声纹识别之PLDA
在深度学习的路上,从头开始了解一下各项技术。本人是DL小白,连续记录我自己看的一些东西,大家可以互相交流。
本文参考:http://www.cctime.com/html/2016-9-1/1214102.htm
https://blog.csdn.net/xmu_jupiter/article/details/47281211
https://www.cnblogs.com/zhangchaoyang/articles/2222048.html
话者确认中信道和时长失配补偿研究_胡群威
以及实验室同学的PPT,感谢!
一、前言
在之前的文章中,我们介绍了关于声纹识别中的特征提取(MFCC)、GMM-UBM系统框架和I-Vector因子分析方法。在之前的文章中我们可以看出,在I-Vector特征中,即包括了说话人信息又包括了信道信息,而我们只关心说话人信息,所以在I-Vector中存在信道信息的干扰,这会降低系统的性能表现。于是,我们还需要通过信道补偿算法来减少这种影响。
线性鉴别分析(Linear Discriminant Analysis,LDA)和概率线性判别分析(Probabilistic Linear Discriminant Analysis,PLDA)就是我们今天要介绍的内容。
二、信道补偿算法
信道补偿算法的意义在于减少I-Vector特征中信道信息对说话人信息的干扰。从模式识别的角度而言,使用信道补偿的目的是增大类间的离散度并且降低类内的离散度,以此获得更高的区分性,提高系统性能。
信道补偿主要分为三个层次:
- 基于特征的补偿(重点)
- 基于模型的补偿
- 基于得分的补偿
三、线性鉴别分析(LDA)概述
线性鉴别分析(LDA)是模式识别领域常用的降维方法。LDA使用标签信息来寻找最优的投影方向,使得投影后的样本集具有最小的类内差异和最大的类间差异。当应用于说话人确认时,同一说话人的I-Vector矢量代表一个类,最小类内差异就是减少信道引起的变化,最大化类间差异就是增大说话人之间的差异信息。
LDA的基本思想即为,将高维的样本(I-Vector)投影到最佳鉴别矢量空间,以达到抽取分类信息和压缩特征空间维数的效果。
举一个例,对于俩类问题,可以看作把样本投影到一个方向上,然后这个一维空间确定一个分类的阀值。如下图所示:

C1和C2分别是两个类别,如果投影在X1,X2这个坐标系中,C1和C2会存在重叠部分,对于他们的区分是困难的,这时候我们需要调整投影方向。我们需要确保,投影后保证模式样本在新的子空间有最大的类间距离和最小的类内距离,即C1,C2在该空间内有最佳的可分离性,如下图所示:
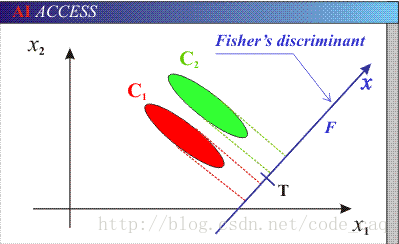
如上所示,我们对于C1,C2调整投影位置后,发现得到了更好区分的方式,这就是关于LDA的概述,接下来我们了解以下PLDA。
四、概率线性判别分析(PLDA)
概率线性判别分析(PLDA)也是一种信道补偿算法,又称概率形式的LDA算法。PLDA通常也是基于I-Vector特征的,为其提供信道补偿。由于PLDA算法的补偿能力比LDA更好,大多数人会更倾向于选择PLDA。
PLDA概念简介
在声纹识别领域,我们假设训练数据语音由 I 个说话人的语音组成,其中每个说话人有 J 段自己不同的语音。那么,我们定义第 i 个人的第 j 条语音为 Xij 。根据因子分析,我们定义 Xij 的生成模型为:
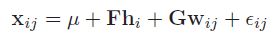
其中,μ 表示全体训练数据的均值;
F 可以看做是身份空间,包含了可以用来表示各种说话人的信息;
hi 就可以看做是具体的一个说话人的身份(或者是说话人在身份空间中的位置);
G 可以看做是误差空间,包含了可以用来表示同一说话人不同语音变化的信息;
wij 表示的是在G空间中的位置;
ϵij 是最后的残留噪声项,用来表示尚未解释的东西。
该项为零均高斯分布,方差为Σ。
PS.关于因子分析的定义式可查看我上一篇文章的内容,此处不再赘述:
https://blog.csdn.net/weixin_38206214/article/details/81096092
回到 Xij 的生成模型,这个模型我们可以看成是两个部分:
1、等号右边前两项(μ + Fhi)只跟说话人有关而跟说话人的某一条语音无关,称为信号部分,描述了说话人之间的差异(类间差异);
2、等号右边后两项(GWij + εij)描述了同一说话人的不同语音之间的差异,称为噪音部分。
此时,我们用了这两个假象变量来描述一个语音的数据结构。参数为:
![]()
PLDA模型训练
PLDA模型训练的目标就是输入一堆数据Xij,输出可以最大程度上表示该数据集的参数θ = [μ,F,G,Σ]。由于我们现在不知道隐藏变量 hi 和 Wij ,所以我们还是使用EM算法来进行求解。
接下来用自然语音来阐述训练流程:
1>均值处理:
计算所有训练数据 Xall 的均值μ,从训练数据中减去该均值 Xall=Xall−μ 。然后,根据训练数据中的人数N,在计算N个人的均值 Nμ。
2>初始化:
首先确定几个配置参数,特征纬度记为D,即 μ 是 D×1 维的, Nμ 是 D×N 维的。 身份空间(F)维度,需要我们预先指定,记为 NF ,即F 是 D×NF 维的,同时 hi 是 NF×1 维的。 噪声空间(G)维度,需同样要预先指定,记为 NG ,即 G 是 D×NG维的,同时 wij 是 NG×1 维的。
噪声空间G,使用随机初始化;
身份空间F,对每个人的均值数据 Nμ 进行PCA降维,降到 NF 维,赋值给 F;
方差Σ 初始化为 D×1 维的常量。
其中PCA(主成分分析)降维可参考博客:
https://www.cnblogs.com/zhangchaoyang/articles/2222048.html
3>EM迭代优化:
首先将上述模型改为矩阵形式:

