(三十三)论文阅读 | 目标检测之PP-YOLO
简介

本文介绍的是百度于 2020 2020 2020年提出的目标检测算法, P P {\rm PP} PP- Y O L O {\rm YOLO} YOLO,它主要是基于 Y O L O v 3 {\rm YOLOv3} YOLOv3实现。首先, P P {\rm PP} PP- Y O L O {\rm YOLO} YOLO改进了 Y O L O v 3 {\rm YOLOv3} YOLOv3中的骨干网络、网络颈、网络头等,然后添加诸多技巧完成对改进网络的优化。实验结果为在 C O C O {\rm COCO} COCO数据集上的 m A P {\rm mAP} mAP为 45.2 % 45.2\% 45.2%、 F P S {\rm FPS} FPS为 72.9 72.9 72.9,好于当前热门的 E f f i c i e n t D e t {\rm EfficientDet} EfficientDet和 Y O L O v 4 {\rm YOLOv4} YOLOv4等模型。论文原文 源码
0. Abstract
目标检测在计算机视觉任务中扮演了重要角色。通常,由于计算机硬件的限制,需要牺牲模型精度来保证其推理速度。因此在设计网络时应充分考虑精度与速度之间的平衡。而 P P {\rm PP} PP- Y O L O {\rm YOLO} YOLO的主要考虑点是在一定程度上平衡模型的精度和速度,而非设计一个新颖的检测模型。 P P {\rm PP} PP- Y O L O {\rm YOLO} YOLO基于 Y O L O v 3 {\rm YOLOv3} YOLOv3实现,通过添加大量技巧来提高模型的精度,同时也保证了模型的推理速度。
论文贡献:(一)提出对 Y O L O v 3 {\rm YOLOv3} YOLOv3的改进, P P {\rm PP} PP- Y O L O {\rm YOLO} YOLO;(二) P P {\rm PP} PP- Y O L O {\rm YOLO} YOLO兼顾了模型的精度和速度;(三) P P {\rm PP} PP- Y O L O {\rm YOLO} YOLO超越了 Y O L O v 4 {\rm YOLOv4} YOLOv4和 E f f i c i e n t D e t {\rm EfficientDet} EfficientDet。
1. Introduction
Y O L O {\rm YOLO} YOLO系是目标检测检测算法中的一个重要系列,它们在精度和速度间作了有效的平衡。从 Y O L O v 1 {\rm YOLOv1} YOLOv1到 Y O L O v 3 {\rm YOLOv3} YOLOv3,模型均发生了很大的改变。而 Y O L O v 4 {\rm YOLOv4} YOLOv4则是在 Y O L O v 3 {\rm YOLOv3} YOLOv3的基础上通过添加大量的技巧来显著提高模型的性能。论文提出的 P P {\rm PP} PP- Y O L O {\rm YOLO} YOLO也是基于以上思路,在不增加模型推理时间的基础上通过添加大量技巧来提高模型的整体性能。
与 Y O L O v 4 {\rm YOLOv4} YOLOv4不同, P P {\rm PP} PP- Y O L O {\rm YOLO} YOLO没有试图设计新颖的骨干网络或数据增强方法,亦或是使用 N A S {\rm NAS} NAS得到超参数。在骨干网络部分, P P {\rm PP} PP- Y O L O {\rm YOLO} YOLO使用 R e s N e t {\rm ResNet} ResNet;数据增强使用 M i x U p {\rm MixUp} MixUp。上述选择的原因有两点: R e s N e t {\rm ResNet} ResNet系列优化力度很大,能够很好地满足实际部署等需求;骨干网络的替换和数据增强方法是相对独立的部分,不会对后续提到的技巧产生影响。同时, N A S {\rm NAS} NAS通常会消耗更多的计算资源,其不具有通用性。所以, P P {\rm PP} PP- Y O L O {\rm YOLO} YOLO的超参数设置同 Y O L O v 3 {\rm YOLOv3} YOLOv3。
论文的设计初衷是使用大量技巧来提高模型的性能,同时不会降低其推理速度。通常,技巧不能直接应用于 Y O L O v 3 {\rm YOLOv3} YOLOv3而需要一些小改动。论文并没有设计一个新颖的检测器,而是以 P P {\rm PP} PP- Y O L O {\rm YOLO} YOLO的例子来说明如何一步步构建一个高效的目标检测器。
2. Related Work
