Python3从零开始爬取今日头条的新闻【一、开发环境搭建】
Python3从零开始爬取今日头条的新闻【二、首页热点新闻抓取】
Python3从零开始爬取今日头条的新闻【三、滚动到底自动加载】
Python3从零开始爬取今日头条的新闻【四、模拟点击切换tab标签获取内容】
Python3从零开始爬取今日头条的新闻【五、解析头条视频真实播放地址并自动下载】
所谓爬虫,就是通过编程的方式自动从网络上获取自己所需的资源,比如文章、图片、音乐、视频等多媒体资源。通过一定的方式获取到html的内容,再通过各种手段分析得到自己所需的内容,比如通过BeautifulSoup对网页内容进行解析提取。
本文通过selenium的webdriver模拟浏览器来浏览网页,通过lxml库解析得到咱所需的内容。下面开始我们的爬虫工作。
本文目录:
- 1.头条首页内容分析
- ① 视频类型的html内容
- ②③ 纯文本类型的html内容
- ④ 图文类型的html内容
- ⑤ 多图类型的html内容
- 2.代码编写
- 2.1、编写程序主入口代码
- 2.1.1初始化火狐浏览器插件
- 2.1.2获取头条首页html内容
- 2.1.3分析首页html内容得到新闻所在li布局
- 2.2、编写解析具体新闻的代码
- 2.2.1、自定义新闻信息
- 2.2.2、解析新闻内容
- 2.2.2.1、新闻html内容分类判断
- 2.2.2.2、解析纯文本类型新闻
- 2.2.2.3、解析单图文类型新闻
- 2.2.2.4、解析多图文类型新闻
- 2.2.2.5、解析纯视频类型新闻
- 2.1、编写程序主入口代码
- 参考资料:
1.头条首页内容分析
我们今天的目标是提取头条中间区域的要闻内容:标题、图片、作者、类型、发布时间
首先,我们分析一下头条新闻页面的内容,用火狐浏览器打开头条首页,查看中间区域的热文内容

如上图所示,我们要抓取首页热文的中间区域新闻,一共有4种类型:
- ① 视频类型 → 左侧有图片,右侧是标题,点击可播放
- ②③ 纯文本类型 → 左侧没图片,中间是标题
- ④ 图文类型 → 左侧有图片,右侧是标题
- ⑤ 多图类型 → 上面是标题,下面是多张图片罗列
- 如果要抓取其它类型 ,原理也是一样的,万变不离其宗~
看上图右侧的dom元素结构,可以看出来,中间区域的每一条热文,都是在li标签包着的,而所有的li标签都是ul的子元素。
① 视频类型的html内容
<li class="">
<div getuser-info-url="/user/info/" class="bui-box video-mode">
<div class="bui-left video-mode-lbox">
<div style="width: 325px; height: 183px;" class="player mini-btn-visible transitionable" oncontextmenu="return false">
<div class="before"><img lazy="loaded" src="//p3.pstatp.com/list/300x170/pgc-image/1537883970674d7092c5d6d"
alt=""> <span class="play-btn"><i style="font-size: 30px; color: rgb(255, 255, 255);" class="bui-icon icon-playvedio">i>span>
<span class="duration"><i style="font-size: 8px;" class="bui-icon icon-playvedio">i><em>00:33em>span>div>
<div class="player-wrap">
<div class="player-inner" id="tt_video_17330">div>
<div class="action-line"><i style="font-size: 18px;" class="bui-icon icon-close_small">i> <span>按住该区域可拖动小窗span>div>
div>
<div style="display: none;" class="next">
<div style="display: none;" class="next-one">
<p class="info">接下来播放p>
<h3 class="title">h3> <i><img alt="" src="" height="78" width="78">i>
<div><i class="cancel">取消播放i>div>
div>
<div style="display: none;" class="next-list">
<ul>ul>
<div class="replay-wrap"><i class="replay">重播i>div>
div>
div>
div>
div>
<div class="video-mode-rbox">
<div class="title-box" ga_event="video_title_click"><a class="link" target="_blank" href="/group/6605161411674898947/">「独家V观」***在黑龙江考察
首站来到建三江a>div>
<div class="bui-box footer-bar"><a class="footer-bar-action media-avatar" ga_event="video_avatar_click"
target="_blank" href="/c/user/96888584941/"><img lazy="loaded" src="//p3.pstatp.com/large/6ee500006a1b9c777420">a>
<a class="footer-bar-action source" ga_event="video_name_click" target="_blank" href="/c/user/96888584941/">央视新闻移动网a>
<span class="footer-bar-action">⋅span> <a class="footer-bar-action source" ga_event="video_frequency_click"
