keras学习笔记(一)
之前看了一个用karas构建的一个GAN网络,这个网络的目的是基于cifar10中数据,生成出和真实数据相似的数据。现在想把这个网络转换成用tensorflow写的网络,因此开始学习keras的基本语法。之后会把keras实现的GAN网络做一个解释。最后会写出一个能跑通的tensorflow实现的GAN网络。
1.兼容性backend
keras有两个backend,当第一次import keras时,会显示Using TensorFlow backend.或者是Using Theano backend,这表示你目前使用的keras是用tensorflow还是theano作为底层计算的。如果你想转换这个后端,可以使用下列语句:或者去网上搜别的方法,更改keras的后端。
import os
os.environ['KERAS_BACKEND']='theano'
import keras2.用keras设计网络,解决一个线性回归问题
keras中搭建网络的办法有多种,我可能会写两到三种搭建神经网络的方式,这个代码只是其中一种。
import keras
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
import matplotlib.pyplot as plt
#创建数据
X=np.linspace(-1,1,200)
np.random.shuffle(X)
noise=np.random.normal(0,0.05,(200,))
Y=1.5*X+2+noise
X_train, Y_train = X[:160] , Y[:160] #创建训练数据和测试数据
X_test , Y_test = X[160:] , Y[160:]
model=Sequential() #建立一个顺序的模型,建立好模型后就可以往里面添加各种需要的层
#这个Dense是全连接层,第一层需要定义输入得维度和输出的维度,之后再添加层只需定义输出维度
#在keras中添加层,默认上一层的输出维度等于下一层的输入维度,也是为什么keras高级的地方
model.add(Dense(output_dim=1,input_dim=1,name='Dense_1'))
#model.add(Dense(output_dim=1,name='Dense_2',activation='sigmoid'))
#选择优化方法和loss函数,mse是平均方差,sgd是随机梯度下降的方法,
#当然优化方法有很多中,这边只需要把这个相应的字符串输入即可,而且优化器的参数并不只有学习率,但是最重要的就是学习率,其他的参数可以去keras中文文档中去查询
optimizer=keras.optimizers.sgd(lr=0.01)
model.compile(loss='mse',optimizer=optimizer)
#制图,可视化训练过程
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.scatter(X,Y)
#训练
for step in range(1000):
#model.train_on_batch训练目的是最小化训练数据的损失函数,返回的是这次训练过后的损失值。
cost=model.train_on_batch(X_train,Y_train)
#训练完一组数据后,用一些测试数据去测试这个模型,把损失结果打印出来
if step%20==0:
cost = model.evaluate(X_test, Y_test, batch_size=40)
print('train cost :', cost)
Y_predict = model.predict(X_test)
lines = ax.plot(X_test, Y_predict, 'r', lw=2)
plt.pause(0.1)
ax.lines.remove(lines[0])
