数据结构-树和二叉树总结
数据结构中树的一些代码进行总结,想着为PAT打一下基础,树的代码敲有点太少了,不太熟,看了紫书后敲的,avl树的内容紫书不在树这章,所以后补算了
文章目录
- (一)树的基本概念
- (二)二叉树
- 1.二叉树的存储结构
- 3.二叉树的遍历
- 前序遍历
- 中序遍历
- 后序遍历
- 构建二叉树
- 层次遍历
- 完整代码
- 3.序列转换
- 前序中序转后序
- 中序后序转前序
- 中序后序转层序
- 中序后序转之字形
- 完整代码
- 4.线索二叉树
- 线索二叉树的结构
- 线索二叉树的构造
- 线索二叉树的遍历
- 完整代码
- (三)树与二叉树的应用
- 1.二叉排序树
- 2.平衡二叉树
- 3.哈夫曼(Huffman)树和哈夫曼编码
- 作用一、用于最佳判定算法
- 作用二、哈夫曼编码解码
(一)树的基本概念
(二)二叉树
1.二叉树的存储结构
- 二叉树的链式存储结构,结构体内为二叉树节点的值和左右子树根节点的指针,叶子节点的左右子树为NULL
typedef struct Tree
{
int v;
struct Tree *l,*r;
}BiTree,*Bnode;
-
二叉树的顺序存储结构,varr数组中存放的为各节点的值,n为节点总数
当根节点下标为0时,i节点的左子树根节点下标为
2*i+1,右子树的根节点下标为2*i+2,双亲节点下标为(i-1)/2当根节点下标为1时,i节点的左子树根节点下标为
2*i,右子树的根节点下标为2*i+1,双亲节点下标为i/2顺序存储结构适用于完全二叉树,或者节点个数不多的情况(因为是顺序存储所以需要减少空节点占用数组空间),顺序存储结构可以通过数组下标快速访问左右节点,并且不需要malloc来开辟空间,一般如果条件允许多会选择使用顺序存储来实现;
struct struct Tree
{
int n;
int varr[1000];
}BiTree;
3.二叉树的遍历
是一个递归的过程
前序遍历
先访问根节点,再访问左子树,最后右子树
void PreOrderTraverse(Bnode T)
{
if(T!=NULL)
{
printf("%d ",T->v);
PreOrderTraverse(T->l);
PreOrderTraverse(T->r);
}
}
中序遍历
先遍历左子树,再访问根节点,最后是右子树
void PreOrderTraverse(Bnode T)
{
if(T!=NULL)
{
printf("%d ",T->v);
PreOrderTraverse(T->l);
PreOrderTraverse(T->r);
}
}
后序遍历
先遍历左子树,在遍历右子树,最后访问根节点
void PreOrderTraverse(Bnode T)
{
if(T!=NULL)
{
printf("%d ",T->v);
PreOrderTraverse(T->l);
PreOrderTraverse(T->r);
}
}
构建二叉树
当输入的序列指明了结尾节点的时候可以据此构建二叉树,输入的序列中可以以一个负数或者‘#’,来表示没有后序的节点
