Spark作为ETL工具与SequoiaDB的结合应用
一、前言
ETL一词较常用于数据仓库,但其对象并不仅限于数据仓库。ETL是指将数据从源系统中经过抽取(Extract)、转换(Transform)、加载(Load)到目标数据存储区的过程。常见的ETL工具有Oracle Data Integrator、Informatica PowerCenter、DataStage、Kettle、DataSprider等。
在大数据应用中,海量的数据及对潜在应用的支持是非常重要的方面,并体现出与传统应用开发的巨大不同。因此,在选择合适的ETL工具时,除了需要考虑数据处理的正确性、完整性、工具易用性、对不同数据格式的支持程度之外,还必须考虑数据处理的效率、处理能力的可扩展、容错性。
Spark是UC Berkeley AMP lab开源的类Hadoop MapReduce的通用的并行计算框架,是一个新兴的大数据处理引擎,主要特点是提供了一个集群的分布式内存抽象。与Hadoop相比,Spark将中间数据放在内存中,避免频繁写盘,因此效率更高,更适合于迭代计算;在操作类型、开发语言支持上更丰富;在分布式数据集计算时通过checkpoint来实现容错。而且,由于Spark的分布式特性,处理能力的扩展更容易,也更经济。因此,从整体上,Spark作为ETL工具能帮助企业实现技术和财务的双赢。
SequoiaDB是新一代NewSQL数据库,是文档型分布式数据的典型代表。SequoiaDB企业版通过深度集成最新的Spark内存计算框架,实现了批处理分析、流处理等贴近应用的功能。存储层和计算层两层分离的架构,技术互补,是硅谷大数据新架构的主流,将分布式计算与分布式存储的能力分别发挥到了极致。在Spark最新版本中,SparkSQL对标准SQL的支持也越来越完善,更加体现出Spark产品的成熟。因此,在SequoiaDB应用中,利用Spark进行数据加工分析是理想之选。
二、功能概述
作为ETL工具,必须具备多样数据源的支持,比如HDFS、HBase、Amazon S3、MongoDB等。在这一点上,Spark支持跟多种数据源的对接,常见的数据源包括HDFS、Cassandra、HBase、Hive、ALLUXIO(即Tachyon)、Amazon S3;Spark也能从全文检索工具Elasticsearch中读写数据。Spark作为ETL工具能满足工具功能通用性的要求。
以Spark为ETL处理的数据流图如图一所示:
图一 Spark为ETL数据流图
在以上数据流图中,可以将存储于HDFS、Cassandra等系统中的存量数据通过Spark提供的接口抽到Spark中,利用Spark的快速处理能力进行处理,比如数据去重、更新,最后将结构数据存储到巨杉数据库中。整个处理过程中,不需要将数据以数据文件的形式存盘,加快了处理速度。
对于已存储到巨杉数据库中的数据,也可以在Spark中处理,并将处理后的数据落到库中。
三、环境搭建
3.1 Spark环境搭建
Spark运行模式包括Standalone、Spark on YARN、Spark on Mesos。三种模式的主要区别在于使用的资源管理调度工具不一样。这里以Standalone模式为例进行说明。
在部署之前,将需要部署Spark的机器两两之间的信任关系配置好,并根据Spark版本对JDK版本的需求安装配置好JDK。然后就可以开始安装Spark。
首先,从Spark官网获取最新版本的Spark安装文件。下载完成后将其解压到目标文件夹。
| tar -zxvf spark-2.0.0-bin-hadoop2.6.tgz |
从解压出来的文件目录可以看到,跟1.6版本相比,2.0版本的目录结构有一些细微变化,lib目录被删除,增加了jars目录。
然后,修改配置文件。通常需要修改的配置文件包含spark-env.sh、slaves,但为了后续使用方便,还需要修改或增加hive-site.xml、spark-defaults.conf、log4j.properties。下面分别进行说明。
1. spark-env.sh
配置Spark环境变量,包括:
SPARK_MASTER_IP:Spark集群Master节点IP地址;
SPARK_MASTER_PORT:Master节点端口号,默认为7077;
SPARK_WORKER_INSTANCES:每节点启动的Worker进程数量;
SPARK_WORKER_CORES:本机上Worker可用核数;
SPARK_WORKER_MEMORY:Worker可分配给executor使用的总内存;
SPARK_WORKER_DIR:Worker工作目录;
SPARK_LOCAL_DIRS:节点shuffle数据存放目录;
SPARK_CLASSPATH:Spark默认classpath。
2.slaves
配置Spark集群中运行Worker的节点,值为主机名,每一行一个主机名。
3. hive-site.xml
主要用于元数据库的配置。Spark默认使用Derby作为数据库管理元数据,当我们需要配置其他数据库作为元数据库时,需要增加并修改此配置文件。一个例子如下所示:
|
|
4. spark-defaults.conf
Spark默认配置。该配置可以配置spark.master、spark.driver.memory、spark.executor.extraJavaOptions等。当我们需要通过JDBC使用SparkSQL时,需要首先启动Thriftserver,启动时需要指定MASTER_URL,这个MASTER_URL可以配置到spark-defaults.conf中的spark.master参数中,省去在命令行启动时都需要输入MASTER_URL的麻烦。
5. log4j.properties
配置Spark log日志。
最后,启动Spark集群。配置文件修改好后,就可以启动Spark。由于已经配置好Master及Worker的信息,可以通过如下命令启动Spark集群:
| sbin/start-all.sh |
3.2 配置Spark与SequoiaDB的连接
SequoiaDB开源了Spark连接器,可以在github网站上找到相应的代码(https://github.com/SequoiaDB/spark-sequoiadb),打包后得到连接器命名为spark-sequoiadb-2.0.0.jar。将连接器和SequoiaDB Java驱动包sequoiadb.jar一起,拷贝至jars目录,并在spark-env.sh中配置SPARK_CLASSPATH,将连接器及驱动包全路径配置到SPARK_CLASSPATH环境变量中,如
| SPARK_CLASSPATH=/opt/spark-2.0.0-bin-hadoop2.6/jars/spark-sequoiadb-2.0.0.jar:/opt/spark-2.0.0-bin-hadoop2.6/jars/sequoiadb.jar |
配置完成后,通过如下命令启动Thriftserver:
| sbin/start-thriftserver.sh |
启动成功后,通过jps命令可以看到Thriftserver相关的进程:
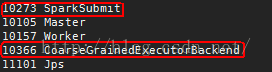
图二 Thriftserver相关进程
至此,Spark与SequoiaDB的环境已经搭建完成,可以开始用Spark处理数据了。
四、SequoiaDB数据处理
4.1 处理流程
SequoiaDB与Spark环境搭建完成之后,可以根据数据源的不同,采取不同的方式在Spark中创建针对不同数据源的映射,就可以将数据源与SequoiaDB通过Spark连接起来,完成ETL处理。
本节以SparkSQL对SequoiaDB中数据进行ETL为例,说明Spark与SequoiaDB的结合应用。源数据为其他时可以使用类似的处理逻辑。
在Spark中创建到SequoiaDB中集合的映射表语法为:
| create table tablename ( f1 string, f2 string, f3 int, f4 double, f5 string, f6 long ) using com.sequoiadb.spark OPTIONS ( host 'sdbserver1:11810,sdbserver2:11810,sdbserver3:11810', collectionspace 'foo', collection 'bar'); |
其中,host为SequoiaDB的访问地址,格式为hostname:svcname,可以包含多个地址。collectionspace及collection分别代表SequoiaDB中的集合空间及集合。
本例为利用每天增量数据对已有存量数据进行更新的场景,涉及的表为:账户信息表acct_info为结果表、账户信息中转表repo_acct_info为每天增量数据、acct_info_his为已有存量数据。由于SparkSQL不支持UPDATE及DELETE操作,因此,涉及到UPDATE及DELETE的场景可以通过将结果数据存于新表的方式来完成。UPDATE分为两步:
第一步:将中转表中最新数据插入结果表。通过这一步,保证第一次进来的数据和存在更新的数据进到结果表。执行语句为:
| insert into table dst.acct_info select * from src.repo_acct_info where tx_date = '2016-06-23' ;" |
第二步:将未做任何更新的数据数据插入结果表。执行语句为:
| insert into table dst.acct_info select distinct a.* from src.acct_info_his a left join src.repo_acct_info b on a.id = b.id and b.tx_date = '2016-06-23' where b.id is null ;" |
其中id为acct_info表的主键,通过id唯一标识一条记录。通过以上两个步骤,结果表acct_info即为经过去重后的更新数据。
而DELETE操作则只需要将不满足删除条件的数据插入新表即可。
4.2 性能结果
1. 系统配置
硬件环境:

