深度学习笔记(2)——卷积神经网络(Convolutional Neural Network)
卷积神经网络(Convolutional Neural Network, CNN)是深度学习转折的标志性成果,在深度学习的早期,以Hinton等为代表的学者们研究主要集中在RBM(限制波尔兹曼机),AE(自编码器)等传统的全连接神经网络框架上,这个时期虽然出现了很多无监督、优化函数改进之类的研究,使得传统的神经网络层数有所增加,但是终究没有脱离全连接神经网络框架的约束,以至于最终网络可训练的参数量还是遇到了瓶颈。但是2012年的ImageNet竞赛上,Hinton的学生团队用CNN网络一下把图像识别的准确度提高近17个百分点,深度学习自此开始爆发,直到今天成为一个没听过深度学习都不好意说自己是工科大学生的时代。CNN作为新时代深度学习的第一炮,是传统神经网络在视觉领域应用的必然产物。相比于传统的神经网络,CNN的参数量指数级减少但是表达能力并没有下降,因此在相同的参数量情况下,CNN能够满足更大数据量的应用,再加上GPU等高性能计算硬件的发展,造就了深度学习今天的成就。而CNN的原理主要取决于它的三个特性——局部连接、参数共享、池化采样。
卷积
首先我们要学习CNN前馈计算的核心数学操作之一——卷积。卷积是高等数学里面非常基础的一个运算操作,通常在数字信号处理等课程里面都会有所介绍。如果读者不喜欢本文对卷积的介绍,也可以自行百度。
卷积对于连续信号和离散信号拥有不同的计算公式,由于在深度学习领域,所有的数据都是离散信号形式,所以本文只介绍离散信号的卷积公式,对于一维离散信号 f(n) (长度为N)和一维离散卷积核信号 g(n) ,卷积结果 s(n) (长度为M)表示为:
卷积公式中如果有不存在的信号,则用0代替,这是常见zero padding模式。
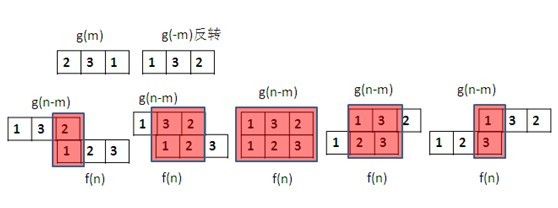
例:假设 f(n)=[1,2,3] ; g(n)=[2,3,1] ;则:
所以最后的卷积结果为:
上述计算用图像表达如下,数学上 g(−m) 就是 g(m) 的反转, g(n−m) 就是 g(m) 反转之后再平移n个单位:
当然我们CNN主要针对是图像信号,而图像是二维的离散信号,因此我们可以类似的扩展到二维卷积公式,对于图像A和卷积核B,有:
图示为:
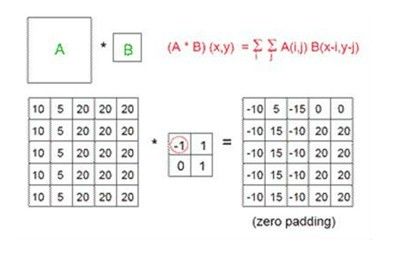
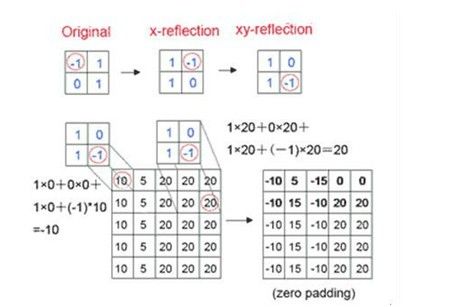
卷积通常会在边缘处带来一个尺寸变化的过程,根据尺寸是否变化一般深度学习里面分为same和valid两种padding方式,same模式就是我们上面这种通过对原始数据扩展0的zero padding保证卷积结果尺寸和原始数据尺寸一样(一维信号3*3的那个例子最后会取中间的3个结果保持尺寸不变)。而valid的就是不扩充0,从数据能够有效计算开始,这样操作会造成结果的尺寸变小(一维信号3*3的那个例子最后只有 s(2) 这个计算是有效计算,所以最后结果的尺寸就是1)。
另外在深度学习的卷积操作之中还有一个参数叫做步长stride,通常我们使用的步长都是默认1,但是有些特殊的情况我们可以选择步长为2,也就是两格卷积一次,这样做的操作就是最后的卷积结果尺寸变为原来的一半,这个操作是CNN中比较流行的微步长卷积,可以取代后面我们要讲的池化采样操作。
CNN的三个特性
在了解CNN网络的整体结构之前,我们先单独来看CNN的三个特性,读者请确认已经基本理解了神经网络,如若还不熟悉,请看上一篇笔记博客。
局部连接
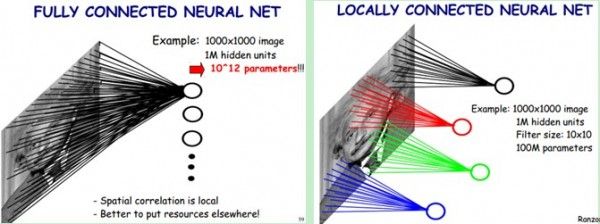
