专业英语(7、Convolutional Neural Networks)
Fast-forward to today: ConvNets are everywhere:
- classification 图像分类
- retrieval 图像检索
- detection 图像检测
- segmentation 图像分割
- self-driving cars 自动驾驶汽车
- image captioning 图像字幕
- examples of pose estimation 姿势估计的例子

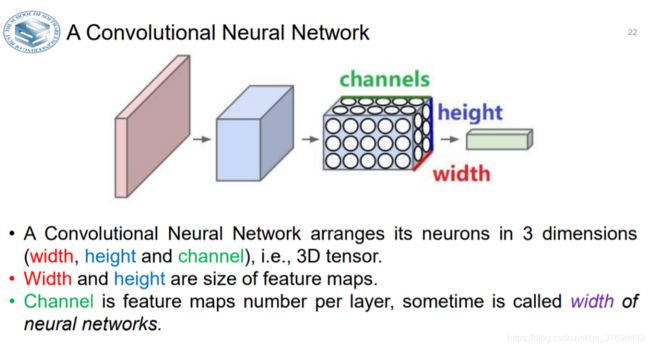
- 卷积神经网络将其神经元排列成3维(宽度,高度和通道),即3D张量。
- 宽度和高度是要素图的大小。
- Channel是每层的特征映射数,有时称为神经网络的宽度
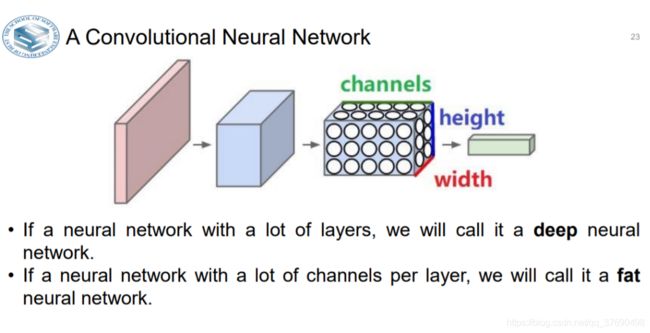
- 如果一个有很多层的神经网络,我们称之为深层神经网络网络。
- 如果一个神经网络每层有很多通道,我们称之为胖神经网络。
Convolutional Layer(卷积层)

用来构建卷积网络的各种层
一个简单的卷积神经网络是由各种层按照顺序排列组成,网络中的每个层使用一个可以微分的函数将激活数据从一个层传递到另一个层。卷积神经网络主要由三种类型的层构成 :卷积层,汇聚(Pooling)层和全连接层(全连接层和常规神经网络中的一样。通过将这些层叠加起来,就可以构建一个完整的卷积神经网络。
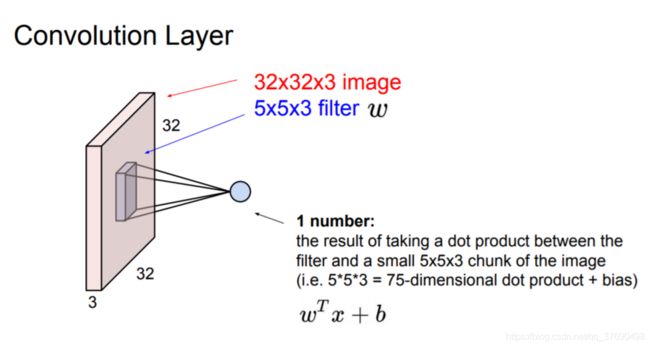
- 输入[32x32x3]存有图像的原始像素值,本例中图像宽高均为32,有3个颜色通道。
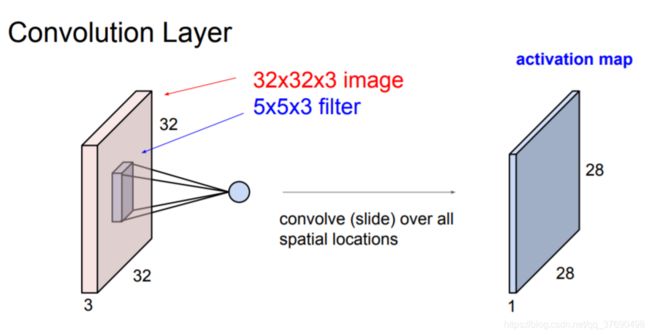