target="_blank" href="/group/6605161411674898947/">7238次播放a>div>
<div class="action-dislike" ga_event="dislike_click"><i style="font-size: 16px; color: rgb(221, 221, 221);"
class="bui-icon icon-close_small">i>
不感兴趣
div>
div>
div>
li>
从dom元素结构可以看到我们所需的标题、图片、类型等内容
②③ 纯文本类型的html内容
<li class="">
<div class="no-mode" ga_event="article_item_click">
<div class="title-box" ga_event="article_title_click"><a class="link" target="_blank" href="/group/6605095646191944196/">国家主席***任免驻外大使a>div>
<div class="bui-box footer-bar">
<div class="bui-left footer-bar-left"><a class="footer-bar-action tag tag-style-other" ga_event="article_tag_click"
target="_blank" href="search/?keyword=%E6%97%B6%E6%94%BF">时政a> <a class="footer-bar-action media-avatar"
ga_event="article_avatar_click" target="_blank" href="/c/user/4377795668/"><img lazy="loaded" src="//p2.pstatp.com/large/3658/7378365093">a>
<a class="footer-bar-action source" ga_event="article_name_click" target="_blank" href="/c/user/4377795668/"> 新华网 ⋅a>
<a class="footer-bar-action source" ga_event="article_comment_click" target="_blank" href="/group/6605095646191944196//#comment_area"> 52评论 ⋅a>
<span class="footer-bar-action"> 38分钟前span>
div>
<div class="bui-right">
<div dislikeurl="/api/dislike/" class="action-dislike" ga_event="dislike_click"><i style="font-size: 16px; color: rgb(221, 221, 221);"
class="bui-icon icon-close_small">i>
不感兴趣
div>
div>
div>
div>
li>
④ 图文类型的html内容
<li class="">
<div class="bui-box single-mode" ga_event="article_item_click">
<div class="bui-left single-mode-lbox" ga_event="article_img_click"><a class="img-wrap" target="_blank" href="/group/6605101139232817678/"><img
lazy="loaded" src="//p98.pstatp.com/list/190x124/pgc-image/15378695822600023b5e56b" class="lazy-load-img">
a>div>
<div class="single-mode-rbox">
<div class="single-mode-rbox-inner">
<div class="title-box" ga_event="article_title_click"><a class="link" target="_blank" href="/group/6605101139232817678/">一旦爆发冲突,美国航母被击沉损失有多大?兰德公司公布答案a>div>
<div class="bui-box footer-bar">
<div class="bui-left footer-bar-left"><a class="footer-bar-action tag tag-style-other" ga_event="article_tag_click"
target="_blank" href="news_military">军事a> <a class="footer-bar-action media-avatar"
ga_event="article_avatar_click" target="_blank" href="/c/user/6398208487/"><img lazy="loaded"
src="//p3.pstatp.com/large/78f000a6e8e1a98cf54">a> <a class="footer-bar-action source"
ga_event="article_name_click" target="_blank" href="/c/user/6398208487/"> 全球军事热评 ⋅a>
<a class="footer-bar-action source" ga_event="article_comment_click" target="_blank" href="/group/6605101139232817678//#comment_area"> 100评论 ⋅a>
<span class="footer-bar-action"> 41分钟前span>
div>
<div class="bui-right">
<div dislikeurl="/api/dislike/" class="action-dislike" ga_event="dislike_click"><i style="font-size: 16px; color: rgb(221, 221, 221);"
