PaddlePaddle深度学习7日入门 学习心得
虽然不是同一个时间,但是是同一个比赛,2月的时候通过朋友了解到了百度AI Studio平台举办的“七日入门深度学习”系列,等到这次疫情特辑才加入,还是学到了很多东西的。
这七天主要内容如下:
Day1:新冠疫情可视化
这一天主要是对爬取3月31日当天丁香园公开的统计数据,使用pyecharts绘制分布图。我通过调用饼图的API的如下代码,绘制如下图:
pie=Pie(init_opts=opts.InitOpts(width=‘1000px’, height=‘800px’))
pie.add(“全国疫情”, [list(z) for z in zip(labels,counts)],center=[“50%”,“60.5%”],radius=[“5%”, “75%”],)
pie.set_global_opts(title_opts=opts.TitleOpts(title="2020.3.31各省疫情"),legend_opts=opts.LegendOpts(pos_left="90%", orient="vertical",type_="scroll"),)
pie.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
pie.render("pie_base.html")

Day2:手势识别
这一天是一个多分类问题,通过对简单的DNN进行调参,训练模型,使得机器能够用较高的准确率识别图片中的手势:
import os
import time
import random
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import paddle
import paddle.fluid as fluid
import paddle.fluid.layers as layers
from multiprocessing import cpu_count
from paddle.fluid.dygraph import Pool2D,Conv2D
from paddle.fluid.dygraph import Linear
# 生成图像列表
data_path = '/home/aistudio/data/data23668/Dataset'
character_folders = os.listdir(data_path)
# print(character_folders)
if(os.path.exists('./train_data.list')):
os.remove('./train_data.list')
if(os.path.exists('./test_data.list')):
os.remove('./test_data.list')
for character_folder in character_folders:
with open('./train_data.list', 'a') as f_train:
with open('./test_data.list', 'a') as f_test:
if character_folder == '.DS_Store':
continue
character_imgs = os.listdir(os.path.join(data_path,character_folder))
count = 0
for img in character_imgs:
if img =='.DS_Store':
continue
if count%10 == 0:
f_test.write(os.path.join(data_path,character_folder,img) + '\t' + character_folder + '\n')
else:
f_train.write(os.path.join(data_path,character_folder,img) + '\t' + character_folder + '\n')
count +=1
print('列表已生成')
# 定义训练集和测试集的reader
def data_mapper(sample):
img, label = sample
img = Image.open(img)
img = img.resize((100, 100), Image.ANTIALIAS)
img = np.array(img).astype('float32')
img = img.transpose((2, 0, 1))
img = img/255.0
return img, label
def data_reader(data_list_path):
def reader():
with open(data_list_path, 'r') as f:
lines = f.readlines()
for line in lines:
img, label = line.split('\t')
yield img, int(label)
return paddle.reader.xmap_readers(data_mapper, reader, cpu_count(), 512)
# 用于训练的数据提供器
train_reader = paddle.batch(reader=paddle.reader.shuffle(reader=data_reader('./train_data.list'), buf_size=256), batch_size=32)
# 用于测试的数据提供器
test_reader = paddle.batch(reader=data_reader('./test_data.list'), batch_size=32)
#定义DNN网络
class MyDNN(fluid.dygraph.Layer):
def __init__(self):
super(MyDNN,self).__init__()
self.hidden2 = Linear(128,256,act='leaky_relu')
self.hidden3 = Linear(256,500,act='leaky_relu')
self.hidden4= Linear(500,100,act='leaky_relu')
self.hidden5 = Linear(3*100*100,10,act='softmax')
def forward(self,input):
x=self.hidden1(input)
x=self.hidden2(x)
x=self.hidden3(x)
x=self.hidden4(x)
x=fluid.layers.reshape(x,shape=[-1,3*100*100])
y=self.hidden5(x)
return y
#用动态图进行训练
with fluid.dygraph.guard():
model=MyDNN() #模型实例化
model.train() #训练模式
opt=fluid.optimizer.AdagradOptimizer(learning_rate=0.001, parameter_list=model.parameters())
# opt=fluid.optimizer.SGDOptimizer(learning_rate=0.001, parameter_list=model.parameters())
#优化器选用SGD随机梯度下降,学习率为0.001.正则化项0.1
# ,regularization=fluid.regularizer.L2Decay(regularization_coeff=0.01)
epochs_num=400 #迭代次数
for pass_num in range(epochs_num):
for batch_id,data in enumerate(train_reader()):
images=np.array([x[0].reshape(3,100,100) for x in data],np.float32)
labels = np.array([x[1] for x in data]).astype('int64')
labels = labels[:, np.newaxis]
# print(images.shape)
image=fluid.dygraph.to_variable(images)
label=fluid.dygraph.to_variable(labels)
predict=model(image)#预测
# print(predict)
loss=fluid.layers.cross_entropy(predict,label)
avg_loss=fluid.layers.mean(loss)#获取loss值
acc=fluid.layers.accuracy(predict,label)#计算精度
if batch_id!=0 and batch_id%50==0:
print("train_pass:{},batch_id:{},train_loss:{},train_acc:{}".format(pass_num,batch_id,avg_loss.numpy(),acc.numpy()))
avg_loss.backward()
opt.minimize(avg_loss)
model.clear_gradients()
fluid.save_dygraph(model.state_dict(),'MyDNN')#保存模型
#模型校验
with fluid.dygraph.guard():
accs = []
model_dict, _ = fluid.load_dygraph('MyDNN')
model = MyDNN()
model.load_dict(model_dict) #加载模型参数
model.eval() #训练模式
for batch_id,data in enumerate(test_reader()):#测试集
images=np.array([x[0].reshape(3,100,100) for x in data],np.float32)
labels = np.array([x[1] for x in data]).astype('int64')
labels = labels[:, np.newaxis]
image=fluid.dygraph.to_variable(images)
label=fluid.dygraph.to_variable(labels)
predict=model(image)
acc=fluid.layers.accuracy(predict,label)
accs.append(acc.numpy()[0])
avg_acc = np.mean(accs)
print(avg_acc)
#读取预测图像,进行预测
def load_image(path):
img = Image.open(path)
img = img.resize((100, 100), Image.ANTIALIAS)
img = np.array(img).astype('float32')
img = img.transpose((2, 0, 1))
img = img/255.0
print(img.shape)
return img
#构建预测动态图过程
with fluid.dygraph.guard():
infer_path = '手势.JPG'
model=MyDNN()#模型实例化
model_dict,_=fluid.load_dygraph('MyDNN')
model.load_dict(model_dict)#加载模型参数
model.eval()#评估模式
infer_img = load_image(infer_path)
infer_img=np.array(infer_img).astype('float32')
infer_img=infer_img[np.newaxis,:, : ,:]
infer_img = fluid.dygraph.to_variable(infer_img)
result=model(infer_img)
display(Image.open('手势.JPG'))
print(np.argmax(result.numpy()))
训练准确率为0.88839.
