强化学习策略梯度梳理3-SOTA上(附PPO2代码)
强化学习策略梯度梳理-SOTA上
- 强化学习策略梯度梳理-SOTA
- 进阶方向1
- PG
- 总结
- TRPO
- natural policy gradient
- Importance sampling
- Trust Regions
- ACKTR
- 目标是为了提高TRPO的计算效率
- PPO
- 保留了TRPO的约束条件
- PPO1
- PPO2
- code
- 实验结果
强化学习策略梯度梳理-SOTA
这个部分主要参考周博磊老师的第六节的顺序
主要参考课程 Intro to Reinforcement Learning,Bolei Zhou
相关文中代码 https://github.com/ThousandOfWind/RL-basic-alg.git
进阶方向1
PG
首先策略的优化目标是
J ( θ ) = E τ ∼ π θ [ R ( τ ) ] J(\theta)=\mathbb{E}_{\tau \sim \pi_{\theta}}[R(\tau)] J(θ)=Eτ∼πθ[R(τ)]
策略梯度的计算方法
∇ θ J ( θ ) = E π θ [ G t ∇ θ log π θ ( s , a ) ] ≈ 1 N ∑ i = 1 N G t i ∇ θ log π θ ( s i , a i ) \begin{aligned} \nabla_{\theta} J(\theta) &=\mathbb{E}_{\pi_{\theta}}\left[G_{t} \nabla_{\theta} \log \pi_{\theta}(s, a)\right] \\ & \approx \frac{1}{N} \sum_{i=1}^{N} G_{t}^{i} \nabla_{\theta} \log \pi_{\theta}\left(s_{i}, a_{i}\right) \end{aligned} ∇θJ(θ)=Eπθ[Gt∇θlogπθ(s,a)]≈N1i=1∑NGti∇θlogπθ(si,ai)
通过引入baseline我们可以削减方差
A π ( s , a ) = Q π ( s , a ) − V π ( s ) A^{\pi}(s, a)=Q^{\pi}(s, a)-V^{\pi}(s) Aπ(s,a)=Qπ(s,a)−Vπ(s)
这里我还有个不太明白的地方, 为什么baseline可以用state value替代,因为我们期待的baseline应该是与策略无关吧, 但是V多多少少还是和策略有关呀,也可能我理解错了
总结
好精辟,这我不得背下来!
∇ θ J ( θ ) = E π θ [ ∇ θ log π θ ( s , a ) G t ] − REINFORCE = E π θ [ ∇ θ log π θ ( s , a ) Q w ( s , a ) ] − Q Actor-Critic = E π θ [ ∇ θ log π θ ( s , a ) A w ( s , a ) ] − Advantage Actor-Critic = E π θ [ ∇ θ log π θ ( s , a ) δ ] − TD Actor-Critic \begin{aligned} \nabla_{\theta} J(\theta) &=\mathbb{E}_{\pi_{\theta}}\left[\nabla_{\theta} \log \pi_{\theta}(s, a) G_{t}\right]-\text { REINFORCE } \\ &=\mathbb{E}_{\pi_{\theta}}\left[\nabla_{\theta} \log \pi_{\theta}(s, a) Q^{\mathrm{w}}(s, a)\right]-\text { Q Actor-Critic } \\ &=\mathbb{E}_{\pi_{\theta}}\left[\nabla_{\theta} \log \pi_{\theta}(s, a) A^{\mathrm{w}}(s, a)\right]-\text { Advantage Actor-Critic } \\ &=\mathbb{E}_{\pi_{\theta}}\left[\nabla_{\theta} \log \pi_{\theta}(s, a) \delta\right]-\text { TD Actor-Critic } \end{aligned} ∇θJ(θ)=Eπθ[∇θlogπθ(s,a)Gt]− REINFORCE =Eπθ[∇θlogπθ(s,a)Qw(s,a)]− Q Actor-Critic =Eπθ[∇θlogπθ(s,a)Aw(s,a)]− Advantage Actor-Critic =Eπθ[∇θlogπθ(s,a)δ]− TD Actor-Critic
TRPO
Trust region policy optimization. Schulman, L., Moritz, Jordan, Abbeel. 2015
考虑到PG的存在的两大问题:
- 采样效率低(on-policy)
- 容易收敛到局部最优
为了使得训练更稳定 -> Trust region & natural policy gradient
make it as off-policy policy optimization -> 重要性采样
natural policy gradient
这里数学过量。。。我姑且先放弃。话说周博磊老师视频讲natural policy gradient真的是贼来劲
请参考强化学习进阶 第七讲 TRPO
Importance sampling
我们知道策略梯度一个问题是只能on-policy,对经验的利用率很低,但如果加入重要性采样,我们就可以把过去的样本也利用上了
