周志华教授专著《集成学习:基础与算法》上市,破解AI实践难题

[ 摘要 ]《集成学习:基础与算法》上市一周,斩获京东IT新书销量榜第一名桂冠,并拿下京东IT图书销量总榜第二名的惊人成绩。
文中有数据派独家福利哦
本书共读活动已正式开启,文末加入读者交流群,一起组队学习,效率翻倍!
集成学习方法是一类先进的机器学习方法,这类方法训练多个学习器并将它们结合起来解决一个问题,在实践中获得了巨大成功,并成为机器学习领域的“常青树”,受到学术界和产业界的广泛关注。
本文选自周志华教授专著《集成学习:基础与算法》,带你进一步了解集成学习方法及应用。
集成学习方法
和传统学习方法训练一个学习器不同,集成学习方法训练多个学习器并结合它们来解决一个问题。通常,集成学习也被称为基于委员会的学习(committee-based learning)或多分类器系统(multiple classifier system)。
下图为一个通用的集成学习框架。
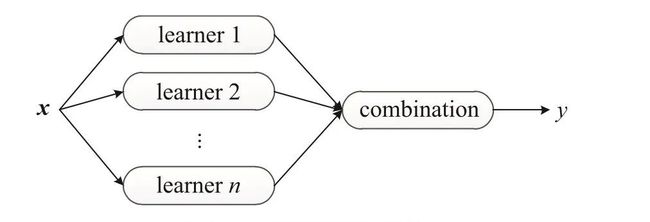
一个集成由多个基学习器(base learner)构成,而基学习器由基学习算法(base learning algorithm)在训练数据上训练获得,它们可以是决策树、神经网络或其他学习算法。
大多数集成学习方法使用同一种基学习算法产生同质的基学习器,即相同种类的学习器,生成同质集成(homogeneous ensemble);同时,也有一些方法使用多种学习算法训练不同种类的学习器,构建异质集成(heterogeneous ensemble)。在异质集成中,由于没有单一的基学习算法,相较于基学习器,人们更倾向于称这些学习器为个体学习器(individual learner)或组件学习器(component learner)。
通常,集成具有比基学习器更强的泛化能力。实际上,集成学习方法之所以那么受关注,很大程度上是因为它们能够把比随机猜测稍好的弱学习器(weak learner)变成可以精确预测的强学习器(strong learner)。因此,在集成学习中基学习器也称为弱学习器。
由于使用多个模型解决问题的思想在人类社会中有悠久的历史,我们难以对集成学习方法的历史进行溯源。例如,作为科学研究的基本假设,当简单假设和复杂假设都符合经验观测时,奥卡姆剃刀(Occam’s razor)准则偏好简单假设;但早在此之前,希腊哲学家伊壁鸠鲁(Epicurus,公元前 341—270)提出的多释准则(principle of multiple explanations)[Asmis,1984] 主张应该保留和经验观测符合的多个假设。
集成学习领域的发展得益于三个方面的早期研究,即:分类器结合、弱分类器集成和混合专家模型(mixture of experts)。
分类器结合主要来自模式识别领域。这方面的研究关注强分类器,试图设计强大的结合规则来获取更强的结合分类器,在设计和使用不同的结合规则上积累深厚。
弱分类器集成方面的研究主要集中在机器学习领域。这方面的研究关注弱分类器,试图设计强大的算法提升弱分类器的效果,产生了包括 AdaBoost 和 Bagging 等众多著名的集成学习算法,并且在将弱学习器提升为强学习器方面有深入的理论理解。
混合专家模型的研究主要集中在神经网络领域。在此,人们通常考虑使用分而治之的策略来共同学习一组模型,并结合使用它们获得一个总体解决方案。
20 世纪 90 年代以来,集成学习方法逐渐成为一个主要的学习范式,这主要得益于两项先驱性工作。其中,[Hansen & Salamon,1990] 是实验方面的工 作, 如下图,它指出一组分类器的集成经常会产出比其中最优个体分类 器更精准的预测;