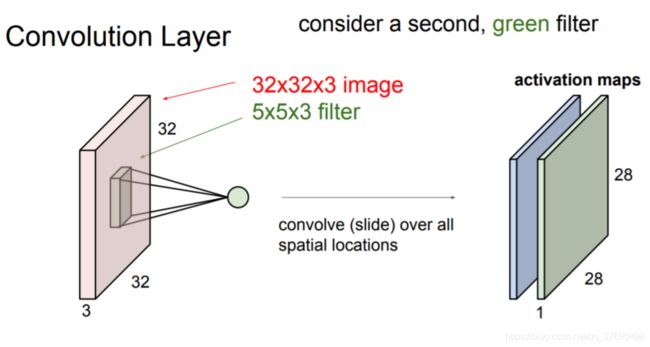
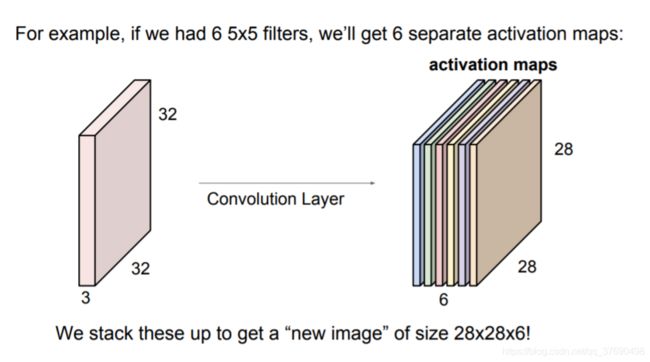
- 卷积层中,神经元与输入层中的一个局部区域相连,每个神经元都计算自己与输入层相连的小区域与自己权重的内积。卷积层会计算所有神经元的输出。如果我们使用12个滤波器(也叫作核),得到的输出数据体的维度就是[32x32x12]。
- ReLU层将会逐个元素地进行激活函数操作,比如使用以0为阈值的max(0,x)作为激活函数。该层对数据尺寸没有改变,还是[32x32x12]。
- 汇聚层在在空间维度(宽度和高度)上进行降采样(downsampling)操作,数据尺寸变为[16x16x12]。
- 全连接层将会计算分类评分,数据尺寸变为[1x1x10],其中10个数字对应的就是CIFAR-10中10个类别的分类评分值。正如其名,全连接层与常规神经网络一样,其中每个神经元都与前一层中所有神经元相连接。
由此看来,卷积神经网络一层一层地将图像从原始像素值变换成最终的分类评分值。其中有的层含有参数,有的没有。具体说来,卷积层和全连接层(CONV/FC)对输入执行变换操作的时候,不仅会用到激活函数,还会用到很多参数(神经元的突触权值和偏差)。而ReLU层和汇聚层则是进行一个固定不变的函数操作。卷积层和全连接层中的参数会随着梯度下降被训练,这样卷积神经网络计算出的分类评分就能和训练集中的每个图像的标签吻合了。
小结:
- 简单案例中卷积神经网络的结构,就是一系列的层将输入数据变换为输出数据(比如分类评分)。
- 卷积神经网络结构中有几种不同类型的层(目前最流行的有卷积层、全连接层、ReLU层和汇聚层)。
- 每个层的输入是3D数据,然后使用一个可导的函数将其变换为3D的输出数据。
- 有的层有参数,有的没有(卷积层和全连接层有,ReLU层和汇聚层没有)。
