飞桨PaddlePaddle-AI结营心得
前言
首先附录一下一周任务青2系列中值得关注的一些小点。总体来说,我觉得课程总体设计 通过 青2 这个任务情景 将各种任务串起来,有项目的初步框架。
Day2 《青春有你2》Python 爬虫 和人像动漫体验
Day4 《青春有你2》分类任务坑总
Day5《青春有你2》评论数据爬取与词云分析
心得
第一天的任务是利用python的基本知识完成一些编程题。青2 系列任务从第二天开始。首先是数据获取部分(是通过python爬虫实现),其次是数据分析(很多人可能会忽略这一步,我觉得吧不管是用机器学习算法还是深度学习模型,首先还是需要观察数据分布情况,根据数据分布,可以有哪些选择。比如之前我在检测样品里的生长的微结构,数量很多,大部分的小样品矩形区域比较小。当时考虑目标检测的两种模型SSD,Faster RCNN。区别一个是一阶段直接检测,一个两阶段过程。预测效果和训练的loss来看,SSD表现并不是那么好,loss一直没法收敛到一个比较小的值,尽管检测速度肯定比两阶段检测算法来的快。) 第四天就是自制图片数据集,对其进行分类。第五天,爬取爱奇艺 青2 的一段视频评论,作数据清洗方面的工作后,可视化展示和词云绘制。
在爬虫这块,之前学习也是直接跳过没学的。真的一开始觉得有点懵吧,课上讲的beautiful Soup 来处理,我觉得课程讲的比较简单。课后还是花一些心思去查各种文档,然后在pycharm上不停的调试来学习(我觉得调试这个功能真的非常强大。AI Studio 上的notebook 和 jupyter 我不是很喜欢的主要一个原因在于出错是输出不断上调的日志信息,有些错误呢我觉得光看这个是很难发现的,而且也并不是所有的信息都能print 出来,而且还很麻烦。)。 群里也有非常多的小伙伴懂这块,所以爬虫方面 非常感谢他们的帮助。
在数据分析这块,作业是可视化体重分布。本身任务不是很难。就是我觉得想不同的方法去实现 这是个有趣的过程。
从第二天我们获取的是一个json的文档格式保存了每位star 小姐姐的个人信息(文档里面保存的内容基本格式见下面):
{'小姐姐名字':{'信息1':'',
'信息2':'',
'信息3':'',
...,
'weight':'45kg',
...},
...
'小姐姐名字':{'信息1':'',
'信息2':'',
'信息3':'',
...,
'weight':'45kg',
...}
}
基本的思路,建立四个变量来存储四个区间的体重的计数。用判断语句来比较。不过呢,我就想试一下其他方法:
"""
我的第一个解法,是将符合条件的数据转换为四个区间的映射标签:1,2,3,4 . 从【1,1,3,4,3,...】中建立一个标签和数量的键值对,通过字典索引来获取信息。
"""
#读取数据
with open(os.path.join(os.getcwd(),"data","data31557",'20200422.json'),'r',encoding='UTF-8') as file:
json_array=json.loads(file.read())#读取json内容
#获取明星的体重并做统计分析
weights=[]
for star in json_array:
weights.append(int(star["weight"][0:2]))
# >55 记为1 50-55 记为2 45-50记为3( (45,50] ) <=45记为4
labels=[]
for weight in weights:
if weight>55:
labels.append(1)
elif weight>50:
labels.append(2)
elif weight>45:
labels.append(3)
else:
labels.append(4)
#创建统计个数的字典
flag=[">55kg",'50-55kg','45-50kg','<=45kg']
counts={} #每个标签的占比
labels_set=[]
for label in labels:
if label not in labels_set:
counts[flag[label-1]]=labels.count(label)
labels_set.append(label)
#画饼图
plt.figure(figsize=(9,8))
plt.rcParams['font.sans-serif']=['SimHei']#显示中文
#设置饼图标签