当前, A n c h o r {\rm Anchor} Anchor- B a s e d {\rm Based} Based仍是主流的目标检测算法。其最早可追溯到 R C N N {\rm RCNN} RCNN系列,它的核心思想是引入锚框,可以看作是预定义的先验框,以此为边界框回归提供先验知识。其中又可以分为一阶段检测算法和两阶段检测算法两个分支:一阶段检测算法中, Y O L O {\rm YOLO} YOLO系列、 R e t i n a N e t {\rm RetinaNet} RetinaNet、 R e f i n e D e t {\rm RefineDet} RefineDet、 E f f i c i e n t D e t {\rm EfficientDet} EfficientDet等较为经典的模型;两阶段检测算法中, R C N N {\rm RCNN} RCNN系列、 R e i d e n t N e t {\rm ReidentNet} ReidentNet等较为经典的模型。除此之外, A n c h o r {\rm Anchor} Anchor- F r e e {\rm Free} Free方法正受到广泛的关注,出现大量如 D e n s e B o x {\rm DenseBox} DenseBox、 U n i t B o x {\rm UnitBox} UnitBox、 F S A F {\rm FSAF} FSAF、 F C O S {\rm FCOS} FCOS、 F o v e a B o x {\rm FoveaBox} FoveaBox、 S A P D {\rm SAPD} SAPD、 C o r n e r N e t {\rm CornerNet} CornerNet、 C e n t e r N e t {\rm CenterNet} CenterNet、 E x t r e m e N e t {\rm ExtremeNet} ExtremeNet、 R e p P o i n t {\rm RepPoint} RepPoint等经典方法。这类方法消除了手工设计的限制,在多尺度目标检测下展现出了巨大的潜力
3. Method
3.1 Architecture
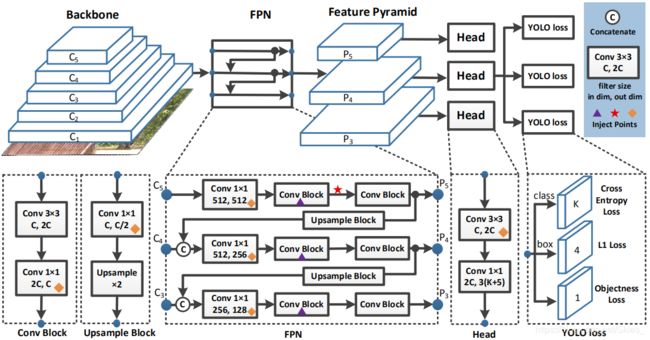
Backbone 在原始的 Y O L O v 3 {\rm YOLOv3} YOLOv3中,特征提取部分使用的是 D a r k N e t 53 {\rm DarkNet53} DarkNet53。论文使用残差网络提取特征,同时为了保证模型的精度而引入 D C N {\rm DCN} DCN。最后,使用 R e s N e t 50 {\rm ResNet50} ResNet50- v d {\rm vd} vd- d c n {\rm dcn} dcn作为骨干网络。
Detection Neck 论文使用 F P N {\rm FPN} FPN作为网络颈。
Detection Head 论文沿用 Y O L O v 3 {\rm YOLOv3} YOLOv3的检测头,每一个分支的输出通道数是 3 ( K + 5 ) 3(K+5) 3(K+5)。对于分类和定位,分别使用交叉熵损失函数和 L 1 {\rm L1} L1损失函数。综上, P P {\rm PP} PP- Y O L O {\rm YOLO} YOLO的基本结构如下:
3.2 Selection of Tricks
上一部分介绍了 P P {\rm PP} PP- Y O L O {\rm YOLO} YOLO的基本结构,这部分将介绍其中使用的基本技巧。
Large Batch Size 增大批次可以提高训练稳定性,从而能够获得更好的结果。论文使用的批次大小为 192 {\rm 192} 192,同时相应地调整训练策略以及学习率。
EMA 在训练模型时,保持训练参数平均移动往往有益于训练更优的模型, 使用平均参数评估有时会产生比最终训练值更好的结果。 指数平均移动是深度学习中常用到的优化方法,由于在训练深度学习模型时,模型权重在最后几步可能会在最优点处徘徊。 E M A {\rm EMA} EMA的思路是取最后几步的平均值作为最后的结果,从而增加模型的鲁棒性。即: W E M A = λ W E M A + ( 1 − λ ) W (1) W_{EMA}=\lambda W_{EMA}+(1-\lambda)W\tag{1} WEMA=λWEMA+(1−λ)W(1)
其中, λ = 0.99998 \lambda=0.99998 λ=0.99998。
DropBlock D r o p B l o c k {\rm DropBlock} DropBlock是在网络模型上随机丢弃的一种正则化方法,例如将特征图上的连续区域丢弃。不同于以往, P P {\rm PP} PP- Y O L O {\rm YOLO} YOLO仅在 F P N {\rm FPN} FPN使用 D r o p B l o c k {\rm DropBlock} DropBlock。
IoU Loss 与 Y O L O v 4 {\rm YOLOv4} YOLOv4中使用 I o U {\rm IoU} IoU损失替换 L 1 {\rm L1} L1损失不同的是, P P {\rm PP} PP- Y O L O {\rm YOLO} YOLO通过额外添加一个分支引入 I o U {\rm IoU} IoU损失。
