GPU编程3--GPU内存深入了解
emsp; 我们在GPU的基本概念一节中,讲到过GPU中的内存模型,但那一节只是对模型的简单介绍,这一节,我们对GPU的内存进行更加深入的说明。
首先来回顾一下GPU中的内存:
- 每个线程都有自己的私有本地内存(Local Memory)和Resigter
- 每个线程都包含共享内存(Shared Memory),可以被线程中所有的线程共享,其生命周期与线程快一致
- 所有的线程都可以访问全局内存(Global Memory)
- 只读内存块:常量内存(Constant Memory)和纹理内存(Texture Memory)
- 每个SM有自己的L1 cache,SM通过L2 cache连接到Global Memory
内存访问速度
这一点跟CPU比较像,就是存储空间越大,访问速度越慢,GPU内存的访问速度从快到慢依次为:Registers->Caches->Shared Memory->Gloabl Memory。

Registers
寄存器是访问速度最快的空间,寄存器变量在程序中宏如何使用?
当我们在核函数中不加修饰的声明一个变量,那该变量就是寄存器变量,如果在核函数中定义了常数长度的数组,那也会被分配到Registers中;寄存器变量是每个线程私有的,当这个线程的核函数执行完成后,寄存器变量也就不能访问了。
寄存器是比较稀缺的资源,空间很小,Fermi架构中每个线程最多63个寄存器,Kepler架构每个线程最多255个寄存器;一个线程中如果使用了比较少的寄存器,那么SM中就会有更多的线程块,GPU并行计算速度也就越快。
如果一个线程中变量太多,超出了Registers的空间,这时寄存器就会发生溢出,就需要其他内存(Local Memory)来存储,当然程序的运行速度也会降低。
因此,在程序中,对于那种循环操作的变量,我们可以放到寄存器中;同时要尽量减少寄存器的使用数量,这样线程块的数量才能增多,整个程序的运行速度才能更快。
Local Memory
Local Memory也是每个线程私有的,在核函数中符合存储在寄存器中但不能进入核函数分配的寄存器空间中的变量将被存储在Local Memory中,Local Memory中可能存放的变量有以下几种:
- 使用未知索引的本地数组
- 较大的本地数组或结构体
- 任何不满足核函数寄存器限定条件的变量
Shared Memory
每个SM中都有共享内存,使用__shared__关键字(CUDA关键字的下划线一般都是两个)定义,共享内存在核函数中声明,生命周期和线程块一致。
同样需要注意的是,SM中共享内存使用太多,会导致SM上活跃的线程数量减少,也会影响程序的运行效率。
数据的共享肯定会导致线程间的竞争,可以通过同步语句来避免内存竞争,同步语句为:
void __syncthreads();
当所有线程都执行到这一步时,才能继续向下执行;频繁调用__syncthreads()也会影响核函数的执行效率。
共享内存被分成了不同个Bank,我们知道一个Warp中有32个SM,在比较老的GPU中,16个Bank可以同时访问,即一条指令就可以让半个Warp同时访问16个Bank,这种并行访问的效率可以极大的提高GPU的效率。比较新的GPU中,一个Warp即32个SM可以同时访问32个Bank,效率又提升了一倍。
下面这个图中,左边的图每个线程访问一个Bank,不存在内存冲突,通过一个指令即可完成访问所有的访问操作;右边的图虽然看起来有些乱,但还是一个线程对应一个Bank,也不存在冲突,一个指令即可完成。
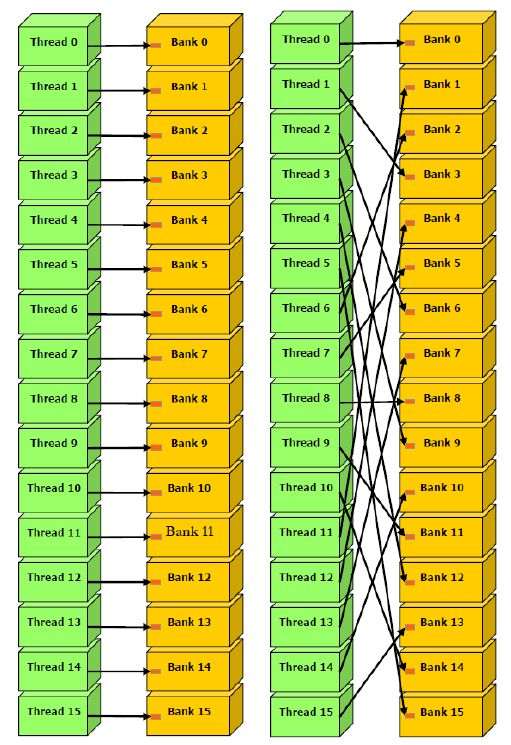
下面这个图中,存在多个Thread访问一个Bank的情况,如果是读操作,那么GPU底层可以通过广播的方式将数据传给各个Thread,延迟不会很大,但如果是写操作,就必须要等上一个线程写完成后才能进行下一个线程的写操作,延时会比较大。

Constant Memroy
常量内存驻留在设备内存中,每个SM都有专用的常量内存空间,使用__constant__关键字来声明。
常量内存存在于核函数之外,在全局范围内声明,常量内容的访问速度也是很快的,对所有的核函数都可见,在Host端进行初始化后,核函数不能再修改。
Texture Memory
纹理内存的使用并不多,它是为了GPU的显示而设计的,这里不多讲了。
Global Memory
全局内存,就是我们常说的显存,就是GDDR的空间,全局内存中的变量,只要不销毁,生命周期和应用程序是一样的。
在访问全局内存时,要求是对齐的,也就是一次要读取指定大小(32、64、128)整数倍字节的内存,数据对齐就意味着传输效率降低,比如我们想读33个字节,但实际操作中,需要读取64字节的空间。
GPU缓存
每个SM都有一个一级缓存,所有SM公用一个二级缓存,GPU读操作是可以使用缓存的,但写操作不能被缓存。
每个SM有一个只读常量缓存,只读纹理缓存,它们用于设备内存中提高来自于各个内存空间内的读取性能。
微信公众号:Quant_Times