# color=['red','yellowgreen','yellow','lightskyblue']#或是十六进制表示
#将某部分分割数出来,使用括号,数值的小小是分割书来与其他两块的间隙
explode=(0,0,0.08,0.05)
patches,l_text,p_text=plt.pie([counts[flag[i]] for i in range(len(labels_set))],explode=explode,labels=flag,
labeldistance=1.1,autopct='%3.1f%%',
shadow=True,pctdistance=0.6,
startangle=60,
)
#设置x,y刻度一致,饼图才能使圆的
plt.axis('equal')
plt.title("《青春有你2》参赛选手体重分布",fontdict={'size':14})
plt.legend()
plt.show()
群里的小伙伴学习氛围也非常好,他们在讨论有没有能够代码量更小的方法。然后我就继续开动脑筋:
"""
另外一种解法,我是通过逻辑关系来做的,有四个区间就遍历了四次,每次将符合条件的置1,每次比较 是 a<= n < b 两个不等式,所以了这里用到相与 筛选出 两个不等式的交集。 这里列表的位置也是对应的区间的位置,所以呢就能根据索引取出相应的区间。 不过后来想想也没必要特意将列表转成了array数组
"""
#读取数据
with open(os.path.join(os.getcwd(),"data","data31557",'20200422.json'),'r',encoding='UTF-8') as file:
json_array=json.loads(file.read())#读取json内容
#获取明星的体重并做统计分析
weights=[]
for star in json_array:
weights.append(int(star["weight"][0:2]))
flag=['<=45kg','45-50kg','50-55kg',">55kg"]
condition=[0,45,50,55,100]
counts2=[]
weights=np.array(weights)
for epoch in range(len(flag)):#四个区间遍历
n_weight=np.where(weights<=condition[epoch+1],1,0)
n_weight2=np.where(weights>condition[epoch],1,0)
n_weight=np.logical_and(n_weight,n_weight2) #True 的部分是保留
counts2.append(np.sum(n_weight))
#画饼
plt.figure(figsize=(9,8))
plt.rcParams['font.sans-serif']=['SimHei']#显示中文
explode=(0.05,0.08,0,0)
patches,l_text,p_text=plt.pie(counts2,explode=explode,labels=flag,labeldistance=1.1,autopct='%3.1f%%',shadow=True,pctdistance=0.6,startangle=60)
#设置x,y刻度一致,饼图才能使圆的
plt.axis('equal')
plt.title("《青春有你2》参赛选手体重分布",fontdict={'size':14})
plt.legend()
plt.show()
另外一些方法,使用panda库来读取,里面集成了一种方法,能够直接返回元素的个数。总之方法也是挺多的。
效果:
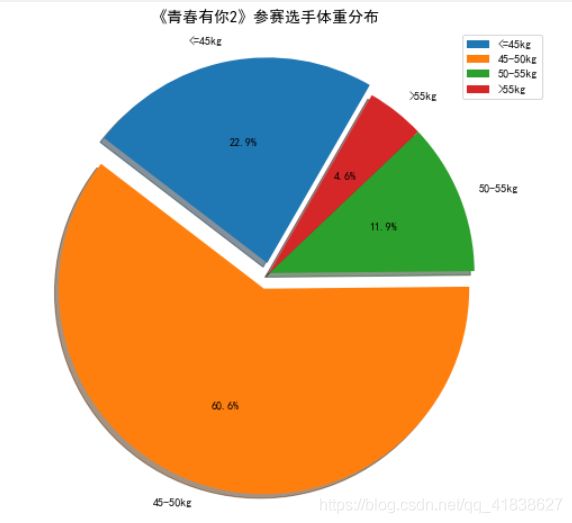
第四天的分类任务,评分指标5张图片预测的正确率。这样为了5张正确折腾了好久,大概有点理解了图片的光照、整体分布、姿势等等对于模型参数训练的影响。哎。(Resnet并不是大法,还是多点尝试下其他模型,想法不要总是被限制住了,【分类先考虑resnet 】)
第五天的综合大作业,我觉得有一定难度,因为爬虫这块我本来就不怎么熟悉。再加上有些事情忙,拖了一天才开始动工,基本群里小伙伴把要踩的出现的坑都全部讨论过了,所以我直接基本就是跳坑而过(有一点想要莫名的笑一下)。
不过也发现自己存在的一些问题 就是 学了就忘,忘了去查,捡了再丢,丢了再捡。以后还是要按个专题整理一下。各位小伙伴也一起加油吧(ง •_•)ง(没有好好喝的鸡汤)