最终成功识别了手势为5的这张图片:

Day3:车牌识别
这一天使用经典的LeNet来达到对一张处理好的车牌图片各个数字及字母以及汉字进行识别,也是一个多分类问题:
#导入需要的包
import numpy as np
import paddle as paddle
import paddle.fluid as fluid
from PIL import Image
import cv2
import matplotlib.pyplot as plt
import os
from multiprocessing import cpu_count
from paddle.fluid.dygraph import Pool2D,Conv2D
# from paddle.fluid.dygraph import FC
from paddle.fluid.dygraph import Linear
# 生成车牌字符图像列表
data_path = '/home/aistudio/data'
character_folders = os.listdir(data_path)
label = 0
LABEL_temp = {}
if(os.path.exists('./train_data.list')):
os.remove('./train_data.list')
if(os.path.exists('./test_data.list')):
os.remove('./test_data.list')
for character_folder in character_folders:
with open('./train_data.list', 'a') as f_train:
with open('./test_data.list', 'a') as f_test:
if character_folder == '.DS_Store' or character_folder == '.ipynb_checkpoints' or character_folder == 'data23617':
continue
print(character_folder + " " + str(label))
LABEL_temp[str(label)] = character_folder #存储一下标签的对应关系
character_imgs = os.listdir(os.path.join(data_path, character_folder))
for i in range(len(character_imgs)):
if i%10 == 0:
f_test.write(os.path.join(os.path.join(data_path, character_folder), character_imgs[i]) + "\t" + str(label) + '\n')
else:
f_train.write(os.path.join(os.path.join(data_path, character_folder), character_imgs[i]) + "\t" + str(label) + '\n')
label = label + 1
print('图像列表已生成')
# 用上一步生成的图像列表定义车牌字符训练集和测试集的reader
def data_mapper(sample):
img, label = sample
img = paddle.dataset.image.load_image(file=img, is_color=False)
img = img.flatten().astype('float32') / 255.0
return img, label
def data_reader(data_list_path):
def reader():
with open(data_list_path, 'r') as f:
lines = f.readlines()
for line in lines:
img, label = line.split('\t')
yield img, int(label)
return paddle.reader.xmap_readers(data_mapper, reader, cpu_count(), 1024)
# 用于训练的数据提供器
train_reader = paddle.batch(reader=paddle.reader.shuffle(reader=data_reader('./train_data.list'), buf_size=512), batch_size=128)
# 用于测试的数据提供器
test_reader = paddle.batch(reader=data_reader('./test_data.list'), batch_size=128)
**#定义网络
class MyLeNet(fluid.dygraph.Layer):
def __init__(self):
super(MyLeNet,self).__init__()
self.hidden1_1 = Conv2D(1,28,5,1)
self.hidden1_2 = Pool2D(pool_size=2,pool_type='max',pool_stride=2)
self.hidden2_1 = Conv2D(28,32,3,1)
self.hidden2_2 = Pool2D(pool_size=2,pool_type='max',pool_stride=2)
self.hidden3_1 = Conv2D(32,64,2,1)
self.hidden3_2 = Pool2D(pool_size=2,pool_type='max',pool_stride=2)
self.hidden4 = Conv2D(64,64,1,1)
self.hidden5 = Linear(64*1*1,65,act='softmax')
def forward(self,input):
x=self.hidden1_1(input)
x=self.hidden1_2(x)
x=self.hidden2_1(x)
x=self.hidden2_2(x)
x=self.hidden3_1(x)
x=self.hidden3_2(x)
x=self.hidden4(x)
x=fluid.layers.reshape(x,shape=[-1,64*1*1])
# x=fluid.layers.dropout(x,dropout_prob=0.3)
y=self.hidden5(x)
return y
with fluid.dygraph.guard():
