Flume概述
Flume在大数据中扮演着数据收集的角色,收集到数据以后在通过计算框架进行处理。Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Flume架构和核心组件
Event的概念
在这里有必要先介绍一下flume中event的相关概念:flume的核心是把数据从数据源(source)收集过来,在将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume在删除自己缓存的数据。在整个数据的传输的过程中,流动的是event,即事务保证是在event级别进行的。那么什么是event呢?—–event将传输的数据进行封装,是flume传输数据的基本单位,如果是文本文件,通常是一行记录,event也是事务的基本单位。event从source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。
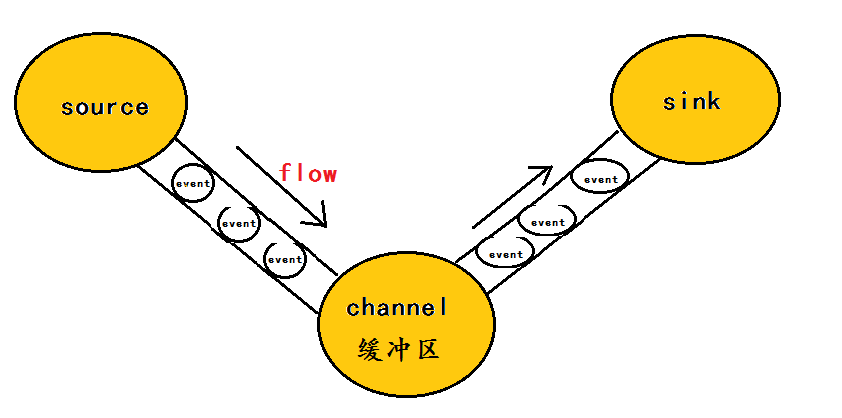
Flume架构
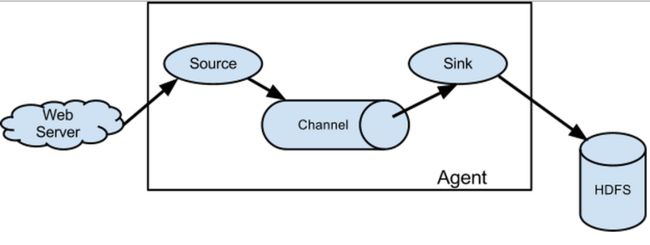
flume之所以这么神奇,是源于它自身的一个设计,这个设计就是agent,agent本身是一个java进程,运行在日志收集节点—所谓日志收集节点就是服务器节点。
agent里面包含3个核心的组件:source—->channel—–>sink,类似生产者、仓库、消费者的架构。
- source:source组件是专门用来收集数据的,可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy、自定义。
- channel:source组件把数据收集来以后,临时存放在channel中,即channel组件在agent中是专门用来存放临时数据的——对采集到的数据进行简单的缓存,可以存放在memory、jdbc、file等等。
- sink:sink组件是用于把数据发送到目的地的组件,目的地包括hdfs、logger、avro、thrift、ipc、file、null、hbase、solr、自定义。
flume的运行机制
flume的核心就是一个agent,这个agent对外有两个进行交互的地方,一个是接受数据的输入——source,一个是数据的输出sink,sink负责将数据发送到外部指定的目的地。source接收到数据之后,将数据发送给channel,chanel作为一个数据缓冲区会临时存放这些数据,随后sink会将channel中的数据发送到指定的地方—-例如HDFS等,注意:只有在sink将channel中的数据成功发送出去之后,channel才会将临时数据进行删除,这种机制保证了数据传输的可靠性与安全性。
flume的广义用法
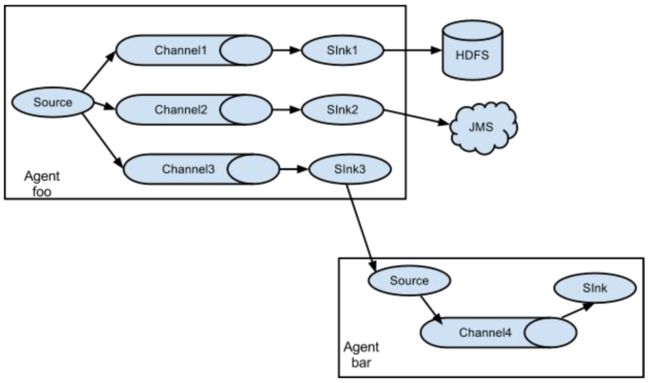
flume可以支持多级flume的agent,即flume可以前后相继,例如sink可以将数据写到下一个agent的source中,这样的话就可以连成串了,可以整体处理了。flume还支持扇入(fan-in)、扇出(fan-out)。所谓扇入就是source可以接受多个输入,所谓扇出就是sink可以将数据输出多个目的地destination中。
值得注意的是,Flume提供了大量内置的Source、Channel和Sink类型。不同类型的Source,Channel和Sink可以自由组合。组合方式基于用户设置的配置文件,非常灵活。比如:Channel可以把事件暂存在内存里,也可以持久化到本地硬盘上。Sink可以把日志写入HDFS, HBase,甚至是另外一个Source等等。Flume支持用户建立多级流,也就是说,多个agent可以协同工作,并且支持Fan-in、Fan-out、Contextual Routing、Backup Routes。如下图所示:
Flume环境搭建
前置条件
- Flume需要Java 1.7及以上(推荐1.8)。
- 足够的内存和磁盘空间。
- 对Agent监控目录的读写权限。
搭建
- 下载flume-ng-1.6.0-cdh5.7.0.tar.gz(下载地址http://archive.cloudera.com/cdh5/cdh/5/
),因为在前面大数据入门章节中(https://www.jianshu.com/p/10700514e3e0
)我们选择的是cdh5.7.0版本,所以现在也选择这个版本。 - 上传到服务器,并解压。
tar -zxvf flume-ng-1.6.0-cdh5.7.0.tar.gz -C ../apps/
- 配置环境变量。
vi ~/.bash_profile
//在文件中配置Flume的路径,根据自己安装的路径进行修改
export FLUME_HOME=/root/apps/apache-flume-1.6.0-cdh5.7.0-bin
export PATH=$FLUME_HOME/bin:$PATH
//使配置文件生效
source ~/.bash_profile
- 在flume-env.sh中配置Java JDK的路径。
cd $FLUME_HOME/conf
// 复制模板
cp flume-env.sh.template flume-env.sh
vi flume-env.sh
// 配置为安装的Java目录
export JAVA_HOME=/usr/jdk1.8.0_181
- 检测,在flume的bin目录下执行flume-ng version可查看版本。
cd $FLUME_HOME/bin
flume-ng version
出现以下内容,说明安装成功

Flume实战
使用flume的关键就是写配置文件。主要是以下四步:
- 配置Source
- 配置Channel
- 配置Sink
- 把以上三个组件串起来。
需求1:从指定网络端口采集数据输出到控制台
- 配置agent
#example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# a1: agent名称 r1: source的名称 k1:sink的名称 c1:channel的名称
# Describe/configure the source
a1.sources.r1.type = netcat #source的类型
a1.sources.r1.bind = localhost #source绑定的主机
a1.sources.r1.port = 44444 #source绑定的主机端口
# Describe the sink
a1.sinks.k1.type = logger #sink的类型
# Use a channel which buffers events in memory
a1.channels.c1.type = memory #channel的类型