E x ∼ p [ f ( x ) ] = ∫ p ( x ) f ( x ) d x = ∫ q ( x ) p ( x ) q ( x ) f ( x ) d x = E x ∼ q [ p ( x ) q ( x ) f ( x ) ] \mathbb{E}_{x \sim p}[f(x)]=\int p(x) f(x) d x=\int q(x) \frac{p(x)}{q(x)} f(x) d x=\mathbb{E}_{x \sim q}\left[\frac{p(x)}{q(x)} f(x)\right] Ex∼p[f(x)]=∫p(x)f(x)dx=∫q(x)q(x)p(x)f(x)dx=Ex∼q[q(x)p(x)f(x)]
J ( θ ) = E a ∼ π θ [ r ( s , a ) ] = E a ∼ π ^ [ π θ ( s , a ) π ^ ( s , a ) r ( s , a ) ] J(\theta)=\mathbb{E}_{a \sim \pi_{\theta}}[r(s, a)]=\mathbb{E}_{a \sim \hat{\pi}}\left[\frac{\pi_{\theta}(s, a)}{\hat{\pi}(s, a)} r(s, a)\right] J(θ)=Ea∼πθ[r(s,a)]=Ea∼π^[π^(s,a)πθ(s,a)r(s,a)]
Trust Regions
尽管如此,我们还是不希望我们将要用的经验距离现在的目标区别太大,
所以我们可以用KL散度进行约束
K L ( π θ o l d ∥ π θ ) = − ∑ a π θ o l d ( a ∣ s ) log π θ ( a ∣ s ) π θ o l d ( a ∣ s ) K L\left(\pi_{\theta_{o l d}} \| \pi_{\theta}\right)=-\sum_{a} \pi_{\theta_{o l d}}(a \mid s) \log \frac{\pi_{\theta}(a \mid s)}{\pi_{\theta_{o l d}}(a \mid s)} KL(πθold∥πθ)=−a∑πθold(a∣s)logπθold(a∣s)πθ(a∣s)
这样我们就得到了优化目标,然后再用拉格朗日法求解
J θ old ( θ ) = E t [ π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) R t ] subject to K L ( π θ old ( ⋅ ∣ s t ) ∥ π θ ( ⋅ ∣ s t ) ) ≤ δ \begin{array}{l} J_{\theta_{\text {old }}}(\theta)=\mathbb{E}_{t}\left[\frac{\pi_{\theta}\left(a_{t} \mid s_{t}\right)}{\pi_{\theta_{\text {old }}}\left(a_{t} \mid s_{t}\right)} R_{t}\right] \\ \text { subject to } K L\left(\pi_{\theta_{\text {old }}}\left(\cdot \mid s_{t}\right) \| \pi_{\theta}\left(\cdot \mid s_{t}\right)\right) \leq \delta \end{array} Jθold (θ)=Et[πθold (at∣st)πθ(at∣st)Rt] subject to KL(πθold (⋅∣st)∥πθ(⋅∣st))≤δ
由于TRPO涉及了大量会把我绕晕的理论我也姑且先不复现了
ACKTR
Y. Wu, et al. “Scalable trust-region method for deep reinforcement learning using Kronecker-factored approximation”. NIPS 2017
目标是为了提高TRPO的计算效率
SGD 是一阶优化
natural policy gradient 二阶优化,单数需要矩阵求逆,计算销量较低
K-FAC 不断分解矩阵,把大矩阵求逆变换成小矩阵求逆
PPO
保留了TRPO的约束条件
maximize θ E t [ π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) A t ] subject to E t [ K L [ π θ o l d ( . ∣ s t ) , π θ ( . ∣ s t ) ] ] ≤ δ \begin{array}{l} \operatorname{maximize}_{\theta} \mathbb{E}_{t}\left[\frac{\pi_{\theta}\left(a_{t} \mid s_{t}\right)}{\pi_{\theta_{o l d}}\left(a_{t} \mid s_{t}\right)} A_{t}\right] \\ \text { subject to } \mathbb{E}_{t}\left[K L\left[\pi_{\theta_{o l d}}\left(. \mid s_{t}\right), \pi_{\theta}\left(. \mid s_{t}\right)\right]\right] \leq \delta \end{array} maximizeθEt[πθold(at∣st)πθ(at∣st)At] subject to Et[KL[πθold(.∣st),πθ(.∣st)]]≤δ
unconstrained form ->