构建的过程和遍历类似,这是对前序遍历的序列的构建二叉树过程
void CreateBiTree(Bnode &T,int &n,int num)
{
if(in[n]==-1||n>=num) //终端情况
{
T=NULL;
return;
}
T=(Bnode)malloc(sizeof(BiTree)); //创建根节点
T->v=in[n];
CreateBiTree(T->l,n+=1,num); //创建左子树
CreateBiTree(T->r,n+=1,num); //创建右子树
}
层次遍历
对于一棵链式结构的二叉树进行层次遍历,可以先进行一次先序遍历,在先序遍历的时候记录各节点在顺序存储结构时的下标,就是将链式结构转化为顺序结构,接着直接输出顺序存储结构的数组就行;
int level_arr[10000];
void func1(Bnode T,int k,int no,int &m)
{
if(T!=NULL)
{
m=m>no?m:no;
level_arr[no]=T->v;
func1(T->l,k+1,no*2+1,m);
func1(T->r,k+1,no*2+2,m);
}
}
void LevelOrderTraverse(Bnode T)
{
memset(level_arr,-1,sizeof(level_arr)); //-1代表这个下标对应没有节点,为空
int m=0;
func1(T,1,0,m);
int i;
for(i=0;i<=m;i++)
if(level_arr[i]!=-1)
printf("%d ",level_arr[i]);
}
完整代码
对如下的树A就行构建二叉树的链式存储结构和遍历;
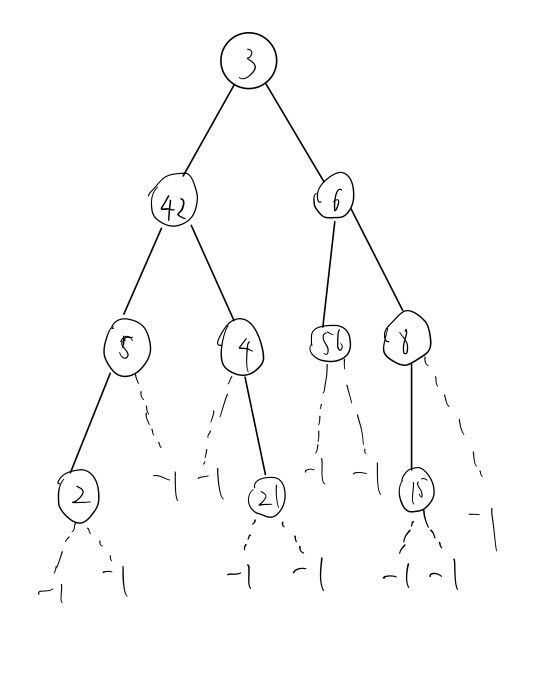
注意:函数里的变量为局部变量是存储在栈空间的变量,栈空间的内存较小;如果需要定义大数组,需要定义为全局变量,全局变量是存储在堆空间上的变量,可以存放较大规模的数组;
#include运行结果
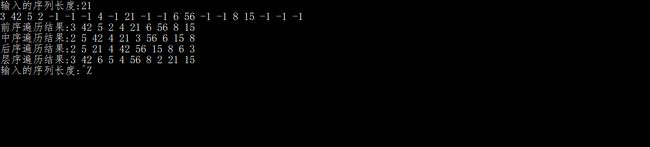
3.序列转换
看着柳婼的blog学的,一个很厉害的大神
当直接给出对二叉树的遍历后的序列,没有结束符号或者其他信息,我们无法只根据前序遍历结果,或者后续遍历结果,或者后序遍历结果来还原二叉树;
但是对于一个前序遍历结果我们可以很容易知道一棵二叉树的根节点的位置(就是序列的第一个树),但此时我们并不能知道它的后序序列哪部分属于左子树,那部分属于右子树;所以此时只需要一个中序遍历的序列就可以得到左右子树的节点数量n1、n2和节点信息;因为我们从前序序列中知道了根节点,所以在中序序列中对应根节点的左侧就是左子树,右侧就是右子树,而根据中序序列的信息我们可以知道前序序列的[1,n1](根节点下标为0)为左子树的前序遍历结果,[n1+1,n1+n2]为右子树的前序遍历结果,接着对左右子树递归这一过程,就可以还原一棵树,或者将其转化为后序序列;
后序遍历与其相同
但是这个方法只对节点信息唯一的树有效,如果有值相同的节点,则中序序列的拆分情况会不唯一!
