上一篇主要讲到了单表间直接转换的场景,本文我们介绍第二种核心转换场景:字段合并与字段拆分。
字段合并是指将不同字段的值,进行合并,形成新的合并列,比如字段A+字段B=字段AB。
字段拆分是指将一个字段中的值,进行拆分,形成新的拆分列,比如字段AB=字段A+字段B。
首先,我们介绍字段合并。
(一)字段合并
应用场景:对于部分来源表的转换需求而言,希望将来源表的字段值进行合并,再将合并后的值映射到目标表的某个字段,比如常见的来源表字段中姓和名合并为姓名,如姓【张】名【三】,映射到目标表之后为【张三】,接下来将以金融数据中的证券名称(万科A)和证券代码(000002)合并为【万科A0000002】为例进行实操。
业务目标:将来源库A中的表A【sec_basic_info1(证券基本信息表)】的数据推送到目标数据库B中的表B【sec_basic_info2(证券基本信息表)】,并将来源表A的sec_name(证券名称)和sec_code(证券代码)字段合并映射到目标表B的remark(备注)字段中。
业务流程分析:
抽取数据:抽取来源库A的数据表A【sec_basic_info1(证券基本信息表)】的数据,可以定义抽取数据范围;
转换数据:来源表A的sec_name(证券名称)和sec_code(证券代码)字段合并映射到目标表B的remark(备注),其他字段直接映射;
加载数据:数据加载到目标库B的数据表B【 sec_basic_info2(证券基本信息表)】中,目标表已有数据,进行更新;否则,新增数据。
操作步骤:
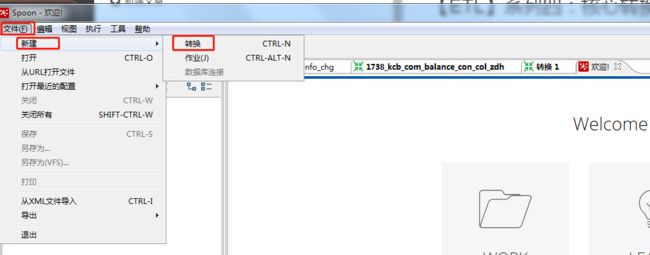
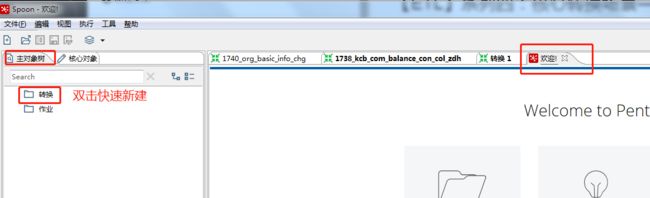
