开发效率和性能的权衡,「选择没有对错,只有是否更加合适」。
(本文完 c-3-d e-a-20200818 最近加班很忙,很久没更新了,没办法的鸽了)