E-Step:
计算隐含变量h的期望

M-Step:
更新参数 θ=[μ,F,G,Σ]
首先对模型进行重新符号表示:
将[F|G]矩阵拼接表示为B,[hi | wij]矩阵拼接表示为zij
按照如下公式更新参数:
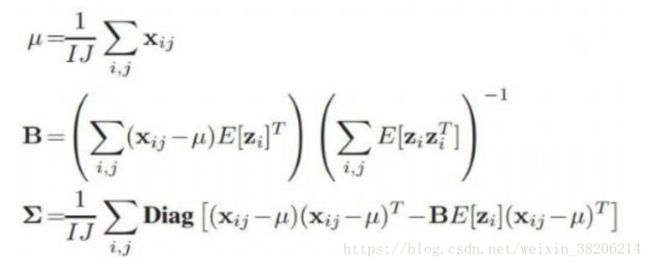
其中,Diag函数表示只保留对角元素。
PLDA的模型测试
在LDA测试时,我们基于consine距离来计算两个I-Vector的相似度来给出得分。在PLDA中,我们计算俩条语音是否由说话人空间中的特征hi生成,或者由hi生成的似然程度,而不用去管类内空间的差异。下面给出得分公式:
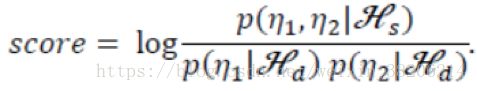
如上公式中,n1和n2分别是两个语音的I-Vector矢量,这两条语音来自同一空间的假设为Hs,来自不同的空间的假设为Hd。
其中p(n1, n2 | hs)为两条语音来自同一空间的似然函数;
p(n1 | hd),p(n2 | hd)分别为n1和n2来子不同空间的似然函数。通过计算对数似然比,就能衡量两条语音的相似程度。
比值越高,得分越高,两条语音属于同一说话人的可能性越大;
比值越低,得分越低,则两条语音属于同一说话人的可能性越小。
PLDA分数扩展
余弦评分
在不使用PLDA或使用LDA信道补偿的情况下,使用余弦评分(Cosine Scoring)方法,来计算两个I-Vector矢量的相似度,以此来评分。根据研究表明,信道信息会引起I-Vector特征矢量的方向改变,而说话人信息主要影响I-Vector特征矢量的方向,采用余弦评分恰好可以消除I-Vector特征矢量模的影响(在余弦中的计算与矢量的模无关),从而在一定程度上削弱信道信息的影响。具体计算公式如下:

其中,Wtar为说话人模型的I-Vector;
Wtest为测试语音的I-Vector。
二者之间的夹角反映了二者的相关性,当二者相关性大时,夹角小,分数高;当二者相关性小时,夹角大,分数低。
总结而言:

如上图所示,是一张基于I-Vector + PLDA的说话人识别系统流程图。至此我们已经大致的梳理了一遍声纹识别的流程。在过去的5天内,我们了解了语音特征提取(MFCC)、GMM-UBM系统框架、EM算法(这个很重要,一直在用到)、聚类和Kmeans算法、I-Vector特征和PLDA信道补偿算法。至此我们已经可以大致的了解如何用一堆预料库来判断一个测试语音是属于哪一个说话人了!但是别急,我们离现在真正流行的技术还差的远呢!(其实之前还有很多坑未填)继续学习吧。