空间金字塔思想在不同网络中的具体应用:SPP,ASPP和FPN结构理解和总结
图像空间金字塔思想在图像处理中被广泛应用,本文主要针对具体的 SPP ,ASPP和 FPN 空间金字塔进行简单的介绍和总结。
文章目录
- 1 综述
- 1.1 SPP结构(Spatial Pyramid Pooling)
- 1.2 ASPP结构(Atrous Spatial Pyramid Pooling)
- 1.3 FPN结构(Feature Pyramid Networks for Object Detection)
- 2 总结
1 综述
SPP论文链接:
https://arxiv.org/pdf/1406.4729.pdf
ASPP论文链接(此处已deeplab v3为例):
deeplab v3(2017年):https://arxiv.org/pdf/1706.05587v1.pdf
deeplab v3+(2018年):https://arxiv.org/pdf/1802.02611.pdf
FPN论文连接:
https://arxiv.org/pdf/1612.03144.pdf
1.1 SPP结构(Spatial Pyramid Pooling)
在何恺明2015年《Spatial Pyramid Pooling in Deep ConvolutionalNetworks for Visual Recognition》被提出,改论文主要改进两点:
解决CNN需要固定输入图像的尺寸,导致不必要的精度损失的问题;
因为带有全连接层的网络结构都需要固定输入图像的尺度,当然后期也有直接用conv层代替FC层的,比如SSD网络直接用conv层来计算边界框坐标和置信度的。
解决R-CNN对候选区域进行重复卷积计算,导致计算冗余的问题;
因为R-CNN网络中基于segment seletive输出的2000个候选框都要重新计算feature map较为耗时,因此提出了候选区域到全图的特征(feature map)之间的对应映射,这样图像只需计算一次前向传播即可。
在之后的 fast R-CNN 和 faster R-CNN 都采用这种映射关系,为ROI pooling层。
但在mask R-CNN中,用ROI Align替代了ROI pooling层,其认为两次量化的候选框与最开始的回归候选框有一定偏差,影响检测和分割准确度,ROI Align中不进行float量化,通过双线性内插计算四个坐标点,然后进行max pooling。
SPP结构如下:
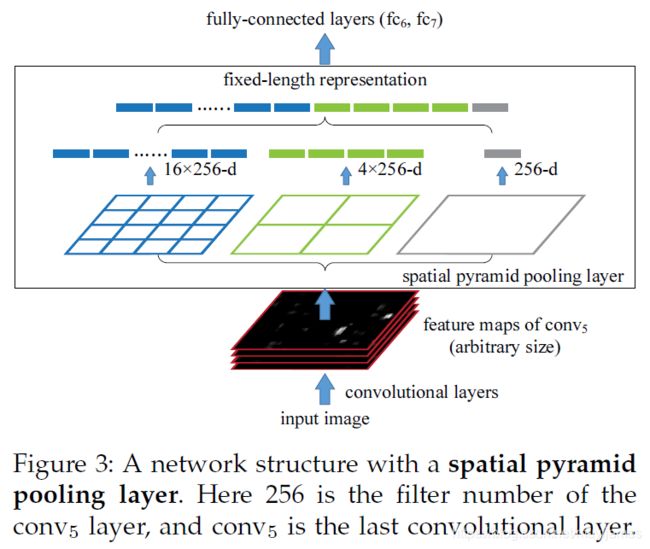
将256 channels 的 feature map 作为输入,在SPP layer被分成1x1,2x2,4x4三个pooling结构,对每个输入都作max pooling(论文使用的),这样无论输入图像大小如何,出来的特征固定是(16+4+1)x256维度。这样就实现了不管图像中候选区域尺寸如何,SPP层的输出永远是(16+4+1) x 256 特征向量。
1.2 ASPP结构(Atrous Spatial Pyramid Pooling)
可以认为是SPP在语义分割中的应用,结合了空洞卷积可在不丢失分辨率(不进行下采样)的情况下扩大卷积核的感受野。此处已deeplab v3网络为例,deeplab v3论文中的ASPP结构如下如所示。
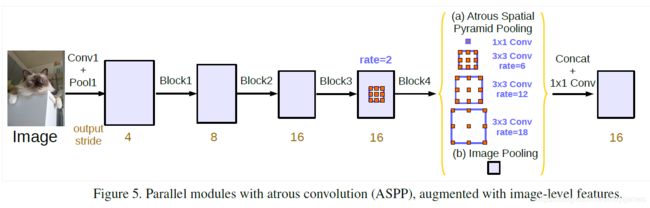
- 其中的1*1卷积,论文中的解释是当 rate = feature map size 时,dilation conv 就变成了 1 ×1 conv,所以这个 1 × 1 conv相当于rate很大的空洞卷积。还加入了全局池化,再上采样到原来的 feature map size,思想来源于PSPnet。为什么用 rate = [6, 12, 18] ?是论文实验得到的,因为这个搭配比例的 mIOU 最高。