model=MyLeNet() #模型实例化
model.train() #训练模式
# opt=fluid.optimizer.SGDOptimizer(learning_rate=0.001, parameter_list=model.parameters())#优化器选用SGD随机梯度下降,学习率为0.001.
opt=fluid.optimizer.AdagradOptimizer(learning_rate=0.001,parameter_list=model.parameters())
epochs_num=200 #迭代次数为200
for pass_num in range(epochs_num):
for batch_id,data in enumerate(train_reader()):
images=np.array([x[0].reshape(1,20,20) for x in data],np.float32)
labels = np.array([x[1] for x in data]).astype('int64')
labels = labels[:, np.newaxis]
image=fluid.dygraph.to_variable(images)
label=fluid.dygraph.to_variable(labels)
predict=model(image)#预测
loss=fluid.layers.cross_entropy(predict,label)
avg_loss=fluid.layers.mean(loss)#获取loss值
acc=fluid.layers.accuracy(predict,label)#计算精度
if batch_id!=0 and batch_id%100==0:
print("train_pass:{},batch_id:{},train_loss:{},train_acc:{}".format(pass_num,batch_id,avg_loss.numpy(),acc.numpy()))
avg_loss.backward()
opt.minimize(avg_loss)
model.clear_gradients()
fluid.save_dygraph(model.state_dict(),'MyLeNet')#保存模型
#模型校验
with fluid.dygraph.guard():
accs = []
model=MyLeNet()#模型实例化
model_dict,_=fluid.load_dygraph('MyLeNet')
model.load_dict(model_dict)#加载模型参数
model.eval()#评估模式
for batch_id,data in enumerate(test_reader()):#测试集
images=np.array([x[0].reshape(1,20,20) for x in data],np.float32)
labels = np.array([x[1] for x in data]).astype('int64')
labels = labels[:, np.newaxis]
image=fluid.dygraph.to_variable(images)
label=fluid.dygraph.to_variable(labels)
predict=model(image)#预测
acc=fluid.layers.accuracy(predict,label)
accs.append(acc.numpy()[0])
avg_acc = np.mean(accs)
print(avg_acc)
# 对车牌图片进行处理,分割出车牌中的每一个字符并保存
license_plate = cv2.imread('./车牌.png')
gray_plate = cv2.cvtColor(license_plate, cv2.COLOR_RGB2GRAY)
ret, binary_plate = cv2.threshold(gray_plate, 175, 255, cv2.THRESH_BINARY)
result = []
for col in range(binary_plate.shape[1]):
result.append(0)
for row in range(binary_plate.shape[0]):
result[col] = result[col] + binary_plate[row][col]/255
character_dict = {}
num = 0
i = 0
while i < len(result):
if result[i] == 0:
i += 1
else:
index = i + 1
while result[index] != 0:
index += 1
character_dict[num] = [i, index-1]
num += 1
i = index
for i in range(8):
if i==2:
continue
padding = (170 - (character_dict[i][1] - character_dict[i][0])) / 2
ndarray = np.pad(binary_plate[:,character_dict[i][0]:character_dict[i][1]], ((0,0), (int(padding), int(padding))), 'constant', constant_values=(0,0))
ndarray = cv2.resize(ndarray, (20,20))
cv2.imwrite('./' + str(i) + '.png', ndarray)
def load_image(path):
img = paddle.dataset.image.load_image(file=path, is_color=False)
img = img.astype('float32')
img = img[np.newaxis, ] / 255.0
return img
#将标签进行转换
print('Label:',LABEL_temp)
match = {'A':'A','B':'B','C':'C','D':'D','E':'E','F':'F','G':'G','H':'H','I':'I','J':'J','K':'K','L':'L','M':'M','N':'N',
'O':'O','P':'P','Q':'Q','R':'R','S':'S','T':'T','U':'U','V':'V','W':'W','X':'X','Y':'Y','Z':'Z',
'yun':'云','cuan':'川','hei':'黑','zhe':'浙','ning':'宁','jin':'津','gan':'赣','hu':'沪','liao':'辽','jl':'吉','qing':'青','zang':'藏',
'e1':'鄂','meng':'蒙','gan1':'甘','qiong':'琼','shan':'陕','min':'闽','su':'苏','xin':'新','wan':'皖','jing':'京','xiang':'湘','gui':'贵',
'yu1':'渝','yu':'豫','ji':'冀','yue':'粤','gui1':'桂','sx':'晋','lu':'鲁',
'0':'0','1':'1','2':'2','3':'3','4':'4','5':'5','6':'6','7':'7','8':'8','9':'9'}
L = 0
LABEL ={}
for V in LABEL_temp.values():
LABEL[str(L)] = match[V]
L += 1
print(LABEL)
#构建预测动态图过程
with fluid.dygraph.guard():
model=MyLeNet()#模型实例化
model_dict,_=fluid.load_dygraph('MyLeNet')
model.load_dict(model_dict)#加载模型参数
model.eval()#评估模式
lab=[]
for i in range(8):
if i==2:
continue
infer_imgs = []
infer_imgs.append(load_image('./' + str(i) + '.png'))
infer_imgs = np.array(infer_imgs)
infer_imgs = fluid.dygraph.to_variable(infer_imgs)
result=model(infer_imgs)
lab.append(np.argmax(result.numpy()))
print(lab)
display(Image.open('./车牌.png'))
print('\n车牌识别结果为:',end='')
for i in range(len(lab)):
print(LABEL[str(lab[i])],end='')
最终训练准确率达到了0.9649。
成功识别下面这张车牌:

Day4:口罩分类
这一天是一个二分类问题,识别一张图片上的人是否戴口罩。
采用了VGGNet:

import os
import zipfile
import random
import json
import paddle
import sys
import numpy as np
from PIL import Image
from PIL import ImageEnhance
import paddle.fluid as fluid
from multiprocessing import cpu_count
import matplotlib.pyplot as plt
from paddle.fluid.dygraph import Pool2D,Conv2D
'''
参数配置
'''
train_parameters = {
"input_size": [3, 224, 224], #输入图片的shape
"class_dim": -1, #分类数
"src_path":"/home/aistudio/work/maskDetect.zip",#原始数据集路径
"target_path":"/home/aistudio/data/", #要解压的路径
"train_list_path": "/home/aistudio/data/train.txt", #train.txt路径
"eval_list_path": "/home/aistudio/data/eval.txt", #eval.txt路径
"readme_path": "/home/aistudio/data/readme.json", #readme.json路径
"label_dict":{}, #标签字典
"num_epochs": 20, #训练轮数
"train_batch_size": 16, #训练时每个批次的大小
"learning_strategy": { #优化函数相关的配置
"lr": 0.0001 #超参数学习率
}
}
一、数据准备
def unzip_data(src_path,target_path):
'''
解压原始数据集,将src_path路径下的zip包解压至data目录下
'''
if(not os.path.isdir(target_path + "maskDetect")):
z = zipfile.ZipFile(src_path, 'r')
z.extractall(path=target_path)
z.close()