a1.channels.c1.capacity = 1000 #通道中存储的最大event数
a1.channels.c1.transactionCapacity = 100 # 通道从源或提供给接收器的最大event数
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 #把source和channel做关联,其中属性是channels,说明sources可以和多个channel做关联。
a1.sinks.k1.channel = c1 #sink和channel做关联,只能输出到一个channel
- 在flume的conf目录下新建example.conf文件(目录和文件名可自定义,在后续启动agent时需要用到)。
vi example.conf
把配置好的agent配置复制到文件中
- 启动agent
flume-ng agent \
-- name a1 \ #指定agent的名称,在上面配置中我们配置的是a1
-- conf $FLUME_HOME/conf \ # flume的配置目录
-- conf-file $FLUME_HOME/conf/example.conf \ # agent配置的文件全路径
-- Dflume.root.logger=INFO,console #日志级别和输出形式
- 测试,可使用telnet到source关联的主机,在对应端口下输入字符,在控制台可以看到输入的字符。
案例2:监控一个文件实时采集新增的数据输出到控制台
- agent的选型:
exec source+memory channel +logger sink
agent配置:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec #source的类型
a1.sources.r1.command= tail -F /root/data/data.log #执行的命令
a1.sources.r1.shell = /bin/sh -c
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 启动agent
flume-ng agent --name a1 --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/exec-memory-logger.conf -Dflume.root.logger=INFO,console
- 测试:往监听的文件中输入数据,在控制台会打印event数据
echo hello >> data.log
如图可见Event = 可选的header + byte array
这里把数据输出到控制台没有任何意义,实际需求可能需要输出到hdfs之上,只需要改agent配置,把sink的类型改为hdfs,然后指定hdfs的url和写入的路径。
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec #source的类型
a1.sources.r1.command= tail -F /root/data/data.log #执行的命令
a1.sources.r1.shell = /bin/sh -c
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://192.168.30.130:8020/root/flume/hive-logs/
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.batchSize = 10
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
需求三:从服务器A收集数据到服务器B

重点:服务器A的Sink 类型是AVRO, 而 服务器 B的Source 是AVRO
流程:
- 机器A监控一个文件,把日志记录到data.log中
- avro sink把新产生的日志输出到指定的hostname和port上
- 通过avro source对应的agent将日志输出到控制台|Kafka|hdfs等
机器A配置
agentA.sources = r1
agentA.sinks = k1
agentA.channels = c1
# Describe/configure the source
agentA.sources.r1.type = exec
agentA.sources.r1.command= tail -F /root/data/data.log
agentA.sources.r1.shell = /bin/sh -c
# Describe the sink
agentA.sinks.k1.type = avro
agentA.sinks.k1.hostname = localhost
agentA.sinks.k1.port = 44444
# Use a channel which buffers events in memory
agentA.channels.c1.type = memory
# Bind the source and sink to the channel
agentA.sources.r1.channels = c1
agentA.sinks.k1.channel = c1
机器B配置
# Name the components on this agent
agentB.sources = avro-source
agentB.sinks = logger-sink
agentB.channels = memory-channel
# Describe/configure the source
agentB.sources.avro-source.type = avro
agentB.sources.avro-source.bind = localhost
agentB.sources.avro-source.port = 44444
# Describe the sink
agentB.sinks.logger-sink.type = logger
# Use a channel which buffers events in memory
agentB.channels.memory-channel.type = memory
# Bind the source and sink to the channel
agentB.sources.avro-source.channels = memory-channel
agentB.sinks.logger-sink.channel = memory-channel