- 有的层有额外的超参数,有的没有(卷积层、全连接层和汇聚层有,ReLU层没有)
卷积层例子:
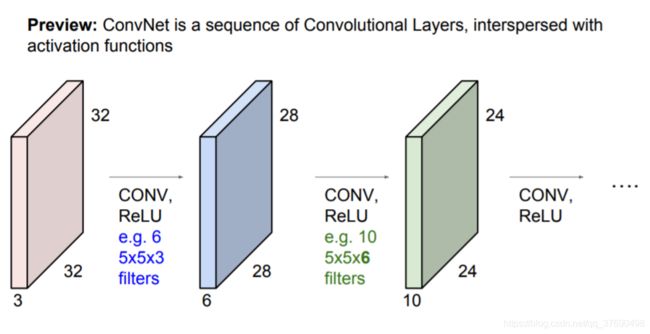
注意:
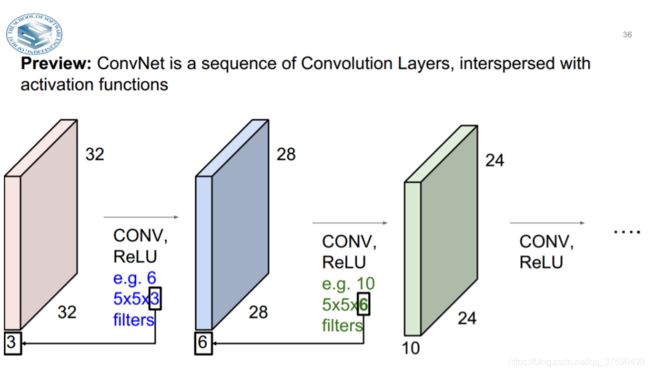
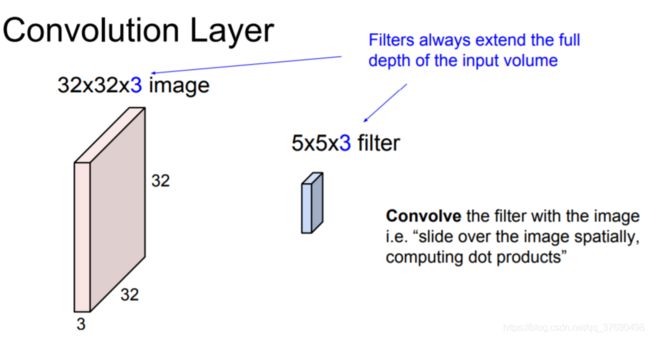
- Channel of the output volume is a hyperparameter. 应该说,filter的尺寸是一个超参数。其实就是滤波器的空间尺寸。
- filter深度上总是和输入数据的深度一致。即:Channel
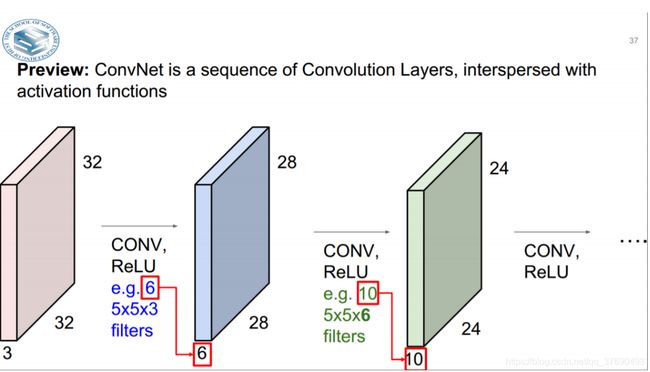
- 输出数据体的深度是一个超参数:它和使用的滤波器的数量一致
例1:假设输入数据体尺寸为[32x32x3](比如CIFAR-10的RGB图像),如果感受野(或滤波器尺寸)是5x5,那么卷积层中的每个神经元会有输入数据体中[5x5x3]区域的权重,共5x5x3=75个权重(还要加一个偏差参数)。注意这个连接在深度维度上的大小必须为3,和输入数据体的深度一致。
例2:假设输入数据体的尺寸是[16x16x20],感受野尺寸是3x3,那么卷积层中每个神经元和输入数据体就有3x3x20=180个连接。再次提示:在空间上连接是局部的(3x3),但是在深度上是和输入数据体一致的(20)。
空间排列
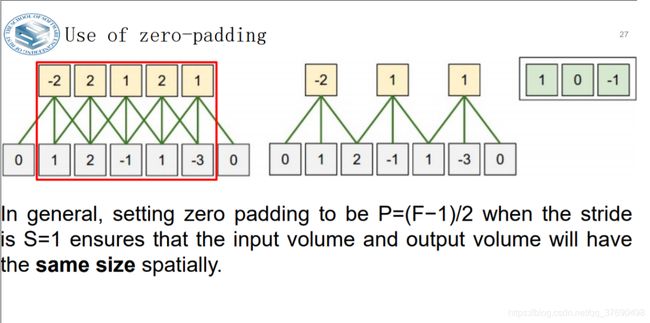
深度(depth),步长(stride)和零填充(zero-padding)

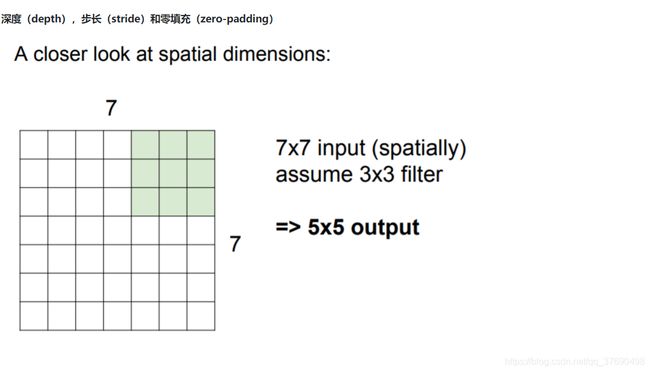
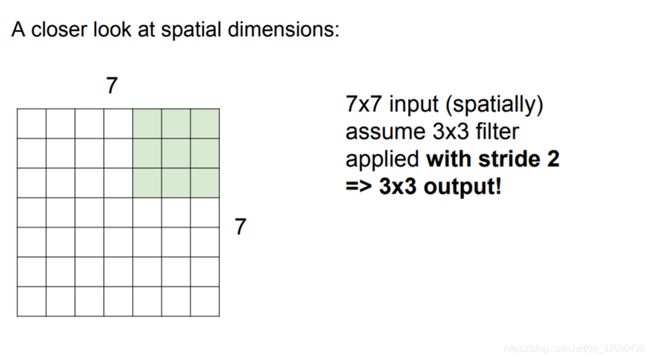