def get_data_list(target_path,train_list_path,eval_list_path):
'''
生成数据列表
'''
#存放所有类别的信息
class_detail = []
#获取所有类别保存的文件夹名称
data_list_path=target_path+"maskDetect/"
class_dirs = os.listdir(data_list_path)
#总的图像数量
all_class_images = 0
#存放类别标签
class_label=0
#存放类别数目
class_dim = 0
#存储要写进eval.txt和train.txt中的内容
trainer_list=[]
eval_list=[]
#读取每个类别,['maskimages', 'nomaskimages']
for class_dir in class_dirs:
if class_dir != ".DS_Store":
class_dim += 1
#每个类别的信息
class_detail_list = {}
eval_sum = 0
trainer_sum = 0
#统计每个类别有多少张图片
class_sum = 0
#获取类别路径
path = data_list_path + class_dir
# 获取所有图片
img_paths = os.listdir(path)
for img_path in img_paths: # 遍历文件夹下的每个图片
name_path = path + '/' + img_path # 每张图片的路径
if class_sum % 10 == 0: # 每10张图片取一个做验证数据
eval_sum += 1 # test_sum为测试数据的数目
eval_list.append(name_path + "\t%d" % class_label + "\n")
else:
trainer_sum += 1
trainer_list.append(name_path + "\t%d" % class_label + "\n")#trainer_sum测试数据的数目
class_sum += 1 #每类图片的数目
all_class_images += 1 #所有类图片的数目
# 说明的json文件的class_detail数据
class_detail_list['class_name'] = class_dir #类别名称,如jiangwen
class_detail_list['class_label'] = class_label #类别标签
class_detail_list['class_eval_images'] = eval_sum #该类数据的测试集数目
class_detail_list['class_trainer_images'] = trainer_sum #该类数据的训练集数目
class_detail.append(class_detail_list)
#初始化标签列表
train_parameters['label_dict'][str(class_label)] = class_dir
class_label += 1
#初始化分类数
train_parameters['class_dim'] = class_dim
#乱序
random.shuffle(eval_list)
with open(eval_list_path, 'a') as f:
for eval_image in eval_list:
f.write(eval_image)
random.shuffle(trainer_list)
with open(train_list_path, 'a') as f2:
for train_image in trainer_list:
f2.write(train_image)
# 说明的json文件信息
readjson = {}
readjson['all_class_name'] = data_list_path #文件父目录
readjson['all_class_images'] = all_class_images
readjson['class_detail'] = class_detail
jsons = json.dumps(readjson, sort_keys=True, indent=4, separators=(',', ': '))
with open(train_parameters['readme_path'],'w') as f:
f.write(jsons)
print ('生成数据列表完成!')
二、模型配置
def custom_reader(file_list):
'''
自定义reader
'''
def reader():
with open(file_list, 'r') as f:
lines = [line.strip() for line in f]
for line in lines:
img_path, lab = line.strip().split('\t')
img = Image.open(img_path)
if img.mode != 'RGB':
img = img.convert('RGB')
img = img.resize((224, 224), Image.BILINEAR)
img = np.array(img).astype('float32')
img = img.transpose((2, 0, 1)) # HWC to CHW
img = img/255 # 像素值归一化
yield img, int(lab)
return reader
'''
参数初始化
'''
src_path=train_parameters['src_path']
target_path=train_parameters['target_path']
train_list_path=train_parameters['train_list_path']
eval_list_path=train_parameters['eval_list_path']
batch_size=train_parameters['train_batch_size']
'''
解压原始数据到指定路径
'''
unzip_data(src_path,target_path)
'''
划分训练集与验证集,乱序,生成数据列表
'''
#每次生成数据列表前,首先清空train.txt和eval.txt
with open(train_list_path, 'w') as f:
f.seek(0)
f.truncate()
with open(eval_list_path, 'w') as f:
f.seek(0)
f.truncate()
#生成数据列表
get_data_list(target_path,train_list_path,eval_list_path)
'''
构造数据提供器
'''
train_reader = paddle.batch(custom_reader(train_list_path),
batch_size=batch_size,
drop_last=True)
eval_reader = paddle.batch(custom_reader(eval_list_path),
batch_size=batch_size,
drop_last=True)
class ConvPool(fluid.dygraph.Layer):
'''卷积+池化'''
def __init__(self,
num_channels,
num_filters,
filter_size,
pool_size,
pool_stride,
groups,
pool_padding=0,
pool_type='max',
conv_stride=1,
conv_padding=0,
act=None):
super(ConvPool, self).__init__()
self._conv2d_list = []
for i in range(groups):
conv2d = self.add_sublayer( #返回一个由所有子层组成的列表。
'bb_%d' % i,
fluid.dygraph.Conv2D(
num_channels=num_channels, #通道数
num_filters=num_filters, #卷积核个数
filter_size=filter_size, #卷积核大小
stride=conv_stride, #步长
padding=conv_padding, #padding大小,默认为0
act=act)
)
self._conv2d_list.append(conv2d)
self._pool2d = fluid.dygraph.Pool2D(
pool_size=pool_size, #池化核大小
pool_type=pool_type, #池化类型,默认是最大池化
pool_stride=pool_stride, #池化步长
pool_padding=pool_padding #填充大小
)
def forward(self, inputs):
x = inputs
for conv in self._conv2d_list:
x = conv(x)
x = self._pool2d(x)
return x
class VGGNet(fluid.dygraph.Layer):
'''
VGG网络
'''
def __init__(self):
super(VGGNet, self).__init__()
self.convpool01 = ConvPool(
3,64,3,2,2,2,act="relu"
)
self.convpool02 = ConvPool(
64,128,3,2,2,2,act="relu"
)
self.convpool03 = ConvPool(
128,256,3,2,2,3,act="relu"
)
self.convpool04 = ConvPool(
256,512,3,2,2,3,act="relu"
)
self.convpool05 = ConvPool(
512,512,3,2,2,3,act="relu"
)
self.pool_5_shape = 512 * 5 * 5
self.fc01 = fluid.dygraph.Linear(self.pool_5_shape,4096,act='relu')
self.fc02 = fluid.dygraph.Linear(4096,4096,act='relu')
self.fc03 = fluid.dygraph.Linear(4096,2,act='softmax')
def forward(self, inputs, label=None):
"""前向计算"""
out = self.convpool01(inputs)
out = self.convpool02(out)
out = self.convpool03(out)
out = self.convpool04(out)
out = self.convpool05(out)
out = fluid.layers.reshape(out,shape=[-1,512*5*5])
out = self.fc01(out)
out = self.fc02(out)
out = self.fc03(out)
if label is not None:
acc = fluid.layers.accuracy(input=out,label=label)
return out, acc
else:
return out