maximize θ E t [ π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) A t ] − β E t [ K L [ π θ old ( ⋅ ∣ s t ) , π θ ( . ∣ s t ) ] ] \operatorname{maximize}_{\theta} \mathbb{E}_{t}\left[\frac{\pi_{\theta}\left(a_{t} \mid s_{t}\right)}{\pi_{\theta_{\text {old }}}\left(a_{t} \mid s_{t}\right)} A_{t}\right]-\beta \mathbb{E}_{t}\left[K L\left[\pi_{\theta_{\text {old }}}\left(\cdot \mid s_{t}\right), \pi_{\theta}\left(. \mid s_{t}\right)\right]\right] maximizeθEt[πθold (at∣st)πθ(at∣st)At]−βEt[KL[πθold (⋅∣st),πθ(.∣st)]]
PPO1
自适应优化

PPO2
这个实现除了周老师的tuturial还参考了https://github.com/zhangchuheng123/Reinforcement-Implementation/blob/master/code/ppo.py
记probability ratio 为
r t ( θ ) = π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) r_{t}(\theta)=\frac{\pi_{\theta}\left(a_{t} \mid s_{t}\right)}{\pi_{\theta_{\text {old }}}\left(a_{t} \mid s_{t}\right)} rt(θ)=πθold (at∣st)πθ(at∣st)
用clip将这个值限定在一定范围内
L t ( θ ) = min ( r t ( θ ) A ^ t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A ^ t ) L_{t}(\theta)=\min \left(r_{t}(\theta) \hat{A}_{t}, \operatorname{clip}\left(r_{t}(\theta), 1-\epsilon, 1+\epsilon\right) \hat{A}_{t}\right) Lt(θ)=min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)
因此
当advantage 为正,loss 有上界
L ( θ ; θ o l d ) = min ( π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) , ( 1 + ϵ ) ) A ^ t L\left(\theta ; \theta_{o l d}\right)=\min \left(\frac{\pi_{\theta}\left(a_{t} \mid s_{t}\right)}{\pi_{\theta_{o l d}}\left(a_{t} \mid s_{t}\right)},(1+\epsilon)\right) \hat{A}_{t} L(θ;θold)=min(πθold(at∣st)πθ(at∣st),(1+ϵ))A^t
否则,有下界
L ( θ ; θ o l d ) = max ( π θ ( a t ∣ s t ) π θ o l d ( a t ∣ s t ) , ( 1 − ϵ ) ) A ^ t L\left(\theta ; \theta_{o l d}\right)=\max \left(\frac{\pi_{\theta}\left(a_{t} \mid s_{t}\right)}{\pi_{\theta_{o l d}}\left(a_{t} \mid s_{t}\right)},(1-\epsilon)\right) \hat{A}_{t} L(θ;θold)=max(πθold(at∣st)πθ(at∣st),(1−ϵ))A^t
因此

code
首先是动作部分,这里需要返回把做选择时候的action_log_probs以及value都保存到经验池
def get_action(self, observation, *arg):
obs = th.FloatTensor(observation)
action_index, value, action_log_probs, _ = self.ac.select_action(obs=obs)
return int(action_index), action_log_probs, value
然后是训练部分,可以拆开看其中的两个主要部分:
首先是计算advantage:
最简单的版本是:
advangtage = th.zeros_like(reward)
pre_return = 0
for i in range(advangtage.shape[0]-1, -1, -1):
pre_return = reward[i] + (1 - done[i]) * self.gamma * pre_return
advangtage[i] = pre_return - value[i]
高级版本里面可以用到 λ \lambda λ 的思路
advangtage = th.zeros_like(reward)
returns = th.zeros_like(reward)
deltas = th.zeros_like(reward)
pre_return = 0
pre_value = 0