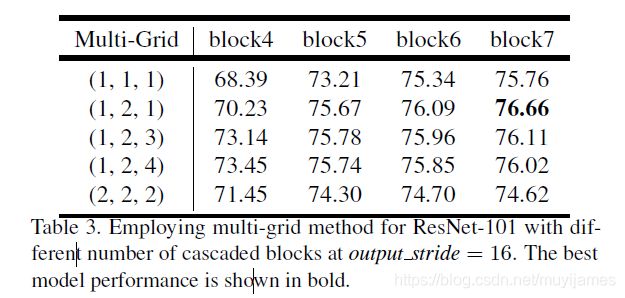
- 在 backbone 的每一个block里面又参考了HDC的思想,设置了 [1,2,1] 的rate,所以每个conv的rate = Rate * rate。论文给出的 Multi-grid 部分结果如下所示。
这里提一下deeplab v3+ 结构,是对V3的一个加强,主要有两个改进点:
- 对ASPP中的 upsample 进行了改进;
下图来自 deeplab v3+ 论文中,(a) 是deeplab v3的结构,( c) 是deeplab v3+的结构,v3+ 中将上采样变成了2次 4× 的 upsample,相比于v3中直接进行 8× 的 upsample,具有更丰富的语义信息,所以对物体边缘分割效果较好。

- deeplab v3+中另一个改进点,将 modify xception 作为 backbone;(这个改进点与ASPP无关)
如此下图所示,(1)加深了网络结构层数,且利用了 Atrous Separable Convolution 来减少权重参数;(2)利用 stride = 2 的 depthwise conv 来替代max pooling 进行下采样;(3)在每一个 depthwise conv 后都加了 BN 和 relu 层。作者在论文中做了各种尝试组合,有兴趣的可查看论文;
大家对 depthwise conv 有兴趣的可以阅读 Mobile Net 系列等轻量网络结构,论文可自行查找。

1.3 FPN结构(Feature Pyramid Networks for Object Detection)
FPN通常用在 object detection 网络中,通常低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。FPN 即是对两者进行了融合,同时利用低层特征高分辨率和高层特征的高语义信息,通过融合这些不同层的特征达到预测的效果。并且预测是在每个融合后的特征层上单独进行的,这和常规的特征融合方式不同。
FPN结构如下图:
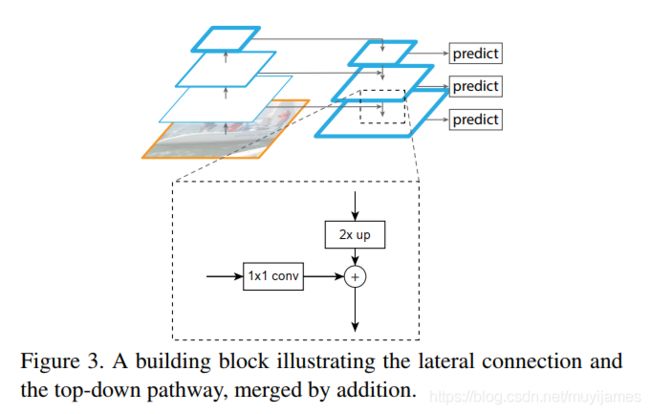
自底向上的路径:
具体而言,当 backbone 是 ResNet 时,我们使用每个阶段的最后一个residual block输出的特征激活输出。 对于conv2,conv3,conv4 和 conv5 输出,我们将这些最后residual block的输出表示为 {C2,C3,C4,C5},并且它们相对于输入图像具有 {4, 8, 16, 32} 的步长。
自顶向下的路径:
通过对在空间上更抽象但语义更强高层特征图进行上采样来幻化高分辨率的特征。在C5上附加一个1×1卷积层来生成低分辨率图P5,随后通过侧向连接从底向上的路径,使得高层特征得到增强。将低分辨率的特征图做2倍上采样,最终的特征映射集称为{P2,P3,P4,P5},分别对应于{C2,C3,C4,C5},具有相同的尺寸。通过按元素相加,将上采样映射与相应的自底而上映射合并。
最后,在每个合并的图上附加一个3×3卷积来生成最终的特征映射,这是为了减少上采样的混叠效应。
作者在将其应用到 RPN 和 fast / faster R-CNN 中,在论中有详细的实验数据,大家有兴趣可自行查阅。
在YOLO v3中也采用了类似 FPN 的结构,但里面用了concat 进行特征融合;
2 总结
空间金字塔思想在图像处理中具有很重要的作用,
传统图像处理中:
- 在SIFT 中利用高斯差分金字塔 (DOG) 保持尺度不变性;
- 在配准 / 匹配算法中利用空间金字塔进行粗匹配和细匹配达到效率优化;
CNN 网络中:
- 在含有FC层网络中利用 SPP 改进输入需要固定尺度的问题;
- 在语义分割中利用 ASPP 在不丢失信息时组合不同感受野的语义信息,提高分割精度;
- 在 object detection 网络中利用 FPN 改善小目标难检测的问题;
有错误之处请多多指教哈!!