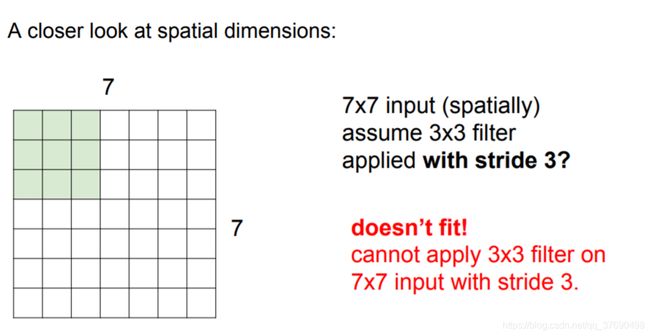

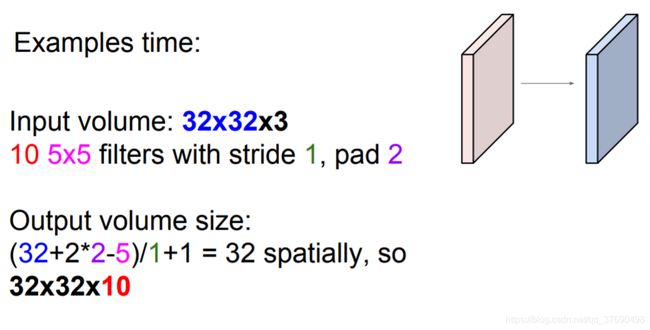
输出数据体在空间上的尺寸可以通过输入数据体尺寸(W),卷积层中神经元的感受野尺寸(F),步长(S)和零填充的数量(P)的函数来计算。(译者注:这里假设输入数组的空间形状是正方形,即高度和宽度相等)输出数据体的空间尺寸为(W-F +2P)/S+1。
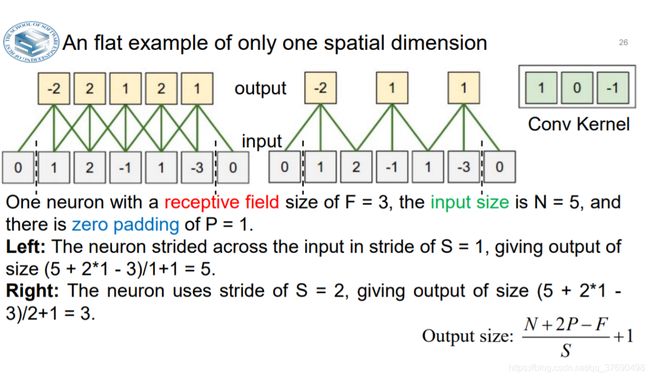
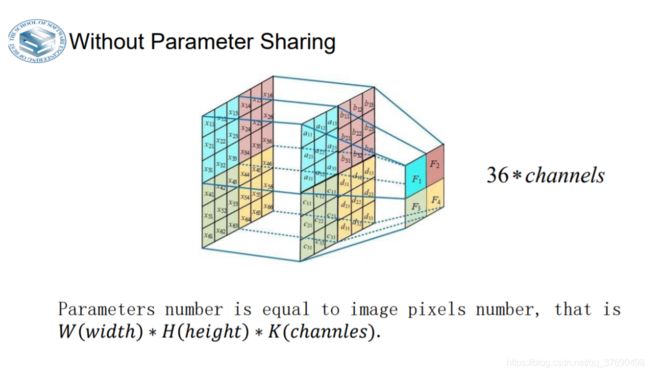
- 参数的数量是等同于图像像素数量。

- 请注意,参数共享假设是相对合理的:如果检测到水平边缘在图像中的某个位置很重要,那么由于图像的平移不变结构,它在某些其他位置也应该直观有用。
- 因此无需重新学习检测在卷积层输出体积中的55 * 55个不同位置中的每一个是否处于水平边缘。
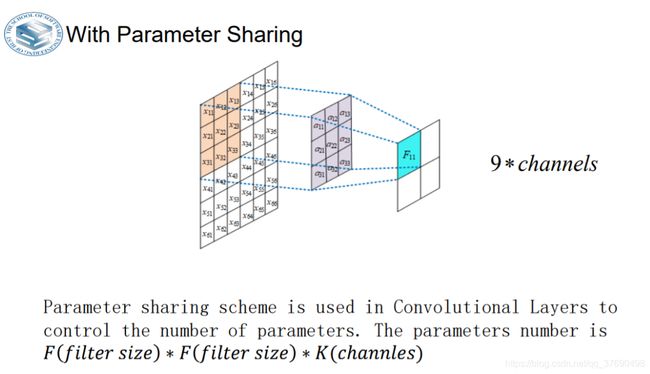
- 在卷积层中使用参数共享是用来控制参数的数量。
就用上面的例子,在第一个卷积层就有55x55x96=290,400个神经元,每个有11x11x3=364个参数和1个偏差。将这些合起来就是290400x364=105,705,600个参数。单单第一层就有这么多参数,显然这个数目是非常大的。
- 作一个合理的假设:
如果一个特征在计算某个空间位置(x,y)的时候有用,那么它在计算另一个不同位置(x2,y2)的时候也有用。基于这个假设,可以显著地减少参数数量。换言之,就是将深度维度上一个单独的2维切片看做深度切片(depth slice),比如一个数据体尺寸为[55x55x96]的就有96个深度切片,每个尺寸为[55x55]。