所以知道前序中序可以推出后序,知道中序后序可以推出前序,知道前序后序并没有用
前序中序转后序
//root代表前序的子树根元素的下标;s,e代表中序的第一个元素的下标和最后一个元素后一个元素的下标
//pre为前序序列,in为中序序列
void func1(int root,int s,int e)
{
if(s<e)
{
int i=s;
while(i<e&&pre[root]!=in[i])i++;
func1(root+1,s,i);
func1(root+i-s+1,i+1,e);
printf("%d ",pre[root]);
}
}
中序后序转前序
//root代表后序的子树根元素的下标;s,e代表中序的第一个元素的下标和最后一个元素后一个元素的下标
//post为后序序列,in为中序序列
void func2(int root,int s,int e)
{
if(s<e)
{
int i=s;
while(i<e&&post[root]!=in[i])i++;
printf("%d ",post[root]);
func2(root-e+i,s,i);
func2(root-1,i+1,e);
}
}
中序后序转层序
只需要在中序后序转前序的时候记录根节点的下标即可,就是在遍历的过程中转化为顺序结构
int res[1000];
void m_func1(int root,int s,int e,int index,int &num)//index为对应下标
{
if(s<e)
{
int i=s;
while(i<e&&post[root]!=in[i])i++;
num=max(num,index);
res[index]=post[root];
m_func1(root-e+i,s,i,index*2+1,num);
m_func1(root-1,i+1,e,index*2+2,num);
}
}
void func3(int n)
{
memset(res,-1,sizeof(res));//初始化,-1为空节点
int i=0;
int num=0;
m_func1(n-1,0,n,0,num);
for(;i<=num;i++)
if(res[i]!=-1)
printf("%d ",res[i]);
}
中序后序转之字形
用一个vector数组存放每层结果,在中序后序转前序的过程添加当前层数的信息参数k,因为在前序遍历中每层靠左的节点会先遍历到(因为是先左子树再右子树),所以在转换过程中将对应节点push到对应的k层中,最后输出即可
vector<int> varr[100];
void m_func2(int root,int s,int e,int k,int &max_k)
{
if(s<e)
{
int i=s;
while(i<e&&post[root]!=in[i])i++;
max_k=max(k,max_k);
varr[k].push_back(post[root]); //添加到对应层
m_func2(root-e+i,s,i,k+1,max_k);
m_func2(root-1,i+1,e,k+1,max_k);
}
}
void func4(int n)
{
int max_k=0;
m_func2(n-1,0,n,0,max_k);
for(int i=0;i<=max_k;i++)
{
if(i%2==0)
{
for(int j=0;j<varr[i].size();j++)
printf("%d ",varr[i][j]);
}
else
{
for(int j=varr[i].size()-1;j>=0;j--)
printf("%d ",varr[i][j]);
}
puts("");
}
}
完整代码
对树A的结果进行转换
#include运行结果

4.线索二叉树
线索二叉树的结构
二叉树的节点中添加左右节点的标志情况,link代表其指向后序子树,thread表示其为左子树或右子树的时候没有后序子树则标志为线索,此时l指向前驱,r指向后继
enum tag{link,thread};
typedef struct Tree
{
int v;
struct Tree *l,*r;
tag lt,rt; //lt是前驱标志,rt是后继标志
}BiTree,*Bnode;
线索二叉树的构造
为了方便起见,仿照线性表的存储结构,在二叉树的线索链表上也添加一个头节点,并令其l域指向二叉树的根节点,r域指向中序遍历时访问的最后一个节点
反之中序序列的第一个节点的l域和最后一个节点的r域均指向头节点。
好比建立了一个双向线索链表
在中序遍历中构建线索二叉树B

在遍历中需要记录前驱pre
在每次遍历中,void threading(Bnode p)
- 需要检查当前节点的l域是否为空,为空即将线索标志置为thread,l域指向前驱pre
- 需要检查前驱节点的r域是否为空,为空即将线索标志置为thread,r域指向当前节点p
- 遍历右子树前,需要更新前驱
pre=p;
对于头节点:
-
遍历初始的前驱为头节点Thrt
-
在遍历构造结束后,pre指向最后一个节点,需要更新其后继,使其指向thrt,并使thrt的r域指向pre构成双向链表
-
头节点l域并不是指向后继而是指向根节点,所以标志为link,而r域则指向的是其末端节点,所以标志为thread
Bnode pre;
void threading(Bnode p);
bool func(Bnode &Thrt,Bnode T)
{
Thrt=(Bnode)malloc(sizeof(BiTree));
Thrt->lt=link; //头节点的前驱就是中序遍历的第一个节点所以指针域不为空,为link标志
Thrt->rt=thread; //头节点的右子树没有后继指向,所以为空,所以应为线索,构成循环
Thrt->r=Thrt; //先暂时指向自身
if(!T)
Thrt->l=Thrt;
else
{
Thrt->l=T; //树不为空
pre=Thrt;
threading(T);
Thrt->r=pre;//在threading之后pre就是中序遍历的最后一个节点
pre->rt=thread; //!!