class="bui-icon icon-close_small">i>
不感兴趣
div>
div>
div>
div>
div>
div>
li>
⑤ 多图类型的html内容
<li class="">
<div class="more-mode" ga_event="gallery_item_click">
<div class="title-box" ga_event="gallery_title_click"><a class="link" target="_blank" href="/group/6604959967424283150/">老人带村民历时36年,系绳索悬崖上开凿9公里水渠,几次差点送命a>div>
<div class="bui-box img-list" ga_event="gallery_img_click"><a class="img-wrap img-item" target="_blank" href="/group/6604959967424283150/"><img
lazy="loaded" src="//p3.pstatp.com/list/190x124/pgc-image/15378317404774aecf17a3c" class="lazy-load-img">a><a
class="img-wrap img-item" target="_blank" href="/group/6604959967424283150/"><img lazy="loaded" src="//p1.pstatp.com/list/190x124/pgc-image/1537831740473c836263103"
class="lazy-load-img">a><a class="img-wrap img-item" target="_blank" href="/group/6604959967424283150/"><img
lazy="loaded" src="//p1.pstatp.com/list/190x124/pgc-image/15378326628551660c762d3" class="lazy-load-img">a><a
class="img-wrap img-item" target="_blank" href="/group/6604959967424283150/"><img lazy="loaded" src="//p9.pstatp.com/list/190x124/pgc-image/1537831741249b93def511b"
class="lazy-load-img">a>
<i class="pic-tip"><span>15图span>i>div>
<div class="bui-box footer-bar">
<div class="bui-left footer-bar-left"><a class="footer-bar-action tag tag-style-society" ga_event="article_tag_click"
target="_blank" href="news_society">社会a> <a class="footer-bar-action media-avatar" ga_event="gallery_avatar_click"
target="_blank" href="/c/user/5921344817/"><img lazy="loaded" src="//p1.pstatp.com/large/249a0015871d8abbdf27">a>
<a class="footer-bar-action source" ga_event="gallery_name_click" target="_blank" href="/c/user/5921344817/"> 乙图 ⋅a>
<a class="footer-bar-action source" ga_event="gallery_comment_click" target="_blank" href="/group/6604959967424283150//#comment_area"> 234评论 ⋅a>
<span class="footer-bar-action"> 2小时前span>
div>
<div class="bui-right">
<div dislikeurl="/api/dislike/" class="action-dislike" ga_event="dislike_click"><i style="font-size: 16px; color: rgb(221, 221, 221);"
class="bui-icon icon-close_small">i>
不感兴趣
div>
div>
div>
div>
li>
从上面四种类型新闻的布局可以看出,每个
li标签的class属性都是空的,li的子元素就只有一个子元素div,并且这个div有个ga_event属性,我们分析下各种类型新闻的li的直接子元素的div布局:1:
纯文本类型、图文类型,这个ga_event属性值均为article_item_click,但这两种类型的class属性值不一样,图文类型的是bui-box single-mode,纯文本类型的是no-mode
2:视频类型,没有ga_event属性,有个属性值为==/user/info/的 getuser-info-url属性,而class属性值为bui-box video-mode==
3:多图类型,这个ga_event属性值为gallery_item_click,class属性值为more-mode
所以我们可以根据以上分析的各种类型布局的特点,来找出每一条新闻的元素结构,再通过XPATH定位得到我们所需要的标题、图片、类型、作者、时间等内容。
思路有了,那我们就开搞吧~
2.代码编写
2.1、编写程序主入口代码
我们来看主入口部分代码:
# -*- coding: utf-8 -*-
# 引入模拟浏览器框架支持库
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 引入ActionChains鼠标操作类支持库
from selenium.webdriver.common.action_chains import ActionChains
# xpath解析支持库
from lxml import etree
# 自定义的新闻结构体
from newsInfo import NewsInfo
# 自定义解析html结构的实现类
from parseNews import PaseNews
class ParseTouTiao(object):
"""
构造函数,初始化资源
"""
def __init__(self):
self.__firefox_options = webdriver.FirefoxOptions()
self.__firefox_options.add_argument('--headless')
self.__firefox_options.add_argument('--disable-gpu')
self.__browser = webdriver.Firefox(firefox_options=self.__firefox_options)
"""
获取头条首页内容
"""
def __getTouTiaoHtml(self, url):
# 简单的入参校验
if url and '' != url and url.startswith("http"):
# 浏览器打开页面
self.__browser.get(url)
try:
# 此处等到我们所需的热文元素加载出来了再进行下一步,避免页面还没加载完成就去解析内容导致内容为空
element = WebDriverWait(self.__browser, 10).until(
EC.presence_of_element_located((By.XPATH, "//ul/li/div[@ga_event=article_item_click]"))
)
except Exception as ex:
print(ex)
finally:
pass
resHtml = self.__browser.page_source
return resHtml
"""
提取li标签内容
"""
def _parseNews(self, url):
resHtml = self.__getTouTiaoHtml(url)
if not resHtml:
print("解析内容出错")
return
# 转换为etree解析模式内容
etree_html = etree.HTML(resHtml)
# 通过前面对每条新闻dom结构分析,由xpath方式提取所有新闻所在的布局
li_elements = etree_html.xpath('//ul[@infinite-scroll-immediate-check][@infinite-scroll-immediate-check-count="containerCheckCount"]/li')
# 解析得到的新闻列表
parseNewsInfo = []
# 新闻解析类
parseNew = PaseNews()
if li_elements and len(li_elements) > 0:
for li in li_elements:
newinf = parseNew.parse(li)
# 省略部分代码......
else:
return
# 省略部分代码......
代码的注释很清楚,简要介绍下几个方法:
2.1.1初始化火狐浏览器插件
__init__方法:初始化火狐浏览器插件属性,其中下面三行代码设置火狐浏览器调用时,不显示浏览器的界面,如果你想看到浏览器的自动化操作行为,你可以在实例化browser时不传这个self.__firefox_options参数即可
self.__firefox_options.add_argument('--headless')
self.__firefox_options.add_argument('--disable-gpu')
self.__browser = webdriver.Firefox(firefox_options=self.__firefox_options)
2.1.2获取头条首页html内容
__getTouTiaoHtml (self, url)方法:通过selenium的webdriver调用火狐浏览器打开头条首页,并且等到页面加载出来内容后再进行下一步。
def __getTouTiaoHtml(self, url):
# 简单的入参校验
if url and '' != url and url.startswith("http"):
# 浏览器打开页面
self.__browser.get(url)
try:
# 此处等到我们所需的热文元素加载出来了再进行下一步,避免页面还没加载完成就去解析内容导致内容为空
element = WebDriverWait(self.__browser, 10).until(
EC.presence_of_element_located((By.XPATH, "//ul/li/div[@ga_event=article_item_click]"))
)
except Exception as ex:
print(ex)
finally:
pass
resHtml = self.__browser.page_source
return resHtml
其中通过 WebDriverWait 同步等待的方法来保证页面加载出来我们所需的内容了,再进行下一步。最后返回的内容self.__browser.page_source就是我们下一步分析新闻所需的HTML内容了,形式如下所示:
<html>
<head>
<meta charset="utf-8">
<title>今日头条title>
<meta http-equiv="x-dns-prefetch-control" content="on">
<meta name="renderer" content="webkit">
<meta name="keywords" content="今日头条,头条,头条网,头条新闻,今日头条官网">
<meta name="description" content="《今日头条》(www.toutiao.com)是一款基于数据挖掘的推荐引擎产品,它为用户推荐有价值的、个性化的信息,提供连接人与信息的新型服务,是国内移动互联网领域成长最快的产品服务之一。">
head>
<body>
<div>
......