#测试
#打印出最终的权重、偏置和损失函数的值
cost=model.evaluate(X_test,Y_test,batch_size=40)
print('test cost:',cost)
W,b=model.get_layer('Dense_1').get_weights()
print('Weight=',W,'\nbiases+',b)
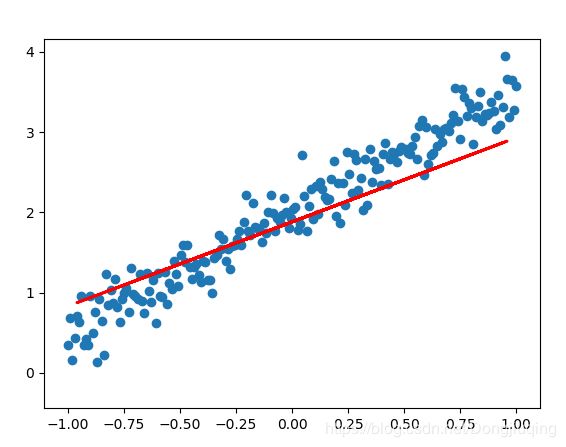
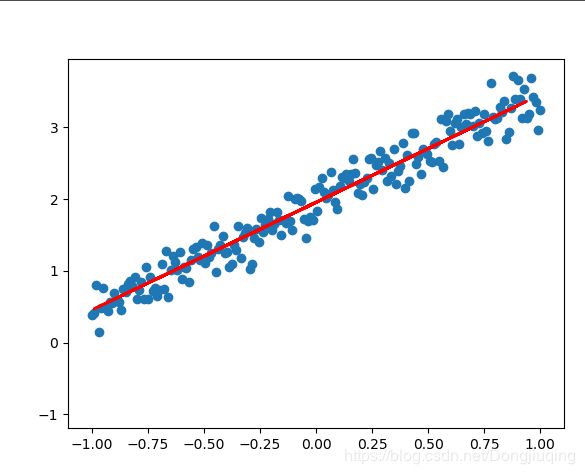
这些是训练过程的可视化,可以看出我们的目标是用一条线不断拟合这些散乱的点。下面是训练过程中的损失函数的变化,以及权重和偏置的结果。
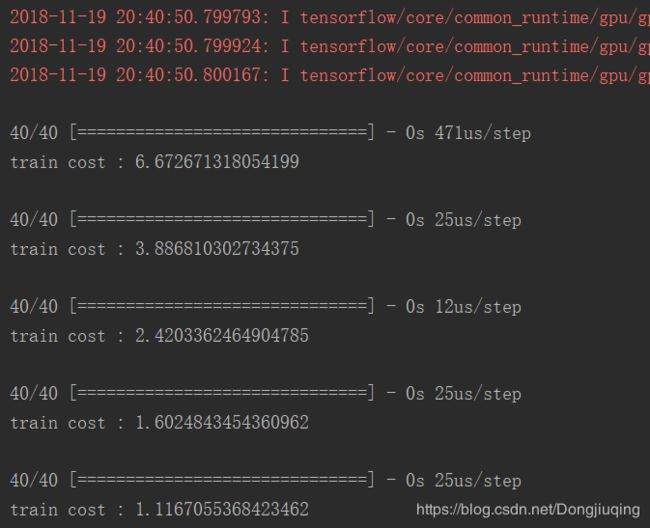
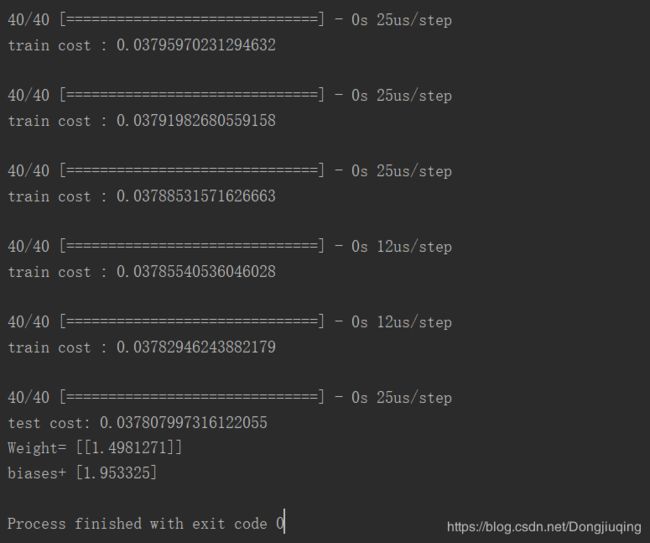
3.classification分类:MNIST手写数字分类
import keras
import numpy as np
from keras.utils import np_utils
from keras.layers import Dense,Activation
from keras.optimizers import RMSprop
#获取mnist数据集,用变量存储
(X_train, Y_train), (X_test,Y_test) = keras.datasets.mnist.load_data()
print(X_train.shape) #这几句只是打印一下数据和标签的shape,供检查
print(Y_train.shape)
X_train = X_train.reshape(X_train.shape[0],-1)/255 #数据标准化(归一化)
X_test = X_test.reshape(X_test.shape[0],-1)/255
Y_train=np_utils.to_categorical(Y_train,10)#一种编码方式,one-hot编码,比如第二个类别就是第二个数是1,其他都是0
Y_test =np_utils.to_categorical(Y_test ,10)
print(X_train.shape)
print(Y_train.shape)
#建立网络结构
model=keras.Sequential([
Dense(output_dim=32,input_dim=784),
Activation('relu'),
Dense(10),
Activation('softmax'),
])
#建立网络模型,包括网络,损失函数,优化器
optimizer=keras.optimizers.RMSprop(lr=0.001,rho=0.9,epsilon=1e-8,decay=0.0)
model.compile(loss='categorical_crossentropy',optimizer=optimizer,metrics=['accuracy'])#metrics可以存储一些训练过程中的我想要的数据
#开始训练,共10个epoch,并打印损失值和精度,一次丢进去一百张图,每次训练都会打印
model.fit(X_train,Y_train,nb_epoch=10,batch_size=100)
#训练模型的评估结果
loss,accuracy=model.evaluate(X_test,Y_test)
print('test loss',loss)
print('accuracy',accuracy)
结果:

接下来会去自己去写一个使用数据集cifar10的卷积神经网络,因为mnist书籍集都是单通道,而且是别人处理好的。不需要任何卷积层即可实现分类的数据集。
参考教程:https://www.bilibili.com/video/av16910214/?p=9