pre->r=Thrt; //最后一个节点也要设置后继
}
return true;
}
void threading(Bnode p)
{
if(p)
{
threading(p->l);
if(!p->l)//对p来说只要考虑前驱
{
p->lt=thread;
p->l=pre;
}
if(!pre->r)//对pre来说只要考虑后继
{
pre->rt=thread;
pre->r=p;
}
pre=p;
threading(p->r);
}
}
线索二叉树的遍历
根据中序遍历的规则可以知道节点的后继节点为其右子树的最左下角的节点,所以当后继标志rt为0(link)时,表示其有右子树,即遍历右子树顺着左指针找到最左下角的节点(终止条件为lt==thread)输出;后继标志rt为1(thread)时,表示l直接指向后继,即直接输出;终止条件为遍历到头节点thrt。
可以将树看成thrt头节点的右子树,因此可以不用将thrt的l指向最左下脚的节点
void traverse(Bnode T)
{
Bnode p=T->l;
while(p!=T)//树不为空 ,此时p已经是后续了所以不用访问右子树
{
while(p->lt==link)//中序遍历先遍历左子树,所以在左子树中找序列的首节点
p=p->l;
printf("%d ",p->v);//一开始为头节点的后继!
while(p->rt==thread&&p->r!=T) //判断后续是否为头节点!
{
p=p->r;
printf("%d ",p->v);//输出后继节点!!
//注意节点更新和输出顺序!
//后继是被找到后输出的,所以这个算法每次输出的都是后继节点而不是当前节点!!
}
p=p->r;
}
}
完整代码
#include运行结果(构建树B,后输出其中序遍历序列)

(三)树与二叉树的应用
1.二叉排序树
后补
2.平衡二叉树
后补
3.哈夫曼(Huffman)树和哈夫曼编码
哈夫曼树(赫夫曼树),又称最优树(最优二叉树),是一类带权路径长度最短的树;
路径长度:树中一个节点到另一个节点路径上的分支数,(完全二叉树就是这种路径长度最短的二叉树);
**节点的带权路径长度:**从该节点到树根之间的路径长度与节点上权的乘积;
树的带权路径长度:树中所有叶子节点的带权路径长度之和;
- 记作
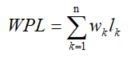
构造赫夫曼树的算法描述:
1.根据给定的n个权值{w1,w2,…,wn}构成n棵二叉树(只含一个节点)的集合F= {T1,T2,…,Tn}.,其中每颗二叉树Ti中只有一个带权为Wi的根节点,其左右子树为空。
2.在F中选取两颗根节点的权值最小的树作为左右子树构造一颗新的二叉树,并且新的二叉树的根节点的权值为左右子树根节点上的权值之和。
3.在F中删除这两棵树,将新的到的二叉树加入F中。
4.重复二三,直到F中只剩下一棵树为止,这就是赫夫曼树。
作用一、用于最佳判定算法
例:将一个百分制转换为五级分制(严为蔚敏p144):
最直接简单的if判断形式
if(a<60)res="bad";
else if(a<70)res="pass";
else if(a<80)res="general";
else if(a<90)res="good";
else res="excellent";
但是这个算法可以发现在输入量非常大时,如果>90的成绩比重较大的话,那么比较次数就会非常多;如果<60的成绩比重较大的话,那么比较次数就会比较理想,其本身形成的判定树如(a)所示:

那么对于预估比例系数如下的成绩序列可以做出优化
| 分数 | 0—59 | 60—69 | 70—79 | 80—89 | 90—100 |
|---|---|---|---|---|---|
| 比例数 | 0.05 | 0.15 | 0.40 | 0.30 | 0.10 |
通过上述成绩分布,可以构建赫夫曼树的过程构建赫夫曼树(b)如下:

但是可以发现,在此赫夫曼树中有三个判定节点需要作两次判断,因此可以进一步优化:
对于单向的比较区间,不难想到两个比较区间可以确定一个成绩等级,因此为了得到赫夫曼树(c),所互为父子的节点必须为相邻区间,而且每选定一个节点应该可以确定一个区间(因为其作为叶子节点):(1)0-59这个区间的权值最小,并且<60可以确定区间,所以先取出构成节点<60;(2)其次90-100这两个相邻区间的权值之和最小,所以新结点为<90,但是<90与<60并不是相邻区间,所以单独形成一个叶子节点;(3)接着在选择60-69,因为其与a<60相邻所以作为其父节点;反复合并得到下图:

对应代码:
if(a<80)
{
if(a<70)
{
if(a<60) b="bad";
else b="pass";
}
else b="general";
}
else
{
if(a<90)b="good";
else b="excellent";
}