让我们回想一下,在传统的神经网络的图像分类问题中,如果我们要直接用原图像作为网络输入进行训练,那么每一个像素都要为之分配一个神经元,也就是说一个 1000×1000 像素的单通道灰度图像在输入层我们就需要 106 ,如果下一层有100个神经元输出,那么参数量又要扩大一百倍,这样的网络如果最终要达到能够应用的程度,将会有巨大的参数量。
根据视觉神经相关研究的表明,我们的视觉神经元是有层次感,低层的视觉神经元更加关注具体的局部细节(例如边缘,纹理等),而高层视觉神经元更加关注高层特征等(例如轮廓、空间关系等)。而低层神经元的实现就是通过局部连接的思想实现,因为低层的视觉特征只需要关注很小的一个区域(论文里通常会用patch这个单词,或者更加专业的术语我们会称之为感受野)图像,而不需要关注整幅图像,所以我们只需要进行局部连接就可以。例如我们只关心一个 10×10 的区域,只需要100个参数就可以得到下一层神经元的输出,单独拿出来看,这就是一个 10×10 卷积核对图像中的这个patch做了一次卷积操作。我们可以看到,输出的这个神经元的值只和这个patch有关,并没有用到整幅图像的值,这就是局部连接。当然仅仅只是局部连接并不能体现CNN的精妙之处,接下来会继续欣赏权值共享和池化采样。
权值共享
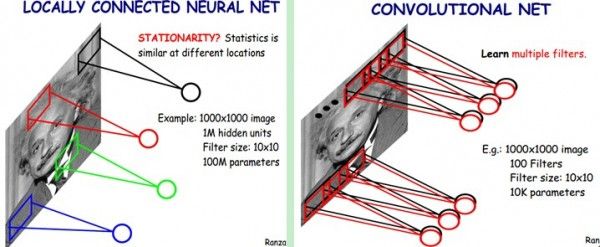
上一节已经介绍了局部连接,虽然提到了局部连接可以减少参数量,但是似乎参数量还是蛮多的啊,这一节的权值共享将会再次把参数量减少到一个特别可观的程度。
我们看上图左边的部分,这里有四个颜色方框,按照局部连接的思想,假如我们队四个patch进行卷积运算(图中四个颜色的框),理论上我们需要 4×10×10 个参数量,如果对一幅图进行一次完整的循环卷积,那么参数量也是巨大的。所以我们可以把这个卷积核的参数固定,用一个固定的卷积核去对整幅图像进行卷积,这样参数量就是一个卷积核的参数量。权值共享不仅仅是直接的参数量大大缩小,它也是拥有充分论证的物理意义的,在图像处理领域一次卷积操作就是一次特征提取,比如读者可以去查一下边缘特征提取sobel,prewitt算法。
每个卷积核卷积一下图片得到的还是一个图片,根据padding模式的设置决定特征图的size和原图是否一致,我们可以在一层CNN网络中设置多个卷积核。为了更好的解释,这里选择tensorlayer框架代码的例子,而不选用更加简单keras的例子:
network = tl.layers.Conv2dLayer(network,act = tf.nn.relu, shape = [5, 5, 1, 32], strides=[1, 1, 1, 1], padding=’SAME’, name =’cnn_layer1’)# 32 features for each 5x5 patch
network = tl.layers.Conv2dLayer(network,
act = tf.nn.relu, shape = [5, 5, 32, 64], strides=[1, 1, 1, 1], padding=’SAME’, name =’cnn_layer2’) # 64 features for each 5x5 patch 这里有两个卷积层,第一层是输入单通道([5,5,1,32]的第三个数字,keras框架会自动识别这个数值,不需要设置)的灰度图,设置了32个卷积核,所以最后单通道的灰度图会生成32张特征图,这一步很好理解。然后我们看第二层卷积层,输入时32张特征图,输出是64张更加高层的特征图,总共有64个卷积核,为什么是输出是64张特征图而不是 32×64 张特征图呢,这是因为用一个卷积核去卷了这32张图片,然后把32个输出最后叠加作为一张图来输出(当然最后还是要经过一下非线性的激活函数),所以这就是CNN的第二个特性权值共享,一来可以大大减少参数量,二来每个卷积核在图像处理领域就是一次特征提取。
池化采样