pre_advantage = 0
for i in range(advangtage.shape[0]-1, -1, -1):
returns[i] = reward[i] + (1 - done[i]) * self.gamma * pre_return
deltas[i] = reward[i] + (1 - done[i]) * self.gamma * pre_value - value[i]
advangtage[i] = deltas[i] + (1 - done[i]) * self.gamma * self.lamda * pre_advantage
pre_return = returns[i]
pre_value = value[i]
pre_advantage = advangtage[i]
然后是训练,可以注意到loss有三个部分组成
minibatch_new_value, minibatch_new_action_log_prob, minibatch_dist_entropy, _ \
= self.ac.evaluate_actions(obs=minibatch_obs, action=action_index)
ratio = th.exp(minibatch_old_action_log_prob - minibatch_new_action_log_prob)
surr1 = ratio * minibatch_advantange
surr2 = ratio.clamp( 1 - self.clip, 1 + self.clip)
loss_surr = - th.mean(th.min(surr1, surr2))
if self.lossvalue_norm:
minibatch_return_6std = 6 * minibatch_return.std()
loss_value = th.mean((minibatch_new_value - minibatch_return).pow(2))/minibatch_return_6std
else:
loss_value = th.mean((minibatch_new_value - minibatch_return).pow(2))
loss_entropy = th.mean(th.exp(minibatch_new_action_log_prob) * minibatch_new_action_log_prob)
total_loss = loss_surr + self.loss_coeff_value * loss_value + self.loss_coeff_entropy * loss_entropy
self.optimiser.zero_grad()
total_loss.backward()
self.optimiser.step()
最后呢有一个需要注意到部分是关于存储和采样的几个小细节,
- 一般复现都是用rollout storage。我其实还困惑了蛮久,这和DQN的memory buffer有什么区别,但是经过反复对比验证,可能主要区别就在于DQN中理想情况下是不会丢弃旧经验的,但是在rollout storage中会有一个固定的相对小的空间,遵循先入先出原则。
- 每次训练的时候实际上是取得所有存储的样本,然后对这些些样本做几次随机采样,并进行训练
def learn(self, memory):
batch = memory.get_current_trajectory()
obs = th.FloatTensor(batch['observation'])
action_index = th.LongTensor(batch['action_index'])
next_obs = th.FloatTensor(batch['next_obs'])
reward = th.FloatTensor(batch['reward'])
done = th.FloatTensor(batch['done'])
old_action_log_prob = th.FloatTensor(batch['action_log_prob'])
value = th.FloatTensor(batch['value'])
...
for _ in range(self.ppo_epoch):
minibatch_ind = np.random.choice(self.batch_size, self.minibatch_size, replace=False)
minibatch_obs = obs[minibatch_ind]
minibatch_old_action_log_prob = old_action_log_prob[minibatch_ind]
minibatch_advantange = advangtage[minibatch_ind]
minibatch_return = returns[minibatch_ind]
...
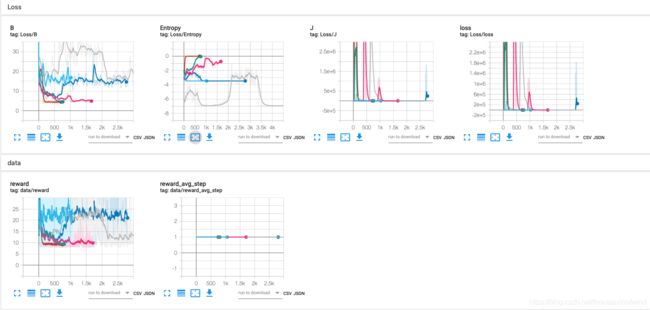
实验结果
loss 因为loss有三个项, 他们回传的程度分别是
| loss_surr | loss_value | loss_entropy |
|---|---|---|
| 1 | loss_coeff_value | loss_coeff_entropy |
需要自己调节吧,
- 当熵回传的比重低,就会早早停在一个不太好的解
- 当熵回传的比重高,策略就会倾向于均匀动作,相当于啥也没学到
- 感觉其实挺难调到好的解的
动作倾向
可以看到动作倾向黄了,这说明策略是相对匀称,
可能是他终于明白这个环境要求匀称的策略
但鉴于结果还是不太好,也可能只是最大熵push它表现出这种策略