三、模型训练 && 四、模型评估
all_train_iter=0
all_train_iters=[]
all_train_costs=[]
all_train_accs=[]
def draw_train_process(title,iters,costs,accs,label_cost,lable_acc):
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=20)
plt.ylabel("cost/acc", fontsize=20)
plt.plot(iters, costs,color='red',label=label_cost)
plt.plot(iters, accs,color='green',label=lable_acc)
plt.legend()
plt.grid()
plt.show()
def draw_process(title,color,iters,data,label):
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=20)
plt.ylabel(label, fontsize=20)
plt.plot(iters, data,color=color,label=label)
plt.legend()
plt.grid()
plt.show()
'''
模型训练
'''
#with fluid.dygraph.guard(place = fluid.CUDAPlace(0)):
with fluid.dygraph.guard():
print(train_parameters['class_dim'])
print(train_parameters['label_dict'])
vgg = VGGNet()
optimizer=fluid.optimizer.AdamOptimizer(learning_rate=train_parameters['learning_strategy']['lr'],parameter_list=vgg.parameters())
for epoch_num in range(train_parameters['num_epochs']):
for batch_id, data in enumerate(train_reader()):
dy_x_data = np.array([x[0] for x in data]).astype('float32')
y_data = np.array([x[1] for x in data]).astype('int64')
y_data = y_data[:, np.newaxis]
#将Numpy转换为DyGraph接收的输入
img = fluid.dygraph.to_variable(dy_x_data)
label = fluid.dygraph.to_variable(y_data)
out,acc = vgg(img,label)
loss = fluid.layers.cross_entropy(out, label)
avg_loss = fluid.layers.mean(loss)
#使用backward()方法可以执行反向网络
avg_loss.backward()
optimizer.minimize(avg_loss)
#将参数梯度清零以保证下一轮训练的正确性
vgg.clear_gradients()
all_train_iter=all_train_iter+train_parameters['train_batch_size']
all_train_iters.append(all_train_iter)
all_train_costs.append(loss.numpy()[0])
all_train_accs.append(acc.numpy()[0])
if batch_id % 1 == 0:
print("Loss at epoch {} step {}: {}, acc: {}".format(epoch_num, batch_id, avg_loss.numpy(), acc.numpy()))
draw_train_process("training",all_train_iters,all_train_costs,all_train_accs,"trainning cost","trainning acc")
draw_process("trainning loss","red",all_train_iters,all_train_costs,"trainning loss")
draw_process("trainning acc","green",all_train_iters,all_train_accs,"trainning acc")
#保存模型参数
fluid.save_dygraph(vgg.state_dict(), "vgg")
print("Final loss: {}".format(avg_loss.numpy()))
'''
模型校验
'''
with fluid.dygraph.guard():
model, _ = fluid.load_dygraph("vgg")
vgg = VGGNet()
vgg.load_dict(model)
vgg.eval()
accs = []
for batch_id, data in enumerate(eval_reader()):
dy_x_data = np.array([x[0] for x in data]).astype('float32')
y_data = np.array([x[1] for x in data]).astype('int')
y_data = y_data[:, np.newaxis]
img = fluid.dygraph.to_variable(dy_x_data)
label = fluid.dygraph.to_variable(y_data)
out, acc = vgg(img, label)
lab = np.argsort(out.numpy())
accs.append(acc.numpy()[0])
print(np.mean(accs))
五、模型预测
def load_image(img_path):
'''
预测图片预处理
'''
img = Image.open(img_path)
if img.mode != 'RGB':
img = img.convert('RGB')
img = img.resize((224, 224), Image.BILINEAR)
img = np.array(img).astype('float32')
img = img.transpose((2, 0, 1)) # HWC to CHW
img = img/255 # 像素值归一化
return img
label_dic = train_parameters['label_dict']
'''
模型预测
'''
with fluid.dygraph.guard():
model, _ = fluid.dygraph.load_dygraph("vgg")
vgg = VGGNet()
vgg.load_dict(model)
vgg.eval()
#展示预测图片
infer_path='/home/aistudio/data/data23615/infer_mask01.jpg'
img = Image.open(infer_path)
plt.imshow(img) #根据数组绘制图像
plt.show() #显示图像
#对预测图片进行预处理
infer_imgs = []
infer_imgs.append(load_image(infer_path))
infer_imgs = np.array(infer_imgs)
for i in range(len(infer_imgs)):
data = infer_imgs[i]
dy_x_data = np.array(data).astype('float32')
dy_x_data=dy_x_data[np.newaxis,:, : ,:]
img = fluid.dygraph.to_variable(dy_x_data)
out = vgg(img)
lab = np.argmax(out.numpy()) #argmax():返回最大数的索引
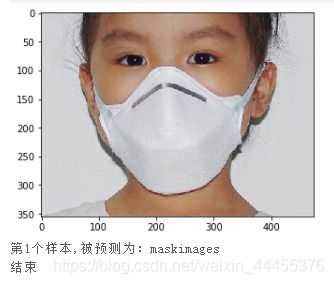
print("第{}个样本,被预测为:{}".format(i+1,label_dic[str(lab)]))
print("结束")
准确率最终接近1,可以说非常理想了。
成功识别图片:
Day5:人流密度检测(比赛)
要求参赛者给出一个算法或模型,对于给定的图片,统计图片中的总人数。给定图片数据,选手据此训练模型,为每张测试数据预测出最准确的人数。
这里使用了改进的VGGNet:
'''
加载相关类库
'''
import zipfile
import paddle
import paddle.fluid as fluid
import matplotlib.pyplot as plt
import matplotlib.image as mping
import json
import numpy as np
import cv2
import sys
import time
import h5py
from matplotlib import pyplot as plt
from scipy.ndimage.filters import gaussian_filter
import scipy
from matplotlib import cm as CM
from paddle.utils.plot import Ploter
from PIL import Image
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
'''
查看train.json相关信息,重点关注annotations中的标注信息
'''
f = open('/home/aistudio/data/data1917/train.json',encoding='utf-8')
content = json.load(f)
'''
将上面的到的content中的name中的“stage1/”去掉
'''
for j in range(len(content['annotations'])):
content['annotations'][j]['name'] = content['annotations'][j]['name'].lstrip('stage1').lstrip('/')
'''
使用高斯滤波变换生成密度图
'''
def gaussian_filter_density(gt):
# 初始化密度图
density = np.zeros(gt.shape, dtype=np.float32)
# 获取gt中不为0的元素的个数
gt_count = np.count_nonzero(gt)
# 如果gt全为0,就返回全0的密度图
if gt_count == 0:
return density
pts = np.array(list(zip(np.nonzero(gt)[1].ravel(), np.nonzero(gt)[0].ravel())))
for i, pt in enumerate(pts):
pt2d = np.zeros(gt.shape, dtype=np.float32)
pt2d[pt[1],pt[0]] = 1.