div>
body>
html>
2.1.3分析首页html内容得到新闻所在li布局
def _parseNews(self, url):
resHtml = self.__getTouTiaoHtml(url)
if not resHtml:
print("解析内容出错")
return
# 转换为etree解析模式内容
etree_html = etree.HTML(resHtml)
# 通过前面对每条新闻dom结构分析,由xpath方式提取所有新闻所在的布局
li_elements = etree_html.xpath('//ul[@infinite-scroll-immediate-check][@infinite-scroll-immediate-check-count="containerCheckCount"]/li')
# 解析得到的新闻列表
parseNewsInfo = []
# 新闻解析类
parseNew = PaseNews()
if li_elements and len(li_elements) > 0:
for li in li_elements:
newinf = parseNew.parse(li)
if newinf:
parseNewsInfo.append(newinf)
print(" 标题:'%s'\n 图片:'%s'\n 作者:'%s'\n 类型:'%s'\n 时间:'%s'\n 布局:'%s'\n" % (newinf.title, newinf.imgurl, newinf.author, newinf.category,newinf.publish_time, newinf.news_type.value))
else:
return
函数_parseNews从获取到的整个html页面内容中,根据前面的分析所知我们的目标新闻内容都是在里面,根据这个规律,我们先把整个页面格式化为lxml格式:etree_html = etree.HTML(self.resHtml),然后通过xpath路径选择出我们所有的li元素:
li_elements = etree_html.xpath('//ul[@infinite-scroll-immediate-check][@infinite-scroll-immediate-check-count="containerCheckCount"]/li')
咱好好说道说道这个xpath的用法,后续核心工作都是通过它来帮助我们完成的。
xpath() 的参数,前后用单引号包起来,//双斜杠开头,表示从整个文档任何位置,只要能匹配到就行。根据我们之前对首页元素的分析,只会有一个元素,所以我们etree_html.xpath('//ul)这么写,只会找到这一个,而不必关系它的父级、祖父级等到底有多少层,每层又是什么标签~
当然这里为了严谨点,还在ul后面加了个限制符:[@infinite-scroll-immediate-check],限制符放在中括号[]里面,@后面加标签的属性名,比如[@class="title"],表示当前元素必须要有class属性,并且属性值等于title,如果我们不关心属性的值,只需要有这个属性就行了,那么直接写[@属性名]。
对属性的限定,除了通过等号=,还可以通过contains(表示属性值必须包含xxx)、starts-with(表示属性值必须以xxx开头),举个例子:
我要查找某个包含title属性,并且title的值包含group的a标签内容,可以这么写:xxx.xpath('//a[contains(@title, "group")]')
我要查找某个包含title属性,并且title的值以item-click开头的div标签内容,可以这么写:xxx.xpath('//div[starts-with(@title, "item-click")]')
记住:xxx.xpath()返回的要么是None,要么是list,即使只找到一个符合要求的,也是返回一个list(只有一个元素,可以通过==[0]== 下标得到这个元素)
2.2、编写解析具体新闻的代码
2.2.1、自定义新闻信息
我们从主入口的代码可以看到引入了两个自定义的类:
# 自定义的新闻结构体
from newsInfo import NewsInfo
# 自定义解析html结构的实现类
from parseNews import PaseNews
其中NewsInfo是存储我们解析出来的新闻内容结构,具体代码如下
# -*- coding: utf-8 -*-
from enum import Enum, unique
@unique
class NewsType(Enum):
TextType = '纯文本类型'
SingleImageType = '图文类型'
MultipleImageType = '多图类型'
VideoType = '视频类型'
class NewsInfo:
# 标题
title = ''
# 作者
author = ''
# 分类
category = ''
# 发表时间
publish_time = ''
# 图片url
imgurl = []
# 详情url
detail_link = ''
news_type = NewsType.TextType
2.2.2、解析新闻内容
而另一个PaseNews 类则是我们解析新闻html结构的核心类,具体代码如下:
2.2.2.1、新闻html内容分类判断
def parse(self, li_etree):
newsInfo = None
# 获取当前新闻类型
if li_etree.xpath('./div[@class="no-mode"]'):
# 纯文本类型
newsInfo = self.__parseTextNew(li_etree)
elif li_etree.xpath('./div[contains(@class, "single-mode")][contains(@class, "bui-box")]'):
# 单图片类型
newsInfo = self.__parseImageNew(li_etree)