软件环境:

2. UPDATE场景

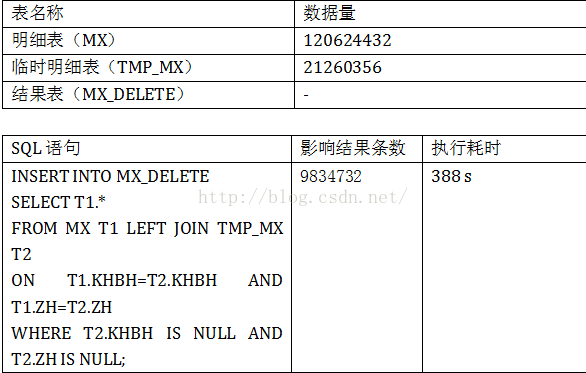
3. DELETE场景
五、结论
Spark能够方便地读取多样数据源,作为一种较为成熟的新框架,Spark不仅支持HDFS、Cassandra、HIVE、Amazon S3这类相对较新的数据源,对传统行业常见的如Oracle、DB2、Teradata,Spark也能很好地支持,且Spark支持SQL2003,应用Spark也能充分发挥传统企业在SQL处理上的强项。在大数据应用中,以Spark为ETL工具可以充分发挥分布式计算框架Spark的处理能力的性能优势。
作为全球获得Databricks认证的14家发行商之一,SequoiaDB企业版深度集成最新的Spark内存计算框架,存储层和计算层两层分离的架构、技术互补,是硅谷大数据新架构的主流,将分布式计算与分布式存储的能力分别发挥到了极致。如今,Spark技术已经被大量运用到实时流处理、分析等不同领域,后台数据加工也可以利用Spark技术得以实现。
SequoiaDB巨杉数据库2.6最新版下载
SequoiaDB巨杉数据库技术博客
SequoiaDB巨杉数据库社区