【论文阅读笔记】CenterNet:Objects as Points
全文概括
CenterNet是一个anchor-free的检测器。其将每一个对象用一个中心点(keypoint)表示,其余的属性,比如边框大小之类的,都由该中心点所在的 keypoint feature 所回归出来。
CenterNet是通过heatmap提取峰值得到的边框位置信息(取峰值的操作可以通过stride=1的 3 ∗ 3 3*3 3∗3最大池化层),不需要经过NMS操作,这能省去相当一部分的运行时间。
CenterNet输出分辨率的下采样因子stride为4,这比Mask-RCNN和SSD的16要小得多。
文中使用了三种骨干网络,得到了适用于不同需求、不同耗时的网络结果。在三种级别的网络中,CenterNet都达到了state-of-the-art的结果。
网络结构
CenterNet使用了三种骨干网络:
- Resnet-18 with up-convolutional layers。其检测结果为28.1% coco and 142 FPS;
- DLA-34。其检测结果为37.4% COCOAP and 52 FPS;
- Hourglass-104。其检测结果为45.1% COCOAP and 1.4 FPS;
这三种网络都是编码解码(encoder-decoder)的网络结构。结构定义如下图所示。

在骨干网络后加检测头,可得最后的检测结果。结果头的通道数如下图所示,方括号中的为最后一层特征的通道数。比如在COCO数据集的目标检测任务中,输出的检测头有三个:类别的keypoint heatmap,最后64分辨率到初始512分辨率映射的偏置,以及检测框的长宽hw。
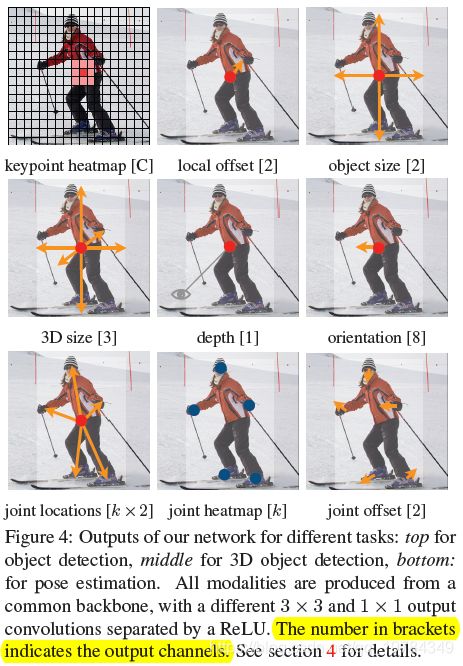
每一个输出的检测头都经过三个操作:(1)stride为1,padding为1的 3 ∗ 3 3*3 3∗3卷积;(2)ReLU;(3) 1 ∗ 1 1*1 1∗1卷积,得到想要的通道数;
网络相关
Label
网络输入维度为 I ∈ R W ∗ H ∗ 3 I \in R^{W*H*3} I∈RW∗H∗3,输出维度为 Y ^ ∈ [ 0 , 1 ] W R H R ∗ C \hat {Y} \in [0,1]^{\frac WR \frac HR * C} Y^∈[0,1]RWRH∗C。其中,R为步幅stride,文中为4。对于每一个类别,输出一个heatmap。如果预测 Y ^ x , y , c = 1 \hat{Y}_{x,y,c}=1 Y^x,y,c=1,则对应一个检测到的keypoint;如果预测 Y ^ x , y , c = 0 \hat{Y}_{x,y,c}=0 Y^x,y,c=0,则表示其是一个背景。如果在原图中的keypoint 位置为 p p p,则在低分辨率需要学习到的位置则为 p ^ = ⌊ p R ⌋ \hat{p}=\lfloor \frac p R \rfloor p^=⌊Rp⌋。
CenterNet和CornerNet一样,对ground truth的keypoint map Y ^ = [ 0 , 1 ] W R ∗ H R ∗ C \hat{Y} = [0,1]^{\frac WR *\frac HR * C} Y^=[0,1]RW∗RH∗C做高斯核处理,得到heatmap Y x y c = exp ( − ( x − p x ^ ) 2 + ( y − p y ^ ) 2 2 σ p 2 ) Y_{xyc}=\exp(-\frac {(x-\hat{p_x})^2+(y-\hat{p_y})^2}{2\sigma ^2_p}) Yxyc=exp(−2σp2(x−px^)2+(y−py^)2)。其中 σ p \sigma_p σp是 和目标边框大小(即w和h)相关的标准差。如果一个类别中有两个对象,其高斯核会有一个重叠,则在重叠位置上取较大值。
Loss
对于类别 heatmap 的损失函数,使用像素级逻辑回归的focal loss: L k = 1 N ∑ x y c { ( 1 − Y x y c ^ ) α log ( Y x y c ^ ) i f Y x y c = 1 ( 1 − Y x y c ^ ) β ( Y ^ x y c ) α log ( 1 − Y ^ x y c ) o t h e r w i s e L_k=\frac 1N\sum_{xyc}\begin{cases} (1-\hat{Y_xyc})^\alpha \log(\hat{Y_xyc}) & &if \ \ Y_{xyc}=1 \\ (1-\hat{Y_{xyc}})^\beta(\hat{Y}_{xyc})^\alpha \log(1-\hat{Y}_{xyc}) & &otherwise\end{cases} Lk=N1xyc∑{(1−Yxyc^)αlog(Yxyc^)(1−Yxyc^)β(Y^xyc)αlog(1−Y^xyc)if Yxyc=1otherwise 其中,N为输入图片I的keypoint个数, α \alpha α和 β \beta β是focal loss的超参数,文中使用默认的 2 2 2和 4 4 4。
对于网络结构带来的stride所导致的预测heatmap与原图的分辨率不对齐问题,对于每个中心点,都预测两个偏差校正的值。这个 offset 使用 L1 loss: L o f f = 1 N ∑ p = ∣ O p ^ ^ − ( p R − p ^ ) ∣ L_{off}=\frac 1N\sum_p=| \hat{O_{\hat{p}}}-(\frac pR-\hat{p}) | Loff=N1p∑=∣Op^^−(Rp−p^)∣ 这个损失函数只作用于那些keypoint p ^ \hat{p} p^,对于其他位置则忽略。偏置对于所有同一个中心点的所有类别都是一样的。
对于网络边框的尺度长和宽,使用L1损失函数: L s i z e = 1 N ∑ k = 1 N ∣ S p k ^ − S k ∣ L_{size}=\frac 1N\sum^N_{k=1}|\hat{S_{pk}}-S_k| Lsize=N1k=1∑N∣Spk^−Sk∣ 其中,object size S k = ( x 2 k − x 1 k , y 2 k − y 1 k ) S_k=(x_2^k-x_1^k,y_2^k-y_1^k) Sk=(x2k−x1k,y2k−y1k), x , y x,y x,y是bounding box的两个顶点。
和其他目标检测的损失函数一样,每个部件的损失函数都有其对应的权重参数: L d e t = L k + λ s i z e L s i z e + λ o f f L o f f L_{det}=L_k+\lambda_{size}L_{size}+\lambda_{off}L_{off} Ldet=Lk+λsizeLsize+λoffLoff 其中, λ s i z e = 0.1 \lambda_{size}=0.1 λsize=0.1, λ o f f = 1 \lambda_{off}=1 λoff=1。
网络输出
在使用网络进行推测的时候,我们每个类别分别从heatmap进行峰值的提取。峰值即意味着其在当前channel要大于或等于其周围八个数值,而且最后只保留top-100的峰值(代码在这个top-100后再进行了0.3为阈值的判断)。提取峰值的过程可以借用stride=1的 3 ∗ 3 3*3 3∗3最大池化层完成。
def _nms(heat, kernel=3):
pad = (kernel-1) // 2
hmax = max_pool2d(heat, (kernel, kernel), stride=1, padding=pad)
keep = (hmax == heat).float()
return keep * heat
从网络学出的point转换成我们需要的Bounding box,可以通过转换bounding box的左上角和右下角得到边框的位置。转换公式如下,其中加上 " ^ \hat{} ^ " 符号的为学习出来的结果:
{ x i 1 = x i 1 ^ + o f f s e t x ^ − w i ^ 2 y i 1 = y i 1 ^ + o f f s e t y ^ − h i ^ 2 x i 2 = x i 2 ^ + o f f s e t x ^ − w i ^ 2 y i 2 = y i 2 ^ + o f f s e t y ^ − h i ^ 2 \begin{cases} x_{i1} &= \hat{x_{i1}} &+ \hat{offset_x} &- \frac {\hat{w_i}}2 \\ y_{i1} &= \hat{y_{i1}} &+ \hat{offset_y} &- \frac {\hat{h_i}}2 \\ x_{i2} &= \hat{x_{i2}} &+ \hat{offset_x} &- \frac {\hat{w_i}}2 \\ y_{i2} &= \hat{y_{i2}} &+ \hat{offset_y} &- \frac {\hat{h_i}}2 \\ \end{cases} ⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧xi1yi1xi2yi2=xi1^=yi1^=xi2^=yi2^+offsetx^+offsety^+offsetx^+offsety^−2wi^−2hi^−2wi^−2hi^
实验结果