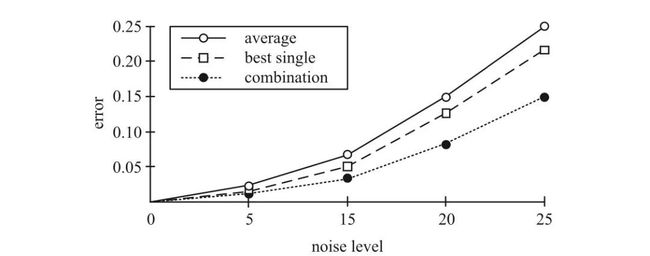
集成通常比最优个体学习器更准确,其中横坐标为噪声水平(noise level),纵坐标为分类错误率(error),三种对比方法分别为平均法(average)、最优个体法(best single)和结合方法(combination)[Hansen & Salamon,1990]
[Schapire,1990] 是理论方面的工作,它构造性地证明了弱学习器可以被提升为强学习器。虽然我们所需的高精度学习器难以训练,但弱学习器在实践中却容易获得,这个理论结果为使用集成学习方法获得强学习器指明了方向。
一般来讲,构建集成有两个步骤:首先产生基学习器,然后将它们结合起来。为了获得一个好的集成,通常认为每个基学习器应该尽可能准确,同时尽可能不同。
值得一提的是,构建一个集成的计算代价未必会显著高于构建单一学习器。这是因为使用单一学习器时,模型选择和调参经常会产生多个版本的模型,这与在集成学习中构建多个基学习器的代价是相当的;同时,由于结合策略一般比较简单,结合多个基学习器通常只会花费很低的计算代价。
集成学习方法的应用
KDD Cup 作为最著名的数据挖掘竞赛,自 1997 年以来每年举办,吸引了全球大量数据挖掘队伍参加。竞赛包含多种多样的实际任务,如网络入侵检测(1999)、分子生物活性和蛋白质位点预测(2001)、肺栓塞检测(2006)、客户关系管理(2009)、教育数据挖掘(2010)和音乐推荐(2011)等。在诸多机器学习技术中,集成学习方法获得了高度的关注和广泛的使用。例如,在连续三年的 KDD Cup 竞赛中(2009—2011),获奖的冠军和亚军都使用了集成学习方法。
另一项著名的赛事 Netflix Prize 由 Netflix 公司举办。竞赛任务是基于用户的历史偏好提升电影推荐的准确度,如果参赛队伍能在 Netflix 公司自己的算法基础上提升 10% 的准确度,就能够获取百万美元大奖。2009 年 9 月 21 日,Nexflix 公司宣布,百万美元大奖由 BellKor’s Pragmatic Chaos 队获得,他们的方案结合了因子模型、回归模型、玻尔兹曼机、矩阵分解、k-近邻等多种模型。另外还有一支队伍取得了和获奖队伍相同的效果,但由于提交结果晚了 20 分钟无缘大奖,他们同样使用了集成学习方法,甚至使用“The Ensemble”作为队名。
除了在竞赛上获得显赫战绩,集成学习方法还被成功应用到多种实际应用中。实际上,在几乎所有的机器学习应用场景中都能发现它的身影。例如,计算机视觉的绝大部分分支,如目标检测、识别、跟踪,都从集成学习方法中受益。
基于 AdaBoost 和级联结构,Viola & Jones [2001,2004] 提出了一套通用的目标检测框架。Viola & Jones [2004] 显示在一台 466MHz 计算机上,人脸检 测器仅需 0.067 秒就可以处理 384×288 的图像,这几乎比当时最好的技术快 15倍,且具有基本相同的检测精度。在随后的十年间,这个框架被公认为计算机视觉领域最重大的技术突破。
Huang et al. [2000] 设计了一套集成学习方法解决姿态无关的人脸识别问题。它的基本思路是使用特殊设计的模型集成多个特定视角的神经网络模型。和需要姿态信息作为输入的传统方法相比,这个方法不需要姿态信息,甚至能在输出识别结果的同时输出姿态信息。Huang et al. [2000] 发现这个方法的效果甚至优于以完美姿态信息作为输入的传统方法。类似的方法后来被用于解决多视图人脸检测问题 [Li et al.,2001]。
