动态表的持续查询
用 SQL 分析数据流
越来越多的公司正在采用流式处理,并且将现存的批处理应用程序迁移到流式或者对新的用例使用流式解决方案。而这些应用程序的大多数是专注于分析流式数据的。被分析的数据流来自于各种各样的数据源,比如数据库事务、点击、传感器测量或者 IoT 设备。
Apache Flink 非常适用于流式分析应用程序,因为它提供了 Event Time 语义的支持,有状态的 Extractly-Once 处理,同时实现了高吞吐量和低延迟。基于这些特性,Flink 能够近实时性地对海量数据计算准确且确定的结果,并且在失败时提供 Extractly-Once 语义。
Flink 流式处理的核心 API——DataStream API 是富有表现力的,为很多常见操作提供了原语。在其他特性中,它提供了高度可定制的窗口化逻辑,具有不同性能特征的不同状态原语,用于注册计时器并对计时器作出反应的钩子,以及用于向外部系统发出高效异步请求的工具。许多流分析应用程序遵循类似的模式,并且不需要 DataStream API 提供的表达级别。它们用一种领域特定语言以更自然和简洁的方式表达。众所周知,SQL是数据分析的事实标准。对于流式分析,SQL 将使更多人能够在更短的时间内指定数据流上的应用程序。但是,还没有开源流处理器提供像样的 SQL 支持
为什么 SQL on Streams 如此重要?
SQL 被广泛使用于数据分析具有以下几个原因:
- SQL 是声明式的:你可以指定想要的,而不是如何去计算。
- SQL 可以被有效地优化:优化器可以找出一个有效的计划去计算结果。
- SQL 可以被有效地评估:执行引擎能准确地知道计算了什么,以及如此有效地计算。
- 最后,每个人都知道,而且许多工具都使用SQL。
因此,使用 SQL 处理和分析数据流使流式处理技术可以供更多用户使用。此外,由于SQL的声明性和自动优化的潜力,它大大减少了定义高效流式分析应用程序的时间和精力。
但是,SQL(以及关系数据模型和代数)在设计时并未考虑流式数据。关系是(多个)集合,而不是元祖的无限序列。当执行 SQL 查询的时候,常规的数据库系统和查询引擎读取并处理一个完全可用的数据集,并产生固定大小的结果。相反,数据流持续不断地提供提供新的记录,以便数据随时间到达。因此,流式查询不得不持续地处理正在达到的数据而且不能“完成”。
话虽如此,使用 SQL 处理流也并不是不可能的。一些关系数据库系统的特点是维护物化视图(Materialized View),这类似于评估数据流上的 SQL 查询。物化视图被定义为 SQL 查询,就像常规的(虚拟的)视图。但是,查询的结果实际上是存储(或物化)在内存或磁盘上,以便查询时视图无需即时计算。为了防止物化视图过期,数据库系统需要在其基础关系(在其定义查询中引用的表)被修改时更新视图。如果我们将视图基础关系上的改变视为修改流(或者更改日志流),那么很明显物化视图维护和流式 SQL 是有某种关系。
Flink 的关系 APIs: Table API 和 SQL
从 1.1.0 版本(2016 年 8 月发布)以来,Flink 具有两个语义上等价的关系 API,即语言嵌入的 Table API(Java 和 Scala)和标准 SQL。两种 API 均设计为用于在线流式和历史批处理数据的统一 API。这意味着:
无论查询的输入是静态批处理数据还是流数据,查询都会产生完全相同的结果。
统一流和批处理的 API 是很重要的。首先,用户只需要学习一套 API 即可处理静态数据和流数据。使用同一查询分析批和流式数据,这意味着可以在同一查询中同时分析历史和在线数据。到目前为止,我们尚未完全实现批处理和流语义的统一,但社区朝着这个目标取得很好的进步。
下面的代码段展示了两个等价的 Table API 和 SQL 在一个温度传感器测量流上计算一个简单的窗口化聚合。SQL 查询的语法是基于 Apache Calcite 的分组窗口函数的语法,并且在 Flink 1.3.0 中得到支持。
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val tEnv = TableEnvironment.getTableEnvironment(env)
// define a table source to read sensor data (sensorId, time, room, temp)
val sensorTable = ??? // can be a CSV file, Kafka topic, database, or ...
// register the table source
tEnv.registerTableSource("sensors", sensorTable)
// Table API
val tapiResult: Table = tEnv.scan("sensors") // scan sensors table
.window(Tumble over 1.hour on 'rowtime as 'w) // define 1-hour window
.groupBy('w, 'room) // group by window and room
.select('room, 'w.end, 'temp.avg as 'avgTemp) // compute average temperature
// SQL
val sqlResult: Table = tEnv.sql("""
|SELECT room, TUMBLE_END(rowtime, INTERVAL '1' HOUR), AVG(temp) AS avgTemp
|FROM sensors
|GROUP BY TUMBLE(rowtime, INTERVAL '1' HOUR), room
|""".stripMargin)
如你所见,这两个 API 与 Flink 的主要 DataStream 和 DataSet API 紧密集成在一起。Table 和 DataSet 或 DataStream 相互转换。因此,可以很容易地扫描一个外部表,如数据库或 Parquet 文件,用 Table API 查询做一些预处理,将结果转换为 DataSet,以及用它运行 Gelly 图算法。上述例子中定义的查询通过改变以下运行环境也可以用于处理批量数据。
在内部,两种 API 都被翻译成相同的逻辑表达,由 Apache Calcite 优化,被编译成 DataSet 或 DataStream 程序。事实上,优化和转换过程不知道查询是使用 Table API 还是 SQL 定义的。如果你对优化过程的细节比较好奇,可以看这篇文章。因为 Table API 和 SQL 在语义上是等价的,仅在语法上有所不同。所以在本文中谈论 SQL 时,我们总是同时引用这两种 API。
在当前的版本 1.2.0 中,Flink 的关系 API 在数据流上支持一组有限的关系算子,包括投影,过滤和窗口聚合。所有支持的运算符的共同点是,它们从不更新已提交的结果记录。对于像投影和过滤这样的一次一个记录算子来说,这显然不是问题。但是,它影响收集和处理多个记录的算子,如窗口聚合。由于已提交的结果不能更新,在 Flink 1.2.0 中于结果提交之后到达的输入记录不得不丢弃。
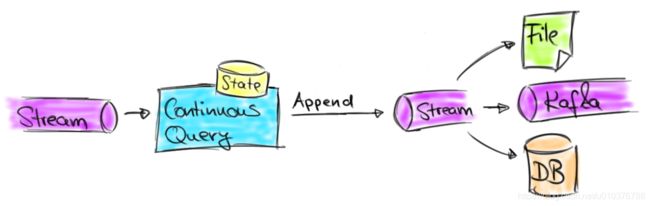
当前版本的限制对于提交数据到 Kafka Topic、消息队列或者文件这种只支持追加操作而不支持修改和删除的应用程序来说是可以接受的。遵循此模式的常见用例是例如连续 ETL 和流归档应用程序,将流持久化保存到归档文件中或为进一步的联机(流)分析或以后的脱机分析准备数据。由于不能更新先前已提交的结果,这种应用程序不得不确保已提交的结果是正确的,并且将来无需进行校正。下图说明了此类应用。
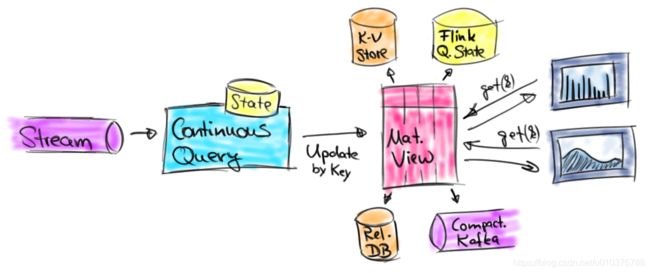
虽然仅支持追加的查询对于某些类型的应用程序和某些类型的存储系统很有用,但是有许多流式分析用例需要更新结果。这包括不能丢弃迟到的记录,需要(长期运行)窗口聚合的早期结果或需要无窗口化聚合之类的应用程序。在这些应用程序中,之前已提交的结果需要被更新。更新结果的查询通常将其结果物化到外部数据库或键值存储中,以使其可被外部应用程序访问和查询。实现此模式的应用程序是大盘,报表应用程序或其他应用程序,它们需要及时访问不断更新的结果。下图说明了这类应用程序。
动态表的持续查询
支持更新以前已提交的结果查询是 Flink 关系 API 的下一步。它极大地增加了 API 的范围和受支持的用例的范围。 此外,许多新支持的用例对于使用 DataStream API 可能是具有挑战性的。