在每个深度切片上的神经元都使用同样的权重和偏差。在这样的参数共享下,例子中的第一个卷积层就只有96个不同的权重集了,一个权重集对应一个深度切片,共有96x11x11x3=34,848个不同的权重,或34,944个参数(+96个偏差)。在每个深度切片中的55x55个权重使用的都是同样的参数。

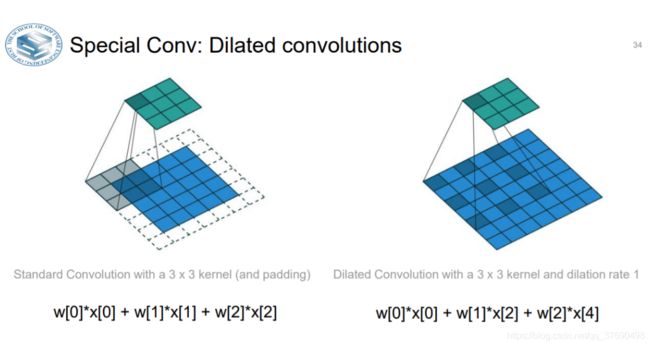
- 卷积层引入了一个新的叫扩张(dilation)的超参数。
- 到目前为止,我们只讨论了卷积层滤波器是连续的情况。但是,让滤波器中元素之间有间隙也是可以的,这就叫做扩张。
举例,在某个维度上滤波器w的尺寸是3,那么计算输入x的方式是:w[0]*x[0] + w[1]*x[1] + w[2]*x[2],此时扩张为0。如果扩张为1,那么计算为: w[0]*x[0] + w[1]*x[2] + w[2]*x[4]。换句话说,操作中存在1的间隙。在某些设置中,扩张卷积与正常卷积结合起来非常有用,因为在很少的层数内更快地汇集输入图片的大尺度特征。比如,如果上下重叠2个3x3的卷积层,那么第二个卷积层的神经元的感受野是输入数据体中5x5的区域(可以成这些神经元的有效感受野是5x5)。如果我们对卷积进行扩张,那么这个有效感受野就会迅速增长。
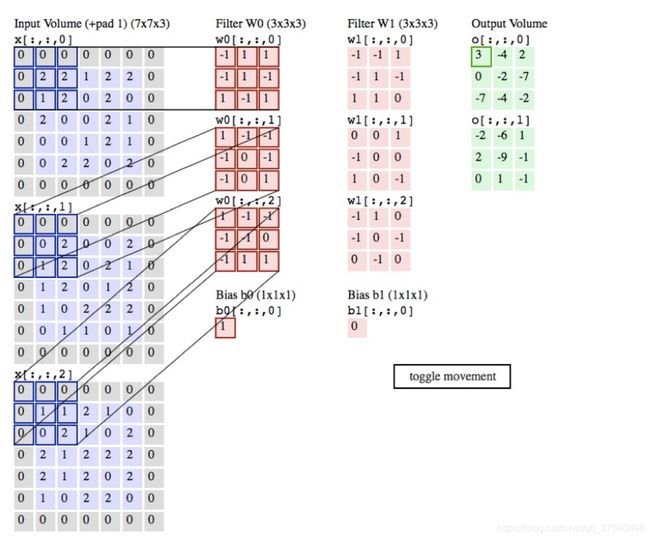


- 输入数据体的尺寸为 W1× H1×D_1
- 4个超参数:
- 滤波器的数量K
- 滤波器的空间尺寸F
- 步长S
- 零填充数量P
- 输出数据体的尺寸为W2×H2×D2 ,其中:
W2=(W1-F+2P)/S+1
H2=(H_1-F+2P)/S+1 (宽度和高度的计算方法相同)
D_2=K
- 由于参数共享,每个滤波器包含F× F× D1个权重,卷积层一共有F× F× D1×k个权重和K个偏置。