elif li_etree.xpath('./div[@class="more-mode"][@ga_event="gallery_item_click"]'):
# 多图片类型
newsInfo = self.__parseImageListNew(li_etree)
elif li_etree.xpath('./div[contains(@class, "video-mode")]'):
# 视频类型
newsInfo = self.__parseVideoNew(li_etree)
return newsInfo
上面的parse函数,接收的参数是前面主入口拿到的整个html页面内容,经过分析得到的每一个li元素结构, 针对每一个li元素,通过前面的分析判断出它是哪种类型的新闻,然后单独调用相应的方法解析得到新闻内容
2.2.2.2、解析纯文本类型新闻
我们先看纯文本类型的html元素结构:
<li class="">
<div class="no-mode" ga_event="article_item_click">
<div class="title-box" ga_event="article_title_click"><a class="link" target="_blank" href="/group/6605095646191944196/">国家主席***任免驻外大使a>div>
<div class="bui-box footer-bar">
<div class="bui-left footer-bar-left"><a class="footer-bar-action tag tag-style-other" ga_event="article_tag_click"
target="_blank" href="search/?keyword=%E6%97%B6%E6%94%BF">时政a> <a class="footer-bar-action media-avatar"
ga_event="article_avatar_click" target="_blank" href="/c/user/4377795668/"><img lazy="loaded" src="//p2.pstatp.com/large/3658/7378365093">a>
<a class="footer-bar-action source" ga_event="article_name_click" target="_blank" href="/c/user/4377795668/"> 新华网 ⋅a>
<a class="footer-bar-action source" ga_event="article_comment_click" target="_blank" href="/group/6605095646191944196//#comment_area"> 52评论 ⋅a>
<span class="footer-bar-action"> 38分钟前span>
div>
<div class="bui-right">
<div dislikeurl="/api/dislike/" class="action-dislike" ga_event="dislike_click"><i style="font-size: 16px; color: rgb(221, 221, 221);"
class="bui-icon icon-close_small">i>
不感兴趣
div>
div>
div>
div>
li>
python解析的代码如下:
"""
解析纯文本类型新闻
"""
def __parseTextNew(self, li_etree):
new_info = NewsInfo()
# 获取标题
new_info.title = li_etree.xpath('./div[@class="no-mode"]/div[1]/a/text()')[0]
# 获取详情的相对地址
new_info.detail_link = li_etree.xpath('./div[@class="no-mode"]/div[1]/a/@href')[0]
# 获取新闻作者
new_info.author = li_etree.xpath('./div[@class="no-mode"]/div[2]/div[1]/a[contains(@class, "source")][starts-with(@href, "/c/user/")]/text()')[0].replace("⋅", '').strip()
# 获取新闻发布时间
new_info.publish_time = li_etree.xpath('./div[@class="no-mode"]/div[2]/div[1]/span[@class="footer-bar-action"]/text()')[0].strip()
# 获取新闻类型
category = li_etree.xpath('./div[@class="no-mode"]/div[2]/div[1]/a[@ga_event="article_tag_click"]/text()')
# 不一定有这个字段
if category and len(category) > 0:
new_info.category = category[0]
# 新闻布局类型
new_info.news_type = NewsType.TextType
return new_info
简单说下,获取标题,
new_info.title = li_etree.xpath('./div[@class="no-mode"]/div[1]/a/text()')[0]
传入来的已经是一个单独的li结构了,xpath里面的路径选择以./开头,表示从当前级别开始查找,查找class属性值为no-mode的div,然后 紧跟着的/div[1]再继续找刚才定位到的这个div的下一级子元素中的div的第一个,然后继续查找这个传入的li标签下的第二级div下面的a标签,最后获取这个a标签的字符串内容,注意,返回的是一个list,虽然这里最终只能定位到一个元素但仍然返回list形式,所以最后通过[0]下标引用得到这个标题字符串.