if gt_count > 1:
# sigma = (distances[i][1]+distances[i][2]+distances[i][3])*0.1
sigma = 25
else:
sigma = np.average(np.array(gt.shape))/2./2.
density += scipy.ndimage.filters.gaussian_filter(pt2d, sigma, mode='constant')
return density
'''
图片操作:对图片进行resize、归一化,将方框标注变为点标注
返回:resize后的图片 和 gt
'''
def picture_opt(img,ann):
size_x,size_y = img.size
train_img_size = (640,480)
img = img.resize(train_img_size,Image.ANTIALIAS)
img = np.array(img)
img = img / 255.0
gt = []
for b_l in range(len(ann)):
# 假设人体是使用方框标注的,通过求均值的方法将框变为点
if 'w' in ann[b_l].keys():
x = (ann[b_l]['x']+(ann[b_l]['x']+ann[b_l]['w']))/2
y = ann[b_l]['y']+20
x = (x*640/size_x)/8
y = (y*480/size_y)/8
gt.append((x,y))
else:
x = ann[b_l]['x']
y = ann[b_l]['y']
x = (x*640/size_x)/8
y = (y*480/size_y)/8
gt.append((x,y))
return img,gt
'''
密度图处理
'''
def ground(img,gt):
imgs = img
x = imgs.shape[0]/8
y = imgs.shape[1]/8
k = np.zeros((int(x),int(y)))
for i in range(0,len(gt)):
if int(gt[i][1]) < int(x) and int(gt[i][0]) < int(y):
k[int(gt[i][1]),int(gt[i][0])]=1
k = gaussian_filter_density(k)
return k
'''
定义数据生成器
'''
def train_set():
def inner():
for ig_index in range(2000): #遍历所有图片
if len(content['annotations'][ig_index]['annotation']) == 2:continue
if len(content['annotations'][ig_index]['annotation']) == 3:continue
if content['annotations'][ig_index]['ignore_region']: #把忽略区域都用像素为0填上
ig_list = [] #存放忽略区1的数据
ig_list1 = [] #存放忽略区2的数据
# print(content['annotations'][ig_index]['ignore_region'])
if len(content['annotations'][ig_index]['ignore_region'])==1: #因为每张图的忽略区域最多2个,这里是为1的情况
# print('ig1',ig_index)
ign_rge = content['annotations'][ig_index]['ignore_region'][0] #取第一个忽略区的数据
for ig_len in range(len(ign_rge)): #遍历忽略区坐标个数,组成多少变型
ig_list.append([ign_rge[ig_len]['x'],ign_rge[ig_len]['y']]) #取出每个坐标的x,y然后组成一个小列表放到ig_list
ig_cv_img = cv2.imread(content['annotations'][ig_index]['name']) #用cv2读取一张图片
pts = np.array(ig_list,np.int32) #把ig_list转成numpy.ndarray数据格式,为了填充需要
cv2.fillPoly(ig_cv_img,[pts],(0,0,0),cv2.LINE_AA) #使用cv2.fillPoly方法对有忽略区的图片用像素为0填充
ig_img = Image.fromarray(cv2.cvtColor(ig_cv_img,cv2.COLOR_BGR2RGB)) #cv2转PIL
ann = content['annotations'][ig_index]['annotation'] #把所有标注的信息读取出来
ig_im,gt = picture_opt(ig_img,ann)
k = ground(ig_im,gt)
groundtruth = np.asarray(k)
groundtruth = groundtruth.T.astype('float32')
ig_im = ig_im.transpose().astype('float32')
yield ig_im,groundtruth
if len(content['annotations'][ig_index]['ignore_region'])==2: #有2个忽略区域
# print('ig2',ig_index)
ign_rge = content['annotations'][ig_index]['ignore_region'][0]
ign_rge1 = content['annotations'][ig_index]['ignore_region'][1]
for ig_len in range(len(ign_rge)):
ig_list.append([ign_rge[ig_len]['x'],ign_rge[ig_len]['y']])
for ig_len1 in range(len(ign_rge1)):
ig_list1.append([ign_rge1[ig_len1]['x'],ign_rge1[ig_len1]['y']])
ig_cv_img2 = cv2.imread(content['annotations'][ig_index]['name'])
pts = np.array(ig_list,np.int32)
pts1 = np.array(ig_list1,np.int32)
cv2.fillPoly(ig_cv_img2,[pts],(0,0,0),cv2.LINE_AA)
cv2.fillPoly(ig_cv_img2,[pts1],(0,0,0),cv2.LINE_AA)
ig_img2 = Image.fromarray(cv2.cvtColor(ig_cv_img2,cv2.COLOR_BGR2RGB)) #cv2转PIL
ann = content['annotations'][ig_index]['annotation'] #把所有标注的信息读取出来
ig_im,gt = picture_opt(ig_img2,ann)
k = ground(ig_im,gt)
k = np.zeros((int(ig_im.shape[0]/8),int(ig_im.shape[1]/8)))
groundtruth = np.asarray(k)
groundtruth = groundtruth.T.astype('float32')
ig_im = ig_im.transpose().astype('float32')
yield ig_im,groundtruth
else:
img = Image.open(content['annotations'][ig_index]['name'])
ann = content['annotations'][ig_index]['annotation'] #把所有标注的信息读取出来
im,gt = picture_opt(img,ann)
k = ground(im,gt)
groundtruth = np.asarray(k)
groundtruth = groundtruth.T.astype('float32')
im = im.transpose().astype('float32')
yield im,groundtruth
return inner
BATCH_SIZE= 50 #每次取50张
# 设置训练reader
train_reader = paddle.batch(
paddle.reader.shuffle(
train_set(), buf_size=1024),
batch_size=BATCH_SIZE)
class CNN(fluid.dygraph.Layer):
'''
网络
'''
def __init__(self):
super(CNN, self).__init__()
self.conv01_1 = fluid.dygraph.Conv2D(num_channels=3, num_filters=8,filter_size=3,padding=1,act="relu")