IoU Aware 在 Y O L O v 3 {\rm YOLOv3} YOLOv3中,将分类概率和目标分数的乘积作为最后的分类置信度,而没有考虑定位精度。为了处理这个问题,论文引入一个 I o U {\rm IoU} IoU预测分支。在训练过程中,使用感知 I o U {\rm IoU} IoU损失来训练这个分支。在推理阶段,最后的分类置信度由分类概率、目标分数和 I o U {\rm IoU} IoU值乘积得到。
Grid Sensitive G r i d S e n s i t i v e {\rm Grid\ Sensitive} Grid Sensitive是 Y O L O v 4 {\rm YOLOv4} YOLOv4中采用的一种优化方法。在原始的 Y O L O v 3 {\rm YOLOv3} YOLOv3中,边界框中心坐标通过以下式子得到: x = s ⋅ ( g x + σ ( p x ) ) y = s ⋅ ( g y + σ ( p y ) ) (2) x=s·(g_x+\sigma(p_x))\ \ \ \ y=s·(g_y+\sigma(p_y))\tag{2} x=s⋅(gx+σ(px)) y=s⋅(gy+σ(py))(2)
其中, σ \sigma σ是 S i g m o i d {\rm Sigmoid} Sigmoid函数、 g ∗ g_* g∗是坐标值、 s s s是缩放因子。显然, x x x或 y y y的值不可能为 s ⋅ g x s·g_x s⋅gx或 s ⋅ ( g x + 1 ) s·(g_x+1) s⋅(gx+1),这样边界框的中心不可能到达网格的边界。论文对此做了如下改动: x = s ⋅ ( g x + σ ( p x ) − ( α − 1 ) / 2 ) (3) x=s·(g_x+\sigma(p_x)-(\alpha-1)/2)\tag{3} x=s⋅(gx+σ(px)−(α−1)/2)(3)
y = s ⋅ ( g y + σ ( p y ) − ( α − 1 ) / 2 ) (4) y=s·(g_y+\sigma(p_y)-(\alpha-1)/2)\tag{4} y=s⋅(gy+σ(py)−(α−1)/2)(4)
其中, α = 1.05 \alpha=1.05 α=1.05。
Matrix NMS M a t r i x N M S {\rm Matrix\ NMS} Matrix NMS是在 S o f t N M S {\rm Soft\ NMS} Soft NMS的基础上改进得到的,解决了 S o f t N M S {\rm Soft\ NMS} Soft NMS无法并行实现的问题。
CoordConv C o o r d C o n v {\rm CoordConv} CoordConv的提出是为了解决经典卷积神经网络无法感知坐标信息的问题。 C o o r d C o n v {\rm CoordConv} CoordConv在普通卷积的基础上添加两个通道分别表示横向和纵向的位置,用于给卷积操作提供自身位置信息。 C o o r d C o n v {\rm CoordConv} CoordConv使得网络可以具备完全或部分平移不变性。
SPP S P P {\rm SPP} SPP最早来自于 S P P N e t {\rm SPPNet} SPPNet,其提出的目的是解决卷积神经网络的输入需要固定尺寸的问题。在 P P {\rm PP} PP- Y O L O {\rm YOLO} YOLO中引入 S P P {\rm SPP} SPP以增大网络感受也,且仅引入少量额外的参数。
Better Pretrain Model 使用预训练的 R e s N e t 50 {\rm ResNet50} ResNet50- v d {\rm vd} vd模型。
4. Experiment


5. Conclusion
本文介绍的 P P {\rm PP} PP- Y O L O {\rm YOLO} YOLO是针对 Y O L O v 3 {\rm YOLOv3} YOLOv3的又一改进,效果优于 Y O L O v 4 {\rm YOLOv4} YOLOv4,模型基于 P a d d l e P a d d l e {\rm PaddlePaddle} PaddlePaddle实现。与 Y O L O v 4 {\rm YOLOv4} YOLOv4类似, P P {\rm PP} PP- Y O L O {\rm YOLO} YOLO通过引入诸多技巧逐步提高模型性能。但作者也提到,不能一味地引入技巧,而必须要平衡模型的精度与速度,以及保证训练模型时的稳定性。
参考
- Long X, Deng K, Wang G, et al. PP-YOLO: An Effective and Efficient Implementation of Object Detector[J]. arXiv preprint arXiv:2007.12099, 2020.