2.2.2.3、解析单图文类型新闻
参考上面2.2.2.1的分析思路,再不行就看本文源码,在本文最后那里下载
2.2.2.4、解析多图文类型新闻
参考上面2.2.2.1的分析思路,再不行就看本文源码,在本文最后那里下载
2.2.2.5、解析纯视频类型新闻
参考上面2.2.2.1的分析思路,再不行就看本文源码,在本文最后那里下载
最后,看下咱的成果如何 ↓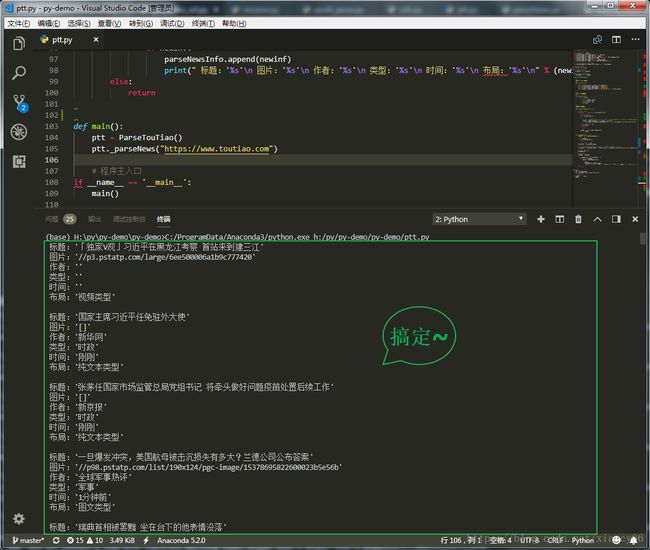
本文完整代码 →:下载地址
注意,上面下载的源码,为了测试方便,写死了静态html内容来解析演示的按照下图修改后可以正常解析线上的内容…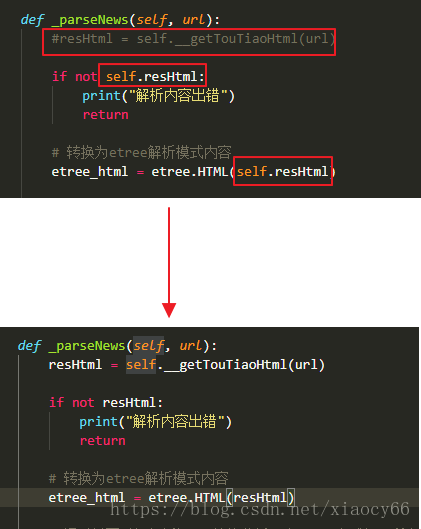
全文完结,后续实现用其它框架来爬虫新闻资源。敬请期待~
Python3从零开始爬取今日头条的新闻【一、开发环境搭建】
Python3从零开始爬取今日头条的新闻【二、首页热点新闻抓取】
Python3从零开始爬取今日头条的新闻【三、滚动到底自动加载】
Python3从零开始爬取今日头条的新闻【四、模拟点击切换tab标签获取内容】
Python3从零开始爬取今日头条的新闻【五、解析头条视频真实播放地址并自动下载】
参考资料:
[1]: XPath语法参考
[2]: 廖雪峰老师的Python3 在线学习手册
[3]: Python3官方文档
[4]: 菜鸟学堂-Python3在线学习
[5]: 其他所有分享过python学习填坑网友的经验