1、启动Spoon,进入主界面。点击左上角的文件 → 新建 → 转换, 新建一个转换;或者在欢迎页tab,主对象树窗口双击转换快速新建。
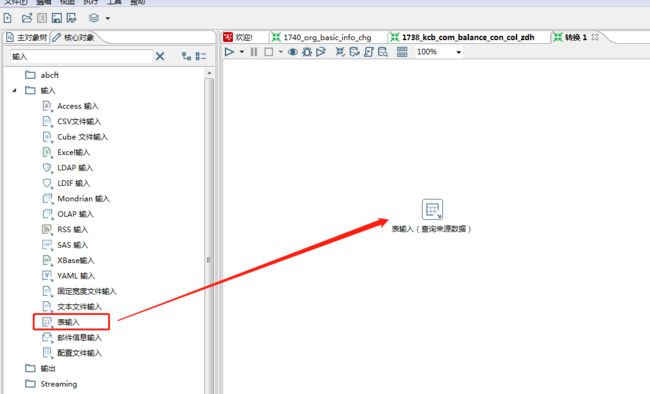
2、点击左侧的核心对象,选择表输入并把它拖到右侧的编辑区中进行配置。
由于抽取的数据来源某个数据库的数据表,因此拖选【表输入】插件,为了方便业务理解,可以将插件重命名。
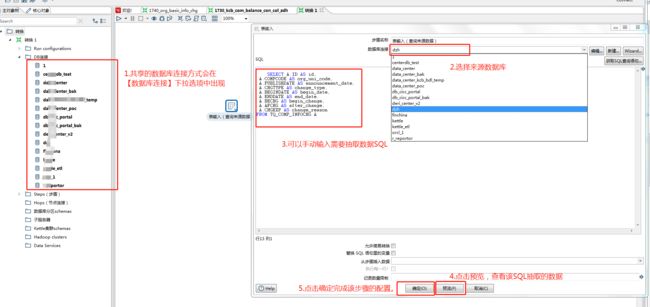
表输入插件是为了查询来源数据,也就是抽取的数据,因此需要将来源库表信息进行填写或选择后,进行抽取SQL的定义。
关于数据库连接的方式,此处不做赘述,可参考kettle数据库连接。
表输入配置完成后,保存转换文件,可点击【运行这个转换】按钮进行本地运行。
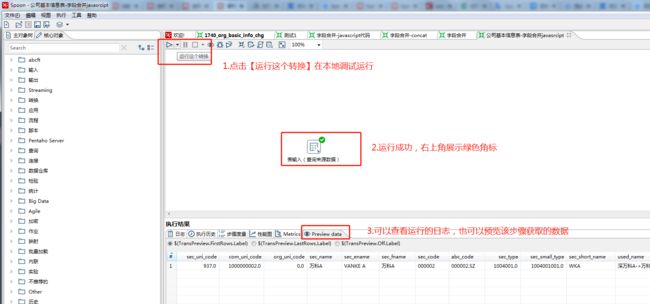
3、点击左侧的 核心对象 ,选择 javaScript脚本 并把它拖到右侧的编辑区中,按住 shift 画线连接 “表输入(查询来源数据)”。
javaScript代码脚本提供了很多转换函数,在进行字段的转化过程中比较方便。

双击编辑区的“javascript脚本”,编辑脚本信息,主要信息如下:
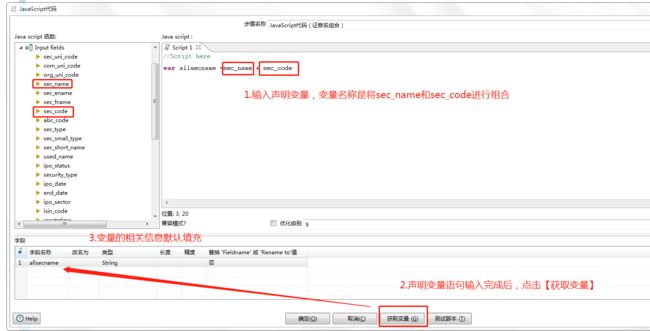
(1)变量信息输入: 由于“sec_name ” 和 “sec_code” 合并,因此我们只需要在 “java script:”下的输入框中输入声明变量;
var allsecname =sec_name + sec_code
(2)手动获取变量:点击【获取变量】自动将我们定义的变量输出到字段栏中,我们也可以修改字段名称。