目标跟踪的目的是在视频的连续帧中对目标对象进行连续标记。通过把目标检测看成二分类问题,并训练一个在线集成来区分目标对象和背景,Avidan [2007] 提出了集成跟踪(ensemble tracking)方法。该方法通过更新弱分类器来学习由于对象外观和背景发生的变化。Avidan [2007] 发现这套方法能处理多种 具有不同大小目标的不同类别视频,并且运行高效,能应用于在线任务。
在计算机系统中,用户行为会有不同的抽象层级,相关信息也会来自多个渠道,集成学习方法就非常适合于刻画计算机安全问题 [Corona et al.,[2009]。Giacinto et al. [2003] 使用集成学习方法解决入侵检测问题。考虑到有多种特征刻画网络连接,他们为每一种特征构建了一个集成,并将这些集成的输出结合 起来作为最终结果。Giacinto et al. [2003] 发现在检测未知类型的攻击时,集成学习方法能够获得最优的性能。此后,Giacinto et al. [2008] 提出了一种集成方法解决基于异常的入侵检测问题,该方法能够检测出未知类型的入侵。
恶意代码基本上可以分为三类:病毒、蠕虫和木马。通过给代码一个合适的表示,Schultz et al. [2001] 提出了一种集成学习方法用以自动检测以往未见的恶意代码。基于对代码的 n-gram 表示,Kolter & Maloof [2006] 发现增强决策树(boosted decision tree)能够获得最优的检测效果,同时他们表示这种方法可以在操作系统中检测未知类型的恶意代码。
集成学习方法还被应用于解决计算机辅助医疗诊断中的多种任务,尤其用于提升诊断的可靠性。周志华等人设计了一种双层集成架构用于肺癌细胞检测任务 [Zhou et al.,2002a],其中当且仅当第一层中的所有个体学习器都诊断为“良性”时才会预测为“良性”,否则第二层会在“良性”和各种不同的癌症类型间进行预测。他们发现双层集成方法能同时获得高检出率和低假阳性率。
对于老年痴呆症的早期诊断,以往的方法通常仅考虑来自脑电波的单信道数据。Polikar et al. [2008] 提出了一种集成学习方法来利用多信道数据;在此方法中,个体学习器基于来自不同电极、不同刺激和不同频率的数据进行训练,同时它 们的输出被结合起来产生最终预测结果。
除了计算机视觉、安全和辅助诊断,集成学习方法还被应用到多个其他领域和任务中。例如,信用卡欺诈检测 [Chan et al.,1999;Panigrahi et al.,2009],破产预测 [West et al.,2005],蛋白质结构分类 [Tan et al.,2003;Shen & Chou,2006],种群分布预测 [Araújo & New,2007],天气预报 [Maqsood et al.,2004;Gneiting & Raftery,2005],电力负载预测 [Taylor & Buizza,2002], 航空发动机缺陷检测 [Goebel et al.,2000;Yan & Xue,2008],音乐风格和艺 术家识别 [Bergstra et al.,2006] 等。
人工智能探索与实践丛书
《集成学习:基础与算法》

周志华 著 ,李楠 译
国内独本剖析集成学习的著作
▼立即加入本书交流群▼
参与共读活动,高效学习

数据派THU独家福利!
点点特意为数据派THU的粉丝争取了 3 本赠书福利!
欢迎小伙伴儿在下方留言区说出想要获得赠书的理由,我们将为点赞数最高的3位读者免费送上此书~红数点(微信ID:hongpingguo2016)会联系你们哦!
编辑:黄继彦