self.conv01_2 = fluid.dygraph.Conv2D(num_channels=8, num_filters=16,filter_size=3, padding=1,act="relu")
self.pool01=fluid.dygraph.Pool2D(pool_size=2,pool_type='max',pool_stride=2)
self.conv02_1 = fluid.dygraph.Conv2D(num_channels=16, num_filters=32,filter_size=3, padding=1,act="relu")
self.conv02_2 = fluid.dygraph.Conv2D(num_channels=32, num_filters=64,filter_size=3, padding=1,act="relu")
self.pool02=fluid.dygraph.Pool2D(pool_size=2,pool_type='max',pool_stride=2)
self.conv03_1 = fluid.dygraph.Conv2D(num_channels=64, num_filters=128,filter_size=3, padding=1,act="relu")
self.conv03_2 = fluid.dygraph.Conv2D(num_channels=128, num_filters=256,filter_size=3, padding=1,act="relu")
self.pool03=fluid.dygraph.Pool2D(pool_size=2,pool_type='max',pool_stride=2)
self.conv04_1 = fluid.dygraph.Conv2D(num_channels=256, num_filters=512,filter_size=3, padding=1,act="relu")
self.conv04_2 = fluid.dygraph.Conv2D(num_channels=512, num_filters=1024,filter_size=3, padding=1,act="relu")
self.conv05_1 = fluid.dygraph.Conv2D(num_channels=1024, num_filters=2048,filter_size=3,padding=1, act="relu")
self.conv05_2 = fluid.dygraph.Conv2D(num_channels=2048, num_filters=1024,filter_size=3,padding=1, act="relu")
self.conv05_3 = fluid.dygraph.Conv2D(num_channels=1024, num_filters=512,filter_size=3,padding=1, act="relu")
self.conv06 = fluid.dygraph.Conv2D(num_channels=512,num_filters=256,filter_size=3,padding=1,act='relu')
self.conv07 = fluid.dygraph.Conv2D(num_channels=256,num_filters=128,filter_size=3,padding=1,act='relu')
self.conv08 = fluid.dygraph.Conv2D(num_channels=128,num_filters=64,filter_size=3,padding=1,act='relu')
self.conv08_1 = fluid.dygraph.Conv2D(num_channels=64,num_filters=32,filter_size=3,padding=1,act='relu')
self.conv08_2 = fluid.dygraph.Conv2D(num_channels=32,num_filters=16,filter_size=3,padding=1,act='relu')
self.conv08_3 = fluid.dygraph.Conv2D(num_channels=16,num_filters=8,filter_size=3,padding=1,act='relu')
self.conv09 = fluid.dygraph.Conv2D(num_channels=8,num_filters=1,filter_size=1,padding=0,act='relu')
def forward(self, inputs, label=None):
"""前向计算"""
out = self.conv01_1(inputs)
out = self.conv01_2(out)
out = self.pool01(out)
out = self.conv02_1(out)
out = self.conv02_2(out)
out = self.pool02(out)
out = self.conv03_1(out)
out = self.conv03_2(out)
out = self.pool03(out)
out = self.conv04_1(out)
out = self.conv04_2(out)
out = self.conv05_1(out)
out = self.conv05_2(out)
out = self.conv05_3(out)
out = self.conv06(out)
out = self.conv07(out)
out = self.conv08(out)
out = self.conv08_1(out)
out = self.conv08_2(out)
out = self.conv08_3(out)
out = self.conv09(out)
return out
'''
模型训练
'''
with fluid.dygraph.guard(place = fluid.CUDAPlace(0)):
cnn = CNN()
optimizer=fluid.optimizer.AdamOptimizer(learning_rate=0.0001,parameter_list=cnn.parameters()) #,regularization=fluid.regularizer.L2Decay(regularization_coeff=0.1)
for epoch_num in range(20):
for batch_id, data in enumerate(train_reader()):
dy_x_data = np.array([x[0] for x in data]).astype('float32')
y_data = np.array([x[1] for x in data]).astype('float32')
y_data = y_data[:,np.newaxis]
#将Numpy转换为DyGraph接收的输入
img = fluid.dygraph.to_variable(dy_x_data)
label = fluid.dygraph.to_variable(y_data)
label.stop_gradient = True
out = cnn(img,label)
loss = fluid.layers.square_error_cost(out, label)
avg_loss = fluid.layers.mean(loss)
#使用backward()方法可以执行反向网络
avg_loss.backward()
optimizer.minimize(avg_loss)
#将参数梯度清零以保证下一轮训练的正确性
cnn.clear_gradients()
dy_param_value = {}
for param in cnn.parameters():
dy_param_value[param.name] = param.numpy
if batch_id % 10 == 0:
print("Loss at epoch {} step {}: {}".format(epoch_num, batch_id, avg_loss.numpy()))
#保存模型参数
fluid.save_dygraph(cnn.state_dict(), "cnn")
print("Final loss: {}".format(avg_loss.numpy()))
data_dict = {}
'''
模型预测
'''
with fluid.dygraph.guard():
model, _ = fluid.dygraph.load_dygraph("cnn")
cnn = CNN()
cnn.load_dict(model)
cnn.eval()
#获取预测图片列表
test_zfile = zipfile.ZipFile("/home/aistudio/data/data1917/test_new.zip")
l_test = []
for test_fname in test_zfile.namelist()[1:]:
l_test.append(test_fname)
for index in range(len(l_test)):