【javaScipt代码】配置完成后,保存转换文件,可点击【运行这个转换】按钮进行本地运行。
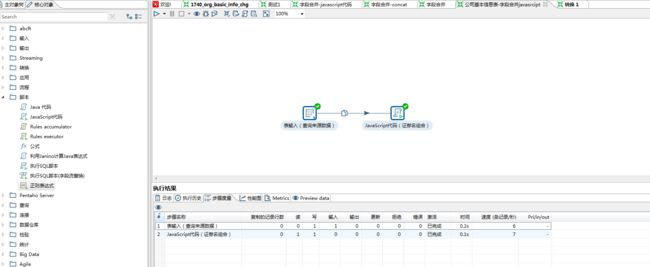
4、点击左侧的核心对象,选择插入/更新并把它拖到右侧的编辑区中,按住shift键连接 “javaScipt代码(证券名组合)”。
表输出插件是为了将抽取数据输出到目标表,因此主要做三件事:
(1)目标数据库表信息进行填写或选择;
(2)进行目标表字段唯一索引字段的配置,根据唯一索引,查看数据是否存在,当数据存在,更新数据;若不存在,则插入数据;
(3)目标表字段与来源表字段的映射关系配置,需要将上一步骤定义的变量字段与目标表字段进行正确的映射。
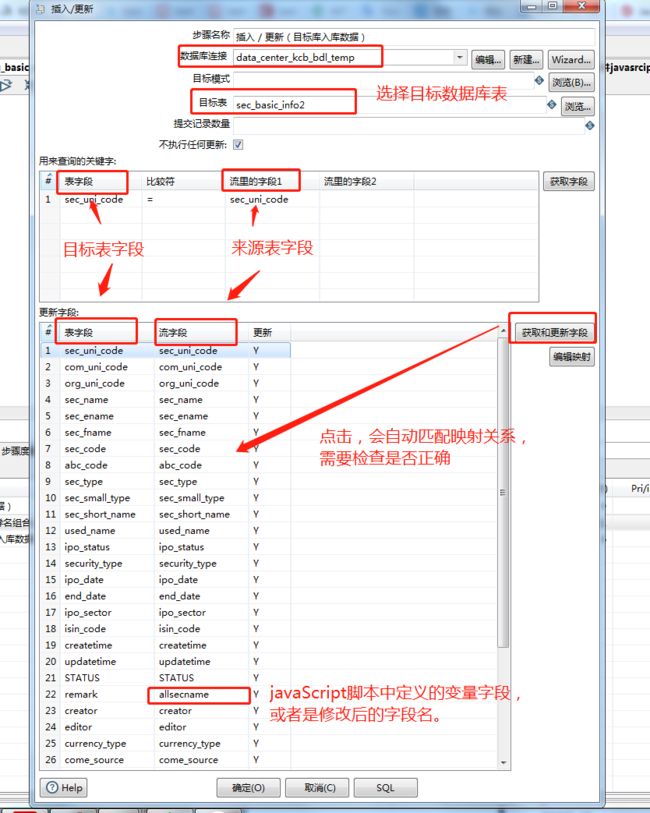
如截图中的配置,选择完目标数据库和目标数据表之后,用来查询的关键字,选择sec_uni_code,表示这里按照sec_uni_code查询,如果此sec_uni_code存在,则更新数据,若不存在则插入数据;获取目标表字段和来源表的流字段映射关系,javascript中定义的变量字段需要与目标表字段进行正确映射,然后点击保存即可。
插入/更新配置完成后,保存转换文件,可点击【运行这个转换】按钮进行本地运行。

5、转换成功后,也可以检查本地数据库,查看数据是否推送成功,是否正确将字段进行合并。

到这里,字段合并转换流程就配置成功了,后续打开.ktr后缀的文件即可,除了这种字段合并转化方式,我们可以使用SQL语句中 CONCAT函数更方便地进行字段合并后推送。
SQL CONCAT函数用于将两个字符串连接起来,形成一个单一的字符串。接下来,我们做下简单介绍。