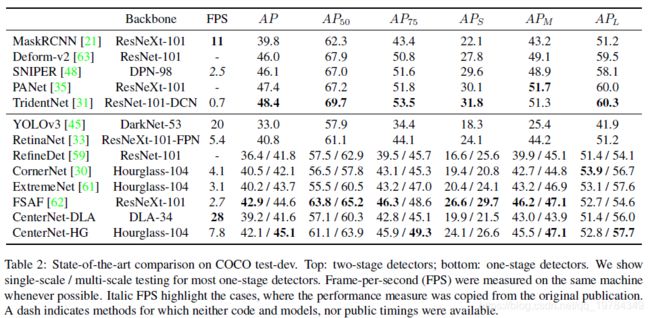
可以看到,CenterNet在速度和精度方面,都可以达到一个较好的结果。
在使用不同的骨干网络,CenterNet表现如下:

CenterNet的速度和精度比CornerNet和ExtremeNet要好。速度的优势来自于更少的output heads和简单的边框解码机制。正确率的优势暗示着中心点比角落和极值点要更容易预测。使用相同的骨干网络ResNet101,CenterNet的表现要优于RetinaNet。CenterNet值在上采样层时采用deformable Convolutions,这个算子是在RetinaNet上所没有使用的。在相同精度的情况下,CenterNet的速度是RetinaNet的两倍。
不同网络的精度对比如下。以DLA为骨干网络,是作者所试验出的最好的speed-accuracy折中。