作用二、哈夫曼编码解码
进行快速远距离通信的电报,通过哈夫曼编码可以增加安全性:
因为传输报文需要快速并且可以高效的编码译码:所以编码的长度应该尽可能短,在对于字符串编码时,会有一些字符是高频出现的比如‘a’或者‘s’,所以在哈夫曼编码中其对应的权值就会比较大,权值越大就越接近根节点,因此对应的编码值就会比较短;
哈夫曼编码的特点:任一个字符的编码都不是另一个字符v的w编码的前缀,称为前缀编码
哈夫曼树的特点:
- 哈夫曼树中没有度为1的节点(这类树又称为严格的(strict)(或正则的)二叉树),因此对于有n个叶子节点的哈夫曼树,共有2n-1个节点!
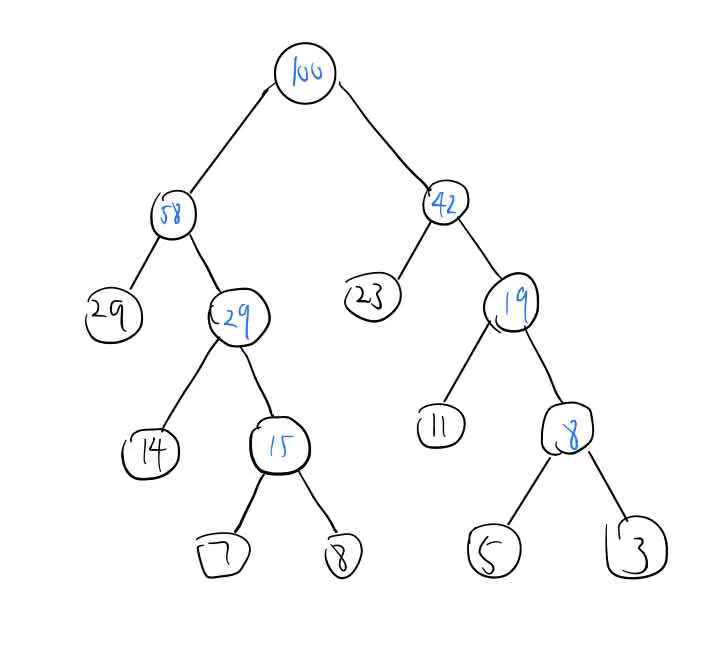
先假设在日常中电文的8个字符的频率统计如下表所示:(严蔚敏p148)
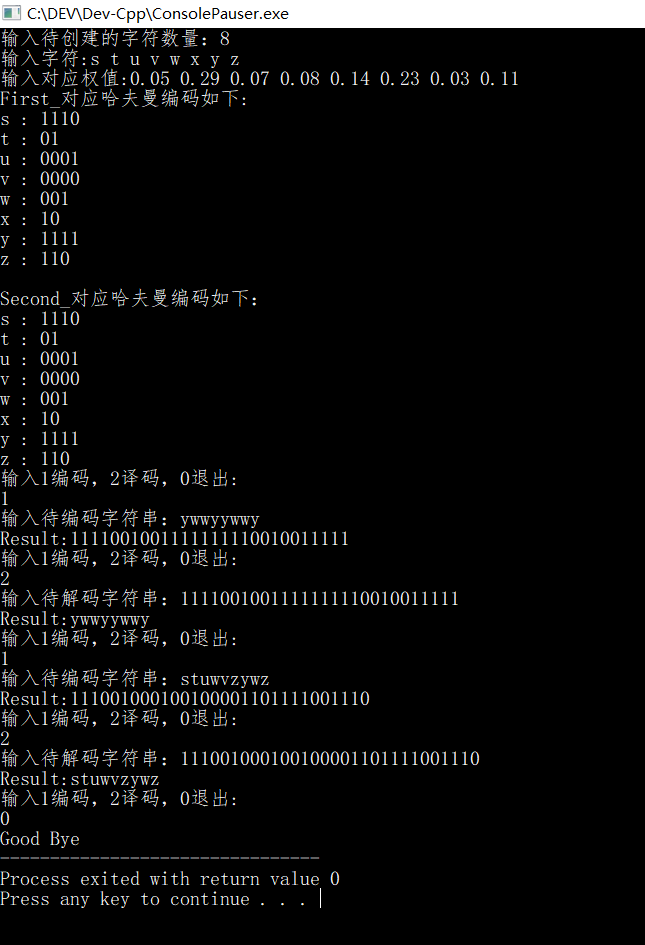
| 字符 | s | t | u | v | w | x | y | z |
|---|---|---|---|---|---|---|---|---|
| 占比 | 0.05 | 0.29 | 0.07 | 0.08 | 0.14 | 0.23 | 0.03 | 0.11 |
得到对应的哈夫曼树如下(和书里的不同,这是根据下面代码画的树):
哈夫曼树结构体:
typedef struct
{
int weight; //节点权值
char v; //对应对象值
int p,l,r; // 双亲,左孩子,右孩子
}HTNode ,* HuffmanTree;
构建哈夫曼树
void CreateHuffmanTree(HuffmanTree &HT,const int *w,const char *v,int n)
{
int i,s1,s2;
if(n<=1)
return ;
int m=2*n-1;
HT=(HuffmanTree)malloc(sizeof(HTNode)*(m+1)); //不使用0号单元
for(i=1;i<=n;i++)
HT[i]={w[i],v[i],0,0,0}; //好像是C++11的赋值方法
for(;i<=m;i++)
HT[i]={0,' ',0,0,0};
for(i=n+1;i<=m;i++)//建赫夫曼树
{ //从第[1,i-1]中筛取权值最小的两个节点s1、s2,选取的节点的父节点的weight应该为0!
Select(HT,i-1,s1,s2);//i-1!!!
