【代码】python 非minist数据(jpg、png等)转minist格式数据集
2019.12.23号更新!!!!!法一搞不定就看法二,有半年没接触过这个转换代码了,大家试试看,我之前是可以用的
法一:
###############################################################################333
注意几点:
1.只支持“正方形”的数据(width==height)的图片 (目前还没找到好的解决方案)我尝试改了一下,希望你们顺利
2.默认将图片转为灰度图
3.基于github上https://github.com/gskielian/JPG-PNG-to-MNIST-NN-Format的代码,调试运行成功!
4.数据格式:和代码1、2同目录下:
![]()
其中两个图片文件夹下分别为各个类(例如:0/1/2/3/4/5/6).每个类文件夹里对应多张图片
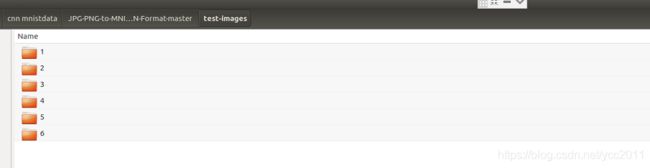
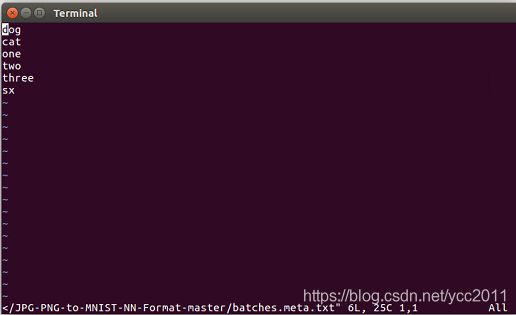
batches.meta.txt 为对应类别的名称。
代码1: 裁剪尺寸和转换为灰度图代码:(代码尺寸默认28x28 自己修改自己的尺寸,但必须width==height)
resize-script.sh
#!/bin/bash
#simple script for resizing images in all class directories
#also reformats everything from whatever to png
if [ `ls test-images/*/*.jpg 2> /dev/null | wc -l ` -gt 0 ]; then
echo hi
for file in test-images/*/*.jpg; do
convert "$file" -resize 64x128\! "${file%.*}.png"
convert "$file" -set colorspace Gray -separate -average "${file%.*}.png"
file "$file" #uncomment for testing
rm "$file"
done
fi
if [ `ls test-images/*/*.png 2> /dev/null | wc -l ` -gt 0 ]; then
echo hi
for file in test-images/*/*.png; do
convert "$file" -resize 64x128\! "${file%.*}.png"
convert "$file" -set colorspace Gray -separate -average "${file%.*}.png"
file "$file" #uncomment for testing
done
fi
if [ `ls training-images/*/*.jpg 2> /dev/null | wc -l ` -gt 0 ]; then
echo hi
for file in training-images/*/*.jpg; do
convert "$file" -resize 64x128\! "${file%.*}.png"
convert "$file" -set colorspace Gray -separate -average "${file%.*}.png"
file "$file" #uncomment for testing
rm "$file"
done
fi
if [ `ls training-images/*/*.png 2> /dev/null | wc -l ` -gt 0 ]; then
echo hi
for file in training-images/*/*.png; do
convert "$file" -resize 64x128\! "${file%.*}.png"
convert "$file" -set colorspace Gray -separate -average "${file%.*}.png"
file "$file" #uncomment for testing
done
fi2.jpg、png转minist格式数据集代码
convert-images-to-mnist-format.py
import os
from PIL import Image
from array import *
from random import shuffle
# Load from and save to
Names = [['./training-images','train'], ['./test-images','test']]
for name in Names:
data_image = array('B')
data_label = array('B')
FileList = []
for dirname in os.listdir(name[0])[1:]: # [1:] Excludes .DS_Store from Mac OS
path = os.path.join(name[0],dirname)
for filename in os.listdir(path):
if filename.endswith(".png"):
FileList.append(os.path.join(name[0],dirname,filename))
shuffle(FileList) # Usefull for further segmenting the validation set
for filename in FileList:
label = int(filename.split('/')[2])
Im = Image.open(filename)
pixel = Im.load()
width, height = Im.size
for x in range(0,width):
for y in range(0,height):
print(pixel[y,x])
#data_image.append(pixel[y,x])
data_image.append(Im.getpixel((x,y))) #改动的地方,能够完美运行不同尺寸的图像
data_label.append(label) # labels start (one unsigned byte each)
hexval = "{0:#0{1}x}".format(len(FileList),6) # number of files in HEX
# header for label array
header = array('B')
header.extend([0,0,8,1,0,0])
header.append(int('0x'+hexval[2:][:2],16))
header.append(int('0x'+hexval[2:][2:],16))
data_label = header + data_label
# additional header for images array
if max([width,height]) <= 256:
header.extend([0,0,0,width,0,0,0,height])
else:
raise ValueError('Image exceeds maximum size: 256x256 pixels');
header[3] = 3 # Changing MSB for image data (0x00000803)
data_image = header + data_image
output_file = open(name[1]+'-images-idx3-ubyte', 'wb')
data_image.tofile(output_file)
output_file.close()
output_file = open(name[1]+'-labels-idx1-ubyte', 'wb')
data_label.tofile(output_file)
output_file.close()
# gzip resulting files
for name in Names:
os.system('gzip '+name[1]+'-images-idx3-ubyte')
os.system('gzip '+name[1]+'-labels-idx1-ubyte')
4:运行方式先运行resize-script.sh、再运行convert-images-to-mnist-format.py
成功!!!