test_img = Image.open(l_test[index])
test_img = test_img.resize((640,480))
test_im = np.array(test_img)
test_im = test_im / 255.0
test_im = test_im.transpose().reshape(3,640,480).astype('float32')
l_test[index] = l_test[index].lstrip('test').lstrip('/')
dy_x_data = np.array(test_im).astype('float32')
dy_x_data=dy_x_data[np.newaxis,:, : ,:]
img = fluid.dygraph.to_variable(dy_x_data)
out = cnn(img)
temp=out[0][0]
temp=temp.numpy()
people =np.sum(temp)
data_dict[l_test[index]]=int(people)
import csv
with open('results5.csv', 'w') as csvfile:
fieldnames = ['id', 'predicted']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for k,v in data_dict.items():
writer.writerow({'id': k, 'predicted':v})
print("结束")
Day6:PaddleSlim模型压缩
调用PaddleSlim对模型压缩使得整个模型轻量化。
0. 安装paddleslim
!pip install paddleslim
1. 导入依赖
import paddle
import paddle.fluid as fluid
import paddleslim as slim
import numpy as np
2. 构建模型
use_gpu = fluid.is_compiled_with_cuda()
exe, train_program, val_program, inputs, outputs = slim.models.image_classification("MobileNet", [1, 28, 28], 10, use_gpu=use_gpu)
place = fluid.CUDAPlace(0) if fluid.is_compiled_with_cuda() else fluid.CPUPlace()
3. 定义输入数据
import paddle.dataset.mnist as reader
train_reader = paddle.batch(
reader.train(), batch_size=128, drop_last=True)
test_reader = paddle.batch(
reader.test(), batch_size=128, drop_last=True)
data_feeder = fluid.DataFeeder(inputs, place)
4. 训练和测试
def train(prog):
iter = 0
for data in train_reader():
acc1, acc5, loss = exe.run(prog, feed=data_feeder.feed(data), fetch_list=outputs)
if iter % 100 == 0:
print('train iter={}, top1={}, top5={}, loss={}'.format(iter, acc1.mean(), acc5.mean(), loss.mean()))
iter += 1
def test(prog):
iter = 0
res = [[], []]
for data in test_reader():
acc1, acc5, loss = exe.run(prog, feed=data_feeder.feed(data), fetch_list=outputs)
if iter % 100 == 0:
print('test iter={}, top1={}, top5={}, loss={}'.format(iter, acc1.mean(), acc5.mean(), loss.mean()))
res[0].append(acc1.mean())
res[1].append(acc5.mean())
iter += 1
print('final test result top1={}, top5={}'.format(np.array(res[0]).mean(), np.array(res[1]).mean()))
train(train_program)
train iter=0, top1=0.0703125, top5=0.4609375, loss=2.77347970009
train iter=100, top1=0.9296875, top5=1.0, loss=0.234930545092
train iter=200, top1=0.9375, top5=1.0, loss=0.20704357326
train iter=300, top1=0.9375, top5=0.9921875, loss=0.174053370953
train iter=400, top1=0.9375, top5=1.0, loss=0.235098466277
test(val_program)
test iter=0, top1=0.96875, top5=1.0, loss=0.15132625401
final test result top1=0.959735572338, top5=0.998497605324
#训练部分的层
for block in train_program.blocks:
for param in block.all_parameters():
print("param: {}; shape: {}".format(param.name, param.shape))
#测试部分的层
for block in val_program.blocks:
for param in block.all_parameters():
print("param: {}; shape: {}".format(param.name, param.shape))
5. 量化模型
place = exe.place
# loss = 0.01
# ratios = slim.prune.get_ratios_by_loss(s_0, loss)
# print(ratios)
# pruner = slim.prune.Pruner()
# print("FLOPs before pruning: {}".format(slim.analysis.flops(train_program)))
quant_program = slim.quant.quant_aware(train_program, exe.place, for_test=False) #请在次数添加你的代码
# print("FLOPs after pruning: {}".format(slim.analysis.flops(quant_program)))
val_quant_program = slim.quant.quant_aware(val_program, exe.place, for_test=True) #请在次数添加你的代码
# print("FLOPs after pruning: {}".format(slim.analysis.flops(val_quant_program)))
6. 训练和测试量化后的模型
train(quant_program)
train iter=0, top1=0.9453125, top5=0.9921875, loss=0.114810302854
train iter=100, top1=0.9765625, top5=1.0, loss=0.0473967976868
train iter=200, top1=0.9921875, top5=1.0, loss=0.0467127114534
train iter=300, top1=0.984375, top5=1.0, loss=0.080812484026
train iter=400, top1=0.96875, top5=1.0, loss=0.1142252236
test(val_quant_program)
test iter=0, top1=0.9765625, top5=1.0, loss=0.103966884315
final test result top1=0.968549668789, top5=0.999399065971
可以发现,测试量化后的模型,和之前训练和测试中得到的测试结果相比,精度相近,达到了无损量化。
Day7:总结
避免过拟合:
减少网络参数量;仅保存验证集上表现较好的模型
进一步调优:
采用学习率调度器;选择合适的超参数
使用黑科技:
FRB(对网络进行细分,增加少量计算量的情况下来降低显存占用,提升batch大小);
PaddleHub;PaddleX