HT[i].weight=HT[s1].weight+HT[s2].weight;
HT[i].l=s1,HT[i].r=s2;
HT[s1].p=i;
HT[s2].p=i;
}
}
从叶子节点到根节点获取哈夫曼编码
//编码规则:左子树0,右子树1
HuffmanCode CreateHuffmanCode_1(const HuffmanTree &HT,const char *arr,int n)//从叶子节点向根逆向编码
{
HuffmanCode res=NULL;
if(HT==NULL)
return res;
res=(char **)malloc(sizeof(char*)*(n+1));//分配n个字符编码的头指针向量
char * marr=(char*)malloc(sizeof(char)*n); //分配编码空间
marr[n-1]='\0'; //编码结束位置
for(int i=1;i<=n;i++)
{
int start=n-1;
int j,mp;
for(j=i;HT[j].p!=0;j=HT[j].p)
{
mp=HT[j].p;
if(HT[mp].l==j)
marr[--start]='0';
else
marr[--start]='1';
}
res[i]=(char*)malloc(sizeof(char)*(n-start+1));
strcpy(&(res[i][1]),&marr[start]);
res[i][0]=arr[i]; //第0个位置放编码对象
}
free(marr);//不要忘记释放在堆上开辟的空间
return res;
}
从根节点到叶子节点非递归形式获得哈夫曼编码,和书上的不太一样,不过思路是一样的。我用一个vis数组来判断节点遍历状态,但是如果是书上的代码,一定不要忘记在使用HT本身记录状态时还原为原状态!(倒数第三行的HT[p].weight=0),不然会影响下一次的编码。
HuffmanCode CreateHuffmanCode_2(const HuffmanTree &HT,int n)
{
HuffmanCode res=NULL;
if(HT==NULL)
return res;
res=(HuffmanCode)malloc(sizeof(char*)*(n+1));
int i,len=0,m=2*n-1;
char * marr=(char*)malloc(sizeof(char)*(n+1));
int * vis=(int*)malloc(sizeof(int)*(m+1)); //0表示节点为遍历,1表示节点遍历了左子树,2表示节点遍历了右子树
memset(vis,0,sizeof(int)*(m+1)); //指针不能直接sizeof(vis)
int p=m;
while(p)
{
// printf("p=%d\n",p);
if(!vis[p])
{
vis[p]=1;
if(HT[p].l!=0)
{
p=HT[p].l;
marr[len++]='0';
}
else if(HT[p].r==0)
{
res[p]=(char*)malloc(sizeof(char)*(len+2)); //'/0'和对象值
res[p][0]=HT[p].v;
marr[len]='\0';
strcpy(&(res[p][1]),marr);
}
}
else if(vis[p]==1)
{
vis[p]=2;
if(HT[p].r!=0)
{
p=HT[p].r;
marr[len++]='1';
}
}
else
{
p=HT[p].p;
len--;
}
}
return res;
}
对字符串进行哈夫曼编码
char * Encoding(const char *arr,const HuffmanCode HC,int n)
{
int i,j;
char *res=(char*)malloc(sizeof(char)*n*strlen(arr));//单个字符的最大编码长度不超过n
for(i=0;i<strlen(arr);i++)
{
for(j=1;j<=n;j++)
{
if(arr[i]==HC[j][0])
{
strcat(res,&(HC[j][1]));
break;
}
}
}
return res;
}
对字符串进行哈夫曼解码
char * Decoding(const char *arr,const HuffmanCode HC,int n)
{
int i,j,k,num=0;
char *res=(char*)malloc(sizeof(char)*strlen(arr));//待解码字符串的长度肯定大于原字符串
for(i=0;i<strlen(arr);)
{
for(j=1;j<=n;j++)
{
int len=strlen(&(HC[j][1]));
for(k=0;k<len;k++)
{
if(HC[j][1+k]!=arr[i+k]||i>=strlen(arr))
break;
}
if(k==len)
break;
}
res[num++]=HC[j][0];
i+=strlen(&(HC[j][1]));
}
return res;
}
完整代码(应该是用纯C写的)
#include结果: