基本概念和公式
- 贝叶斯公式

p(c)是类“先验概率”,p(x|c)是样本x相对于类标记c的类条件概率,p(x)是用于归一化的“证据因子”
- 朴素贝叶斯分类器
采用了属性条件独立性假设,对已知类别,假设所有属性相互独立。
公式改写为:
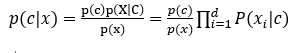
由于对所有类捏来说,p(x)相同,因此上式可表示为:
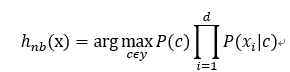
为了避免某些属性在训练集中未出现,抹掉其它属性。采取拉普拉斯修正:

- 半朴素贝叶斯分类器
适当考虑一部分属性间的相互依赖信息,从而既不需要完全联合概率计算,又不至于彻底忽略了比较强的属性依赖关系。半朴素贝叶斯分类器的一种,独依赖关系(ODE),假设每个属性在类别之外最多仅依赖一个其它属性。
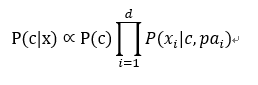
pai为属性xi所依赖的属性,即父属性
三种独依赖关系分类器:SPODE、TAN、AODE
- 贝叶斯网
1.属性的联合概率分布为:
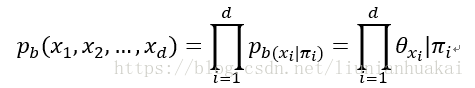
贝叶斯网中三个变量之间的典型依赖关系:同父结构,V型结构,顺序结构。其中V型结构具有边界独立性。
道德图略
2.学习
贝叶斯网B=在D上的评分函数:
s(B|D)=f(θ)|B| - LL(B|D)
(|B|表示贝叶斯网的参数个数,f(θ)表示描述每个参数θ所需的字节数,其中第二项可表示为:)
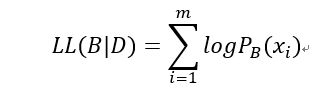
f(θ)=1时,得到AIC评分函数:AIC(B|D)=|B|-LL(B|D)
f(θ)=1/2logm时,得到BIC评分函数:BIC(B|C)=1/2logm*|B|_LL(B|D)
推断略
- EM算法略
算法实现(文档实现案例)
#创建用来训练模型的数据集
def LoadDataSet():
post_list = [
['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']
]
class_vect = [0, 1, 0, 1, 0, 1]
return post_list, class_vect
#去除给定文本中重复出现的词,返回文本词汇
def Unique(dataset):
text = dataset
vocal_list =set([])
for centence in text:
vocal_list = vocal_list | set(centence) #利用set将句子拆分成一个个单词,且去重
return list(vocal_list)
#给定一个句子,查询其词是否出现在词典中,出现为1 ,不出现为0,返回的是一个向量
def CheckVect (vocab, dataset):
vect = [0]*len(vocab)
for data in dataset:
if data in vocab:
vect[vocab.index(data)] = 1
return vect
from numpy import *
def classifyNB0(trainMatrix, trainLabels):
numSentence = len(trainLabels)
lenVect = len(trainMatrix[0])
temp = sum(trainLabels)
pa = temp/float(numSentence)
nv0 =ones(lenVect); nv1=ones(lenVect)
s0 = 2.0; s1 = 2.0
for i in range(numSentence):
if trainLabels[i] == 0:
nv0 += trainMatrix[i]
s0 += sum(trainMatrix[i])
else:
nv1 += trainMatrix[i]
s1 += sum(trainMatrix[i])
p0 = exp(nv0/s0); p1 = exp(nv1/s1)
return p0, p1, pa
from numpy import *
def classify(vec2Classify, p0, p1, pa):
p00 =sum(vec2Classify*p0) + exp(pa)
p11 = sum(vec2Classify*p1) + exp(pa)
if p00>p11:
return 0
else:
return 1
优缺点分析
- 优点
在数据较少的情况下仍然有效,可以处理多类别问题
- 缺点
对输入数据的准备方式较为敏感