1、选择表输入并把它拖到右侧的编辑区中进行配置,主要是进行自定义SQL语句。
SQL语句中,需要注意的2点:
(1)需要正确使用CONCAT函数, CONCAT(field1,field12) AS field ;
(2)SQL语句的格式,AS 后是来源表抽取后的流字段。
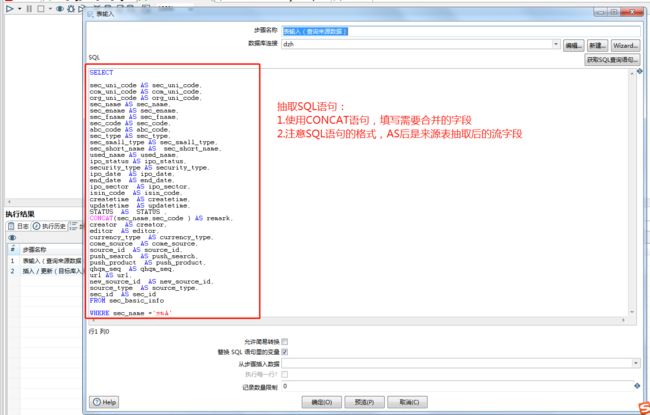
如上截图,需要将sec_name和sec_code进行合并,输入CONCAT(sec_name,sec_code )AS remark语句即可。
2、选择插入/更新并把它拖到右侧的编辑区中进行相关配置。
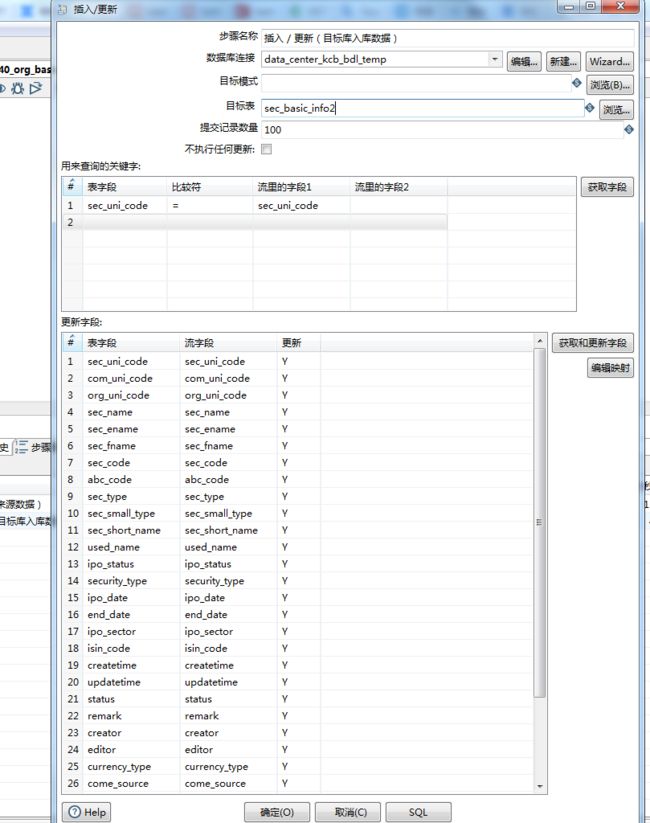
如截图中的配置,由于目标表字段和来源表定义的AS后的流字段一致,直接映射即可,会减少一些字段映射的时间。
3、查看转换结果。
运行该转换配置,可以正常运行,并将来源表的字段进行正确合并并同步到目标数据表。
以上是字段合并的2中转换配置方式,可以根据业务需求和使用习惯进行配置和执行。与字段合并相对的,就字段拆分了。
(二)字段拆分
字段拆分是指一个字段中的值,进行拆分,形成新的拆分列,即字段AB=字段A+字段B。
应用场景:对于部分来源表的转换需求而言,希望将来源表的字段值进行进行拆分,再将拆分后的值映射到目标表的1个或几个字段,比如常见的来源表的字段中地址进行拆分,如【湖北省武汉市东湖新技术开发区】,映射到目标表需要拆分为【湖北省】、【武汉市】、【东湖新技术开发区】,接下来将以金融数据中的曾用名(深万科A->万科A->G万科A)拆分为字段(深万科A)为例进行实操。
