SequoiaDB巨杉数据库的分区类型和分区方式
在SequoiaDB中有三种分区类型:
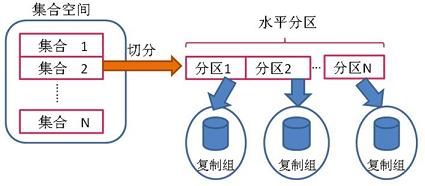
水平分区:
水平分区又称为数据库分区或横向分区。
在 SequoiaDB 集群环境中,用户可以通过将一个集合中的数据切分到多个复制组中,以达到并行计算的目的,此数据切分称为水平分区。水平分区是按一定的条件把全局关系的所有元组划分成若干不相交的子集,每个子集为关系的一个片段,称为分区;一个分区只能存在于一个复制组中,但一个复制组可以承载多个分区;分区在复制组之间可以通过水平切分操作进行移动。
垂直分区:
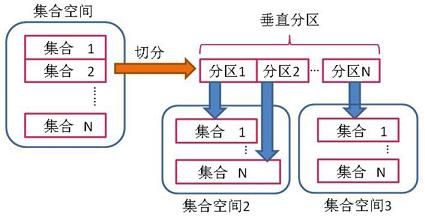
垂直分区又称为集合分区或纵向分区。
在 SequoiaDB集群环境中,用户也可以将一个集合全局关系的属性分成若干子集,并在这些子集上作投影运算,将这些子集映射到另外的集合上,从而实现集合关系的垂直切分;该集合称之为主集合,每个切分的子集称为分区,分区映射的集合称为子集合;一个分区只能映射到一个子集合中,但一个子集合可以承载多个分区;分区在子集合之间可以通过垂直切分操作进行重映射。
混合分区
在 SequoiaDB 集群环境中,可以将集合先通过垂直分区映射到多个子集合中,再通过水平分区将子集合切分到多个复制组中,从而实现混合分区。
分区方式
数据分区有两种方式:范围分区(Range)和散列分区(Hash)。
水平分区即可使用Hash 方式也可使用Range 方式进行数据分区;垂直分区只能使用Range 方式进行数据分区。Hash 及 Range这两种分区方式判定分区划分所依据的字段称为“分区键”。分区键基于集合定义,每个分区键可以包含一个或多个字段。
Range 方式下依据记录中分区键的范围选择所要插入的分区。Hash方式下根据记录中分区键生成的 hash 值选择所要插入的分区。
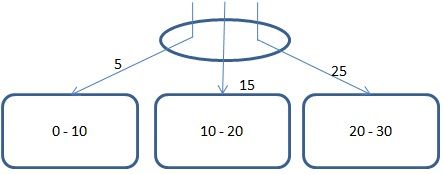
在所示图中,为一个 Range 方式分区,方形区域为三个分别位于不同数据组的数据节点,椭圆形为协调节点。每个数据节点各自定义了所包含数据的范围。例如对于节点1包含了大于等于0切小于10的数据。
当用户插入一条数据时,协调节点首先判定该数据的分区键应当坐落于哪个分区。如果分区键不存在则定义为 Undefined 类型(Undefined类型也可以与普通数据类型进行对比)。
当查询到该数据所在的分区后,协调节点会将请求直接下发给指定的分区。
垂直分区示例
1.创建主表(主表必须用range切分)
> db.createCS("maincs").createCL("maincl",{IsMainCL:true,ShardingKey:{a:1},ShardingType:"range"})
localhost:50000.maincs.maincl
Takes 0.8144s.2.创建子表1(子表既可用range,也可用hash,ShardingKey也不必一定要和主表的一致)
> db.createCS("year2015").createCL("month01",{ShardingKey:{a:1},ShardingType:"hash",Partition:1024})
localhost:50000.year2015.month01
Takes 0.899728s.3.创建子表2
> db.year2015.createCL("month02",{ShardingKey:{a:1},ShardingType:"hash",Partition:1024})
localhost:50000.year2015.month02
Takes 0.9760s.4.将子表1、子表2关联到主表中(将子表附到主表中去,每个子表都有一个范围)
> db.maincs.maincl.attachCL("year2015.month01",{LowBound:{a:0},UpBound:{a:100}})
Takes 0.8920s.
> db.maincs.maincl.attachCL("year2015.month02",{LowBound:{a:100},UpBound:{a:200}})
Takes 0.9837s.5.查看主子表情况
> db.snapshot(8)
{
"CataInfo": [
{
"ID": 1,
"SubCLName": "year2015.month01",
"LowBound": {
"a": 0
},
"UpBound": {
"a": 100
}
},
{
"ID": 2,
"SubCLName": "year2015.month02",
"LowBound": {
"a": 100
},
"UpBound": {
"a": 200
}
}
],
"EnsureShardingIndex": true,
"IsMainCL": true,
"Name": "maincs.maincl",
"ShardingKey": {
"a": 1
},
"ShardingType": "range",
"Version": 3,
"_id": {
"$oid": "56c180b419ca59d5c29afb20"
}
}
{
"CataInfo": [
{
"GroupID": 1003,
"GroupName": "datagroup",
"LowBound": {
"": 0
},
"UpBound": {
"": 1024
}
}
],
"EnsureShardingIndex": true,
"InternalV": 3,
"MainCLName": "maincs.maincl",
"Name": "year2015.month01",
"Partition": 1024,
"ShardingKey": {
"a": 1
},
"ShardingType": "hash",
"Version": 2,
"_id": {
"$oid": "56c180c219ca59d5c29afb25"
}
}
{
"CataInfo": [
{
"GroupID": 1003,
"GroupName": "datagroup",
"LowBound": {
"": 0
},
"UpBound": {
"": 1024
}
}
],
"EnsureShardingIndex": true,
"InternalV": 3,
"MainCLName": "maincs.maincl",
"Name": "year2015.month02",
"Partition": 1024,
"ShardingKey": {
"a": 1
},
"ShardingType": "hash",
"Version": 2,
"_id": {
"$oid": "56c180ce19ca59d5c29afb28"
}
}
Return 3 row(s).
Takes 0.10594s.6.插数据
> db.maincs.maincl.insert({a:1}) // 数据落到子表1中
Takes 0.2195s.
> db.maincs.maincl.insert({a:101}) // 数据落到子表2中
Takes 0.1872s.7.查看数据落表的情况
> db.year2015.month01.find()
{
"_id": {
"$oid": "564968bb5fc84bb828000000"
},
"a": 1
}
Return 1 row(s).
Takes 0.3209s.
> db.year2015.month02.find()
{
"_id": {
"$oid": "564968be5fc84bb828000001"
},
"a": 101
}
Return 1 row(s).
Takes 0.3407s.8.解除主子表之间的关联
> db.maincs.maincl.detachCL("year2015.month01")
Takes 0.10324s.
> db.maincs.maincl.detachCL("year2015.month02")
Takes 0.7857s.后续的分区键,分区集合等介绍可以参考巨杉数据库的文档中心。