局部连接和权值共享都把参数量大大减少,但是这两步的感受野却没有变化,也就是直到此刻我们提取的特征还是局部细节特征,那么池化采样就是一个改变感受野大小的操作,实现多尺度多层次的特征提取。首先我们来看下什么是池化,对于图像中一个 2×2 大小的region区域,我想用一个值来代替这个region的feature,根据取值的方式不同,通常分为max pooling和mean pooling,max pooling是指取这个region这个中最大的值来做为feature,如下图中的黄色区域最大值为7;mean pooling就是指用区域内所用值的平均值来作为feature,例如黄色区域3,6,4,7的平均值是5。当然随机pooling是一种不常用的pooling方式,做法是先把region中的值归一化为概率map,然后根据这个概率分布随机挑选一个值作为下一层的feature。
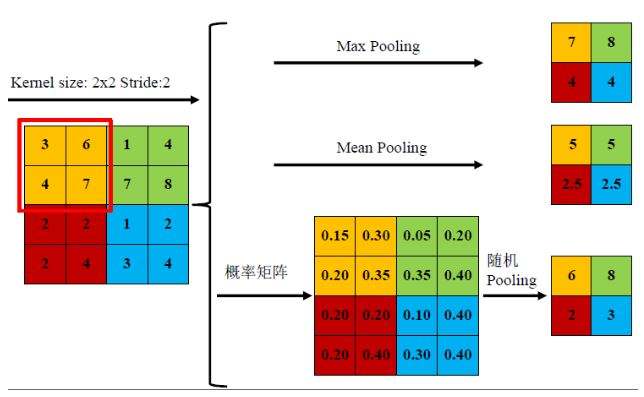
接下来我们来理解下pooling操作,首先是为什么是max和mean,mean挺好理解的,我们做事情通常喜欢用平均值来代替一个集合的性能。那么为什么是max而不是min了,这就要从神经网络的工作原理来理解,神经网络某个神经元的值特别大的话,说明这个神经元代表的属性被激活,浅层的可以是直线纹理等特征,高层的可以代表猫狗之类的特征,我们需要把这些被激活的特征属性给传下,所以用的是max而不是min。
另外一个理解就是为什么需要pooling,前面提到pooling可以改变感受野大小。这里假设每次都是 2×2 大小的pooling,每做一次pooling之后feature map大小就变为了之前的一半,那么是不是第二层做pooling的时候就用到了原始图片 4×4 大小region的信息呢?越高层关注的区域就越大,也就是说感受野在逐渐变大,浅层关注的是局部的细节特征,高层关注的是更加广阔的全局(实际上是更大的局部)特征,pooling把CNN的提取特征的层次感给体现了。这也就是为什么CNN会这么有用的原因,应该说pooling是整个卷积网络的点睛之笔,没有了pooling的CNN和传统NN并没有本质区别。
当然这里提前埋个问题,就是这里pooling是的图像的尺寸发生了变化,那么反向传播的时候怎么解决梯度传播的问题呢?这里之后会写一篇博客来描述这个问题。
pooling使得CNN的特征有了层次感,所以我们也可以根据任务选择到底是用浅层特征还是高层特征,识别问题我们可能会关注高层特征,但是有时我们识别颜色之类可能会更加关注浅层特征。
CNN进行图像识别
经过上面的三个操作,我们把一张图片输入到CNN中,最后我们可以得到 h×w×n 大小的feature map,这三个字母分别代表最后一层输出feature map的长、宽和通道数,是一个三维的张量,要做分类的话首先需要把它展平为一个一维的feature vector,大部分框架都是Flatten函数来实现,这样一来就变成传统的神经网络,只要在后面加几层全连接层,就和原来的神经网络是一样的,下面是keras的手写体CNN识别代码,正常情况下可以达到98%左右的准确度。
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))大概直观的长相就用下面这个经典图吧,和代码不是同一个model,但是流程差不多
![]()
global average pooling
当然flatten展平是一种非常好资源的展平操作,当你用CNN网络分类的时候你会发现,有时全连接的参数量占了网络绝大数,因为卷积层的参数量就是卷积核的大小乘以卷积核的数量再加上偏置b而已,但是两层全连接的参数量是两层神经元数目的乘积,两个1000大小的全连接就有10^5大小的参数量,所以有人研究用global average pooling来代替flatten的操作实现展平再做分类,这可以减少一点参数量,有兴趣的人可以自行查阅,之后根据进度考虑是否介绍global average pooling。