业务目标:将来源库A中的表A【sec_basic_info1(证券基本信息表)】的数据推送到目标数据库B中的表B【sec_basic_info2(证券基本信息表)】,并将来源表A的used_name(曾用名)第一个值进行字段拆分到目标表remark(备注)字段中。
业务流程分析:
抽取数据:抽取来源库A的数据表A【sec_basic_info1(证券基本信息表)】的数据,可以定义抽取数据范围;
转换数据:来源表A的used_name(曾用名)第一个值进行字段拆分并映射到目标表B的remark(备注),其他字段直接映射;
加载数据:数据加载到目标库B的数据表B【 sec_basic_info2(证券基本信息表)】中,目标表已有数据,进行更新;否则,新增数据。
与字段合并相似,我们可以使用kettle中的插件来实现字段拆分,也可以使用SQL语句中的函数进行字段拆分,这里我们将分别介绍这2种字段拆分的实现方式。
【方式一】-使用字段拆分插件进行拆分
操作步骤:
1、选择表输入并把它拖到右侧的编辑区中进行配置,主要是进行自定义SQL语句。
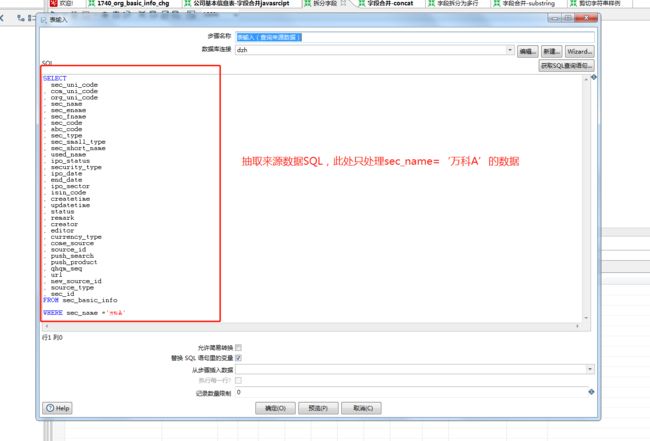
如截图所示,将来源库表信息进行填写或选择后,进行抽取SQL的定义,此处限制抽取数据的范围,只处理万科A的数据。
2、选择拆分字段并把它拖到右侧的编辑区中进行拆分字段配置。
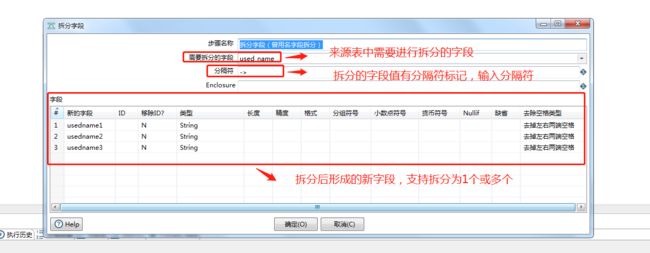
字段拆分插件有三个要点:
(1)选择需要进行拆分的字段,当前的例子是选择来源表的used_name字段;
(2)拆分的字段需要有分隔符标记,可以输入分割符,也可以定义变量,当前的例子是输入->;
(3)拆分后形成的新字段,定义新的字段名和相关字段属性,支持拆分为1个或多个字段,当前的例子我们拆分了三个新字段;