- 在输出数据体中,第d个深度切片(空间尺寸是W2× H2),用第d个滤波器和输入数据进行有效卷积运算的结果(使用步长S),最后在加上第d个偏差。
Convolutional Neural Networks—— Pooling Layer
Pooling Layer:
- makes the representations smaller and more manageable
- operates over each activation map independently
- 使表示更小,更易于管理
- 独立地操作每个激活图
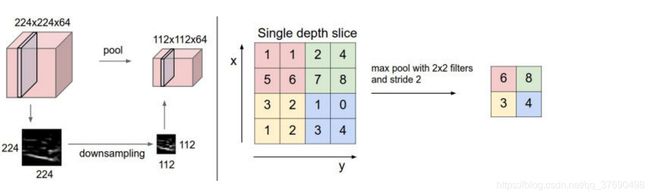
- Downsampling layer
汇聚层在输入数据体的每个深度切片上,独立地对其进行空间上的降采样。
左边:本例中,输入数据体尺寸[224x224x64]被降采样到了[112x112x64],采取的滤波器尺寸是2,步长为2,而深度不变。
右边:最常用的降采样操作是取最大值,也就是最大汇聚,这里步长为2,每个取最大值操作是从4个数字中选取(即2x2的方块区域中)。



Why we need pooling?
- Reduce size of feature maps (also number of parameters)
- Bring non-linearity to Neural Networks
- Preserve scale, transform and rotation invariant of images
- 减少要素图的大小(也是参数数量)
- 为神经网络带来非线性
- 保持图像的缩放,变换和旋转不变
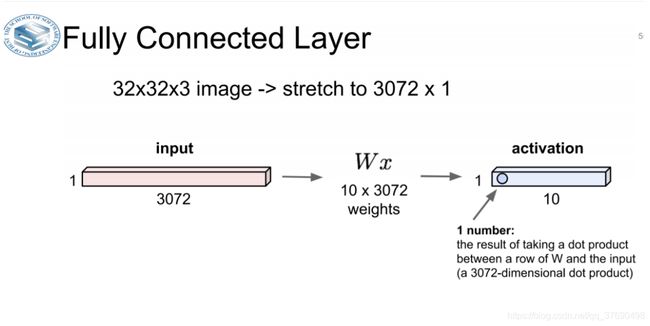
Fully Connected Layer(FC Layer)