##################################################################################
法2:第一步:将所有数据图片处理成320x120大小 (当初我处理的是行人的数据,所以长宽这样设计)
#function
#遍历所有文件夹目录的所有文件夹,缩放图片到统一尺寸,并覆盖保存到当前所在的文件夹
#
#提取目录下所有图片,更改尺寸后保存到另一目录
from PIL import Image
import os.path
import glob
size_m = 120 #宽
size_n = 320 #高
def get_file_path(root_path,file_list,dir_list):
#获取该目录下所有的文件名称和目录名称
dir_or_files = os.listdir(root_path)
for dir_file in dir_or_files:
#获取目录或者文件的路径
dir_file_path = os.path.join(root_path,dir_file)
#判断该路径为文件还是目录路径
if os.path.isdir(dir_file_path): #如果是文件目录,继续递归深入处理,如果是文件路径,则不处理
dir_list.append(dir_file_path) #如果是文件目录,追加
#递归获取所有文件和目录的路径
get_file_path(dir_file_path,file_list,dir_list)
else:
file_list.append(dir_file_path) #如果是文件,追加文件路径
temp=Image.open(dir_file_path)
image_size = temp.resize((size_m, size_n),Image.ANTIALIAS)
image_size.save(dir_file_path)
if __name__ == "__main__":
#根目录路径
root_path = r"\\data\\"
#用来存放所有的文件路径
file_list = []
#用来存放所有的目录路径
dir_list = []
get_file_path(root_path,file_list,dir_list)
print(file_list)
print(dir_list)
第二步 运行下面的代码(仔细阅读下面的注释代码,或者按我给的进行输入)
2-1 python convert_to_mnist_format.py notMNIST_small 20 没记错的话,对notMNIST_small的所有类按照20%测试,80%为训练进行划分处理。
2-2 生成相应格式数据后,如果需要进行压缩,则执行 gzip convert_MNIST/*ubyte 即可(将四个数据压缩成.gz格式)
ps:notMNIST_small(原始数据类别文件夹)
最终得到转换过的数据
convert_to_mnist_format.py
#
# This python script converts a sample of the notMNIST dataset into
# the same file format used by the MNIST dataset. If you have a program
# that uses the MNIST files, you can run this script over notMNIST to
# produce a new set of data files that should be compatible with
# your program.
#
# Instructions:
#
# 1) if you already have a MNIST data/ directory, rename it and create
# a new one
#
# $ mv data data.original_mnist
# $ mkdir convert_MNIST
#
# 2) Download and unpack the notMNIST data. This can take a long time
# because the notMNIST data set consists of ~500,000 files
#
# $ curl -o notMNIST_small.tar.gz http://yaroslavvb.com/upload/notMNIST/notMNIST_small.tar.gz
# $ curl -o notMNIST_large.tar.gz http://yaroslavvb.com/upload/notMNIST/notMNIST_large.tar.gz
# $ tar xzf notMNIST_small.tar.gz
# $ tar xzf notMNIST_large.tar.gz
#
# 3) Run this script to convert the data to MNIST files, then compress them.
# These commands will produce files of the same size as MNIST
# notMNIST is larger than MNIST, and you can increase the sizes if you want.
#
# $ python convert_to_mnist_format.py notMNIST_small test 1000
# $ python convert_to_mnist_format.py notMNIST_large train 6000
# $ gzip convert_MNIST/*ubyte
#
# 4) After update, we cancel output path and replace with 'train', 'test' or test ratio number,
# it not only work on 10 labels but more,
# it depends on your subdir number under target folder, you can input or not input more command
#
# Now we define input variable like following:
# $ python convert_to_mnist_format.py target_folder test_train_or_ratio data_number
#
# target_folder: must give minimal folder path to convert data
# test_train_or_ratio: must define 'test' or 'train' about this data,
# if you want seperate total data to test and train automatically,
# you can input one integer for test ratio,
# e.q. if you input 2, it mean 2% data will become test data
# data_number: if you input 0 or nothing, it convert total images under each label folder,
# e.q.
# a. python convert_to_mnist_format.py notMNIST_small test 0
# b. python convert_to_mnist_format.py notMNIST_small test
# c. python convert_to_mnist_format.py notMNIST_small train 0
# d. python convert_to_mnist_format.py notMNIST_small train
#
import numpy
import imageio
import glob
import sys
import os
import random
height = 0
width = 0
dstPath = "convert_MNIST"
testLabelPath = dstPath+"/t10k-labels-idx1-ubyte"
testImagePath = dstPath+"/t10k-images-idx3-ubyte"
trainLabelPath = dstPath+"/train-labels-idx1-ubyte"
trainImagePath = dstPath+"/train-images-idx3-ubyte"
def get_subdir(folder):
listDir = None
for root, dirs, files in os.walk(folder):
if not dirs == []:
listDir = dirs
break
listDir.sort()
return listDir
def get_labels_and_files(folder, number=0):
# Make a list of lists of files for each label
filelists = []
subdir = get_subdir(folder)
for label in range(0, len(subdir)):
filelist = []
filelists.append(filelist)
dirname = os.path.join(folder, subdir[label])
for file in os.listdir(dirname):
if (file.endswith('.png') or file.endswith('.jpg')):
fullname = os.path.join(dirname, file)
if (os.path.getsize(fullname) > 0):
filelist.append(fullname)
else:
print('file ' + fullname + ' is empty')
# sort each list of files so they start off in the same order
# regardless of how the order the OS returns them in
filelist.sort()
# Take the specified number of items for each label and
# build them into an array of (label, filename) pairs
# Since we seeded the RNG, we should get the same sample each run
labelsAndFiles = []
for label in range(0, len(subdir)):
count = number if number > 0 else len(filelists[label])
filelist = random.sample(filelists[label], count)
for filename in filelist:
labelsAndFiles.append((label, filename))
return labelsAndFiles
def make_arrays(labelsAndFiles, ratio):
global height, width
images = []
labels = []
imShape = imageio.imread(labelsAndFiles[0][1]).shape
if len(imShape) > 2:
height, width, channels = imShape
else:
height, width = imShape
channels = 1
for i in range(0, len(labelsAndFiles)):
# display progress, since this can take a while
if (i % 100 == 0):
sys.stdout.write("\r%d%% complete" %
((i * 100) / len(labelsAndFiles)))
sys.stdout.flush()
filename = labelsAndFiles[i][1]
try:
image = imageio.imread(filename)
images.append(image)
labels.append(labelsAndFiles[i][0])
except:
# If this happens we won't have the requested number
print("\nCan't read image file " + filename)
if ratio == 'train':
ratio = 0
elif ratio == 'test':
ratio = 1
else:
ratio = float(ratio) / 100
count = len(images)
trainNum = int(count * (1 - ratio))
testNum = count - trainNum
if channels > 1:
trainImagedata = numpy.zeros(
(trainNum, height, width, channels), dtype=numpy.uint8)
testImagedata = numpy.zeros(
(testNum, height, width, channels), dtype=numpy.uint8)
else:
trainImagedata = numpy.zeros(
(trainNum, height, width), dtype=numpy.uint8)
testImagedata = numpy.zeros(
(testNum, height, width), dtype=numpy.uint8)
trainLabeldata = numpy.zeros(trainNum, dtype=numpy.uint8)
testLabeldata = numpy.zeros(testNum, dtype=numpy.uint8)
for i in range(trainNum):
trainImagedata[i] = images[i]
trainLabeldata[i] = labels[i]
for i in range(0, testNum):
testImagedata[i] = images[trainNum + i]
testLabeldata[i] = labels[trainNum + i]
print("\n")
return trainImagedata, trainLabeldata, testImagedata, testLabeldata
def write_labeldata(labeldata, outputfile):
header = numpy.array([0x0801, len(labeldata)], dtype='>i4')
with open(outputfile, "wb") as f:
f.write(header.tobytes())
f.write(labeldata.tobytes())
def write_imagedata(imagedata, outputfile):
global height, width
header = numpy.array([0x0803, len(imagedata), height, width], dtype='>i4')
with open(outputfile, "wb") as f:
f.write(header.tobytes())
f.write(imagedata.tobytes())
def main(argv):
global idxLabelPath, idxImagePath
# Uncomment the line below if you want to seed the random
# number generator in the same way I did to produce the
# specific data files in this repo.
# random.seed(int("notMNIST", 36))
if not os.path.exists(dstPath):
os.makedirs(dstPath)
if len(argv) is 3:
labelsAndFiles = get_labels_and_files(argv[1])
elif len(argv) is 4:
labelsAndFiles = get_labels_and_files(argv[1], int(argv[3]))
random.shuffle(labelsAndFiles)
trainImagedata, trainLabeldata, testImagedata, testLabeldata = make_arrays(
labelsAndFiles, argv[2])
if argv[2] == 'train':
write_labeldata(trainLabeldata, trainLabelPath)
write_imagedata(trainImagedata, trainImagePath)
elif argv[2] == 'test':
write_labeldata(testLabeldata, testLabelPath)
write_imagedata(testImagedata, testImagePath)
else:
write_labeldata(trainLabeldata, trainLabelPath)
write_imagedata(trainImagedata, trainImagePath)
write_labeldata(testLabeldata, testLabelPath)
write_imagedata(testImagedata, testImagePath)
if __name__ == '__main__':
main(sys.argv)
最终数据形式(gzip后)