3、选择插入/更新并把它拖到右侧的编辑区中进行相关配置。
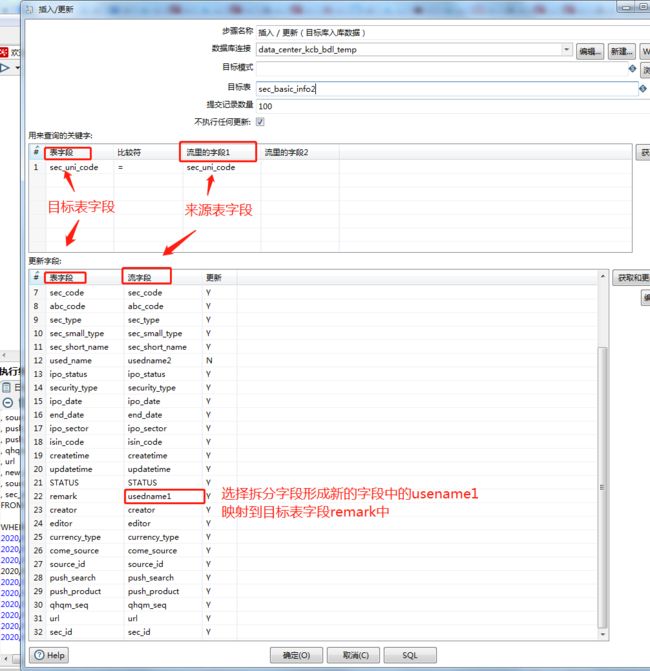
如截图所示,将拆分字段形成的新字段usename1与目标表字段remark进行映射,其他字段直接映射即可。
插入/更新配置完成后,保存转换文件,可点击【运行这个转换】按钮进行本地运
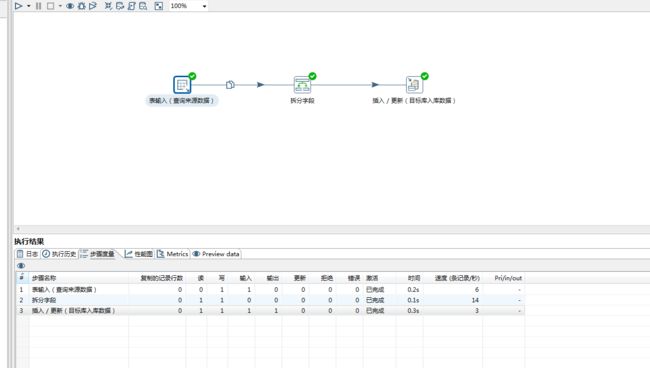
4、转换成功后,也可以检查本地数据库,查看数据是否推送成功,是否将字段进行正确拆分。
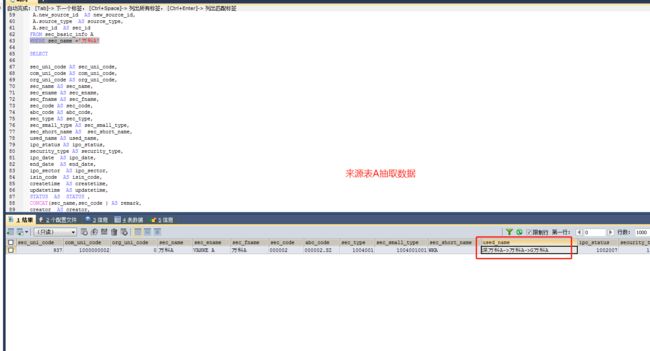
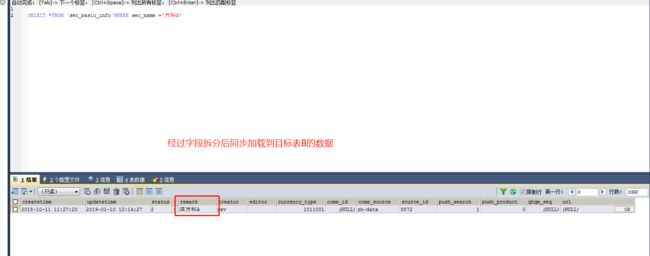
到这里,利用字段拆分插件进行字段拆分的转换就介绍完了,除了上述这种字段转化方式,我们可以使用SQL语句中 SUBSTRING函数更方便地进行字段拆分后推送。
【方式二】-使用SUBSTRING 函数进行字段拆分
SQL SUBSTRING 函数是用来截取字符串中的一部分字符的。针对以上字段拆分场景,接下来我们进行相关介绍。
1、选择表输入并把它拖到右侧的编辑区中进行配置,主要是进行自定义SQL语句。
SQL语句中,需要注意的2点:
(1)需要正确使用SUBSTRING函数,SUBSTRING_INDEX(used_name, '->', 1) AS used_name,代表截取来源表中used_name字段第1个 '->' 之前的所有字符;
(2)SQL语句的格式,AS 后是来源表抽取后的流字段。
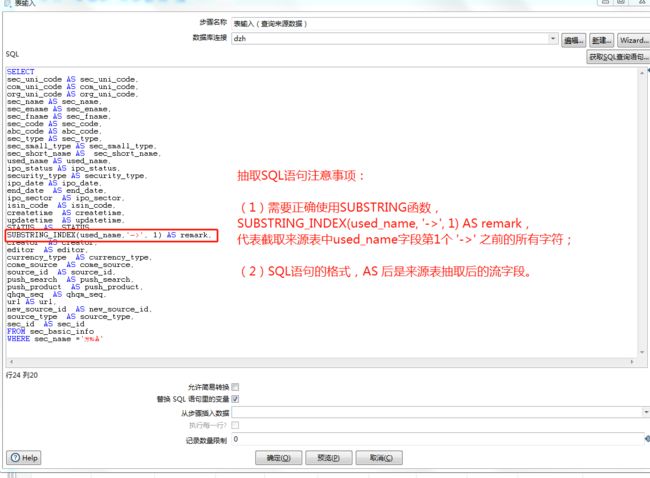
更多字符串截取函数的用法可参考:SQL中字符串截取函数(SUBSTRING)
2、选择插入/更新并把它拖到右侧的编辑区中进行相关配置。
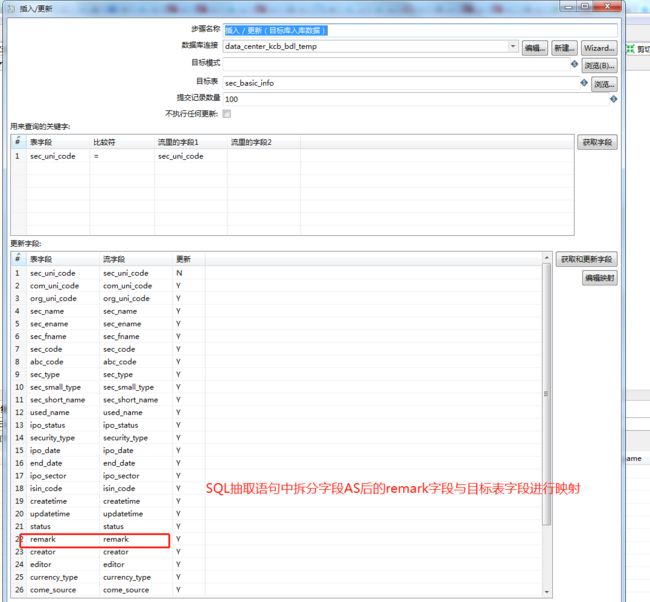
3、查看转换结果。
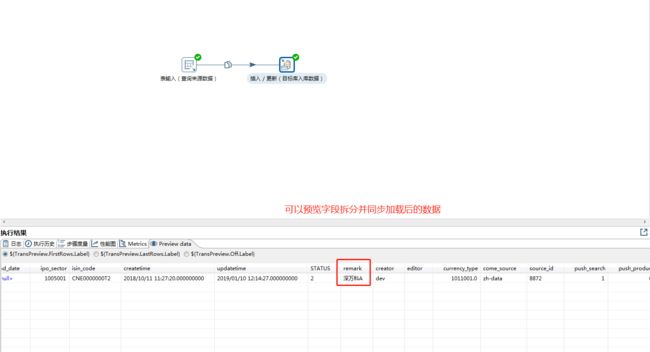
运行该转换配置,可以正常运行,并将来源表的字段进行正确拆分并同步到目标数据表。
在kettle的转换插件中,会发现与字段拆分相关的另外一个插件为【列拆分为多行】,这个插件的作用是拆分列里面的字段,且拆分后为多行数据,具体的操作方式可参考 kettle拆分列里面的字段。此处,不做赘述。
以上是字段合并和字段拆分2类转换场景的操作方式,在这一过程中,对产品经理而言,有哪些思考或启发?
在ETL1.0阶段,对于字段合并和字段拆分的业务需求,并没有很好地被满足;到了ETL2.0阶段,基于Kettle的ETL二次开发,多样性的转换需求实现起来显得如此轻松,有时候在想,如果当初丰富多样的转换场景可以准确地被抽象出来、可以给业务方提供友好的产品功能、技术上可以快速迭代上线,那么现在的ETL是什么样子?当然,在这里也不是否定站在kettle肩膀上二次开发的正确性,而是自责作为工具类产品经理,已开发工具没有很好用的反思。
坦白说,kettle工具也存在一些使用问题,比如说,配置项繁杂、操作没有很友好、上手的成本高。
产品的易用性和功能的复杂性如何达到平衡?这个问题也一直是ETL产品改进的方向。
如何使用最简单的方式去达到目标?如何让业务方提高使用效率?如何don’t make me think (too much)?
其实,我也已经有了答案。欢迎各位进一步交流哦!