因此,当添加对结果更新查询的支持时,我们当然必须保留流和批处理的统一语义。我们通过动态表(Dynamic Table) 的概念来实现。动态表是一个可持续更新的,能够像常规的静态表那样查询的表。但是,与终止并返回静态表作为结果的批处理表的查询相反,动态表上的查询连续运行并生成一个随着输入表的更新而不断更新的表。因此,结果表也是一个动态表。这个概念和我们上文讨论的物化视图维护非常相似。
假设我们可以在生成新动态表的动态表上运行查询,那么下一个问题是,流和动态表如何相互关联?答案就是流可以转换为动态表,动态表也可以转换为流。下图显示了在流上处理关系查询的概念模型。

首先,流转换为一个动态表。这个动态表被持续查询,并生成一个新的动态表。最后,该结果表被转换为流。需要注意的是,这只是一个逻辑模型,并不意味着查询实际上是如何执行的。实际上,持续查询在内部转换为常规的 DataStream 程序。
下面我们描述此模型的不同步骤:
- 在流上定义动态表;
- 查询动态表;
- 生成动态表。
在流上定义动态表
评估动态表上的SQL查询的第一步是在流上定义动态表。这意味着我们必须指定流的记录如何修改动态表。流携带的记录必须具有映射到表的关系 Schema 的 Schema。流上定义动态表有两种模式:追加模式(Append Mode) 和 更新模式(Update Mode)。
在追加模式中,每个流记录都是对动态表的插入修改。 因此,流的所有记录都将追加到动态表,以使其不断增长且大小无限。下图说明了追加模式。
在更新模式中,每个流记录可以表现对动态表的插入,更新或删除修改(事实上,追加模式是更新模式的一个特例)。当通过更新模式在流上定义动态表时,我们可以在表中指定一个唯一的键属性。在这种情下,针对相应的键属性执行更新和删除操作。下图显示了更新模式。

查询动态表
一旦我们定义了动态表,就可以对其进行查询。由于动态表会随时间变化,因此我们必须定义查询动态表的含义。假设我们在特定时间为动态表制作了快照。该快照可以被视为常规静态批处理表。 我们将点 t t t 处的动态表 A A A 的快照表示为 A [ t ] A[t] A[t]。可以使用任何 SQL 查询该快照。该查询将生成一个常规静态表作为结果。我们将在时间 t t t 的动态表 A A A 上查询 q q q 的结果表示为 q ( A [ t ] ) q(A[t]) q(A[t])。如果我们对动态表的快照重复计算查询结果以获取时间上的进展,我们会获得许多随时间变化的静态结果表,并有效地构成了动态表。我们定义动态表上的查询语义如下:
动态表 A A A 的查询 q q q 会生成动态表 R R R,动态表 R R R 在每个时间点 t t t 都等于对 A [ t ] A[t] A[t] 应用 q q q 的结果,即 R [ t ] = q ( A [ t ] ) R[t] = q(A[t]) R[t]=q(A[t])。这个定义意味着在批处理表和流式表上运行相同的查询 q q q 会产生相同的结果。下面我们给出两个例子来说明动态表上的查询语义。
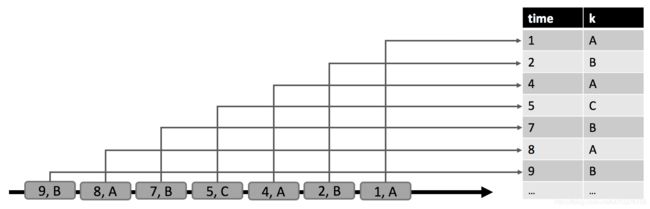
在下图中,我们看到左边有一个动态输入表 A A A,它被定义为追加模式。在 t = 8 t = 8 t=8 时, A A A 由六行组成(蓝色)。在 t = 9 t = 9 t=9 和 t = 12 t = 12 t=12 时,将一行追加到 A A A(分别以绿色和橙色显示)。我们在表 A A A 上运行一个图中间展示的简单的查询。这个查询对属性 k k k 进行分组,并且统计每个分组中的记录数。在右手边,我们可以看到在 t = 8 t = 8 t=8(蓝色) 、 t = 9 t = 9 t=9(绿色)和 t = 12 t = 12 t=12(橙色)时的查询结果。在时间 t t t 上的每个时间点,结果表等价于在时间 t t t 处的动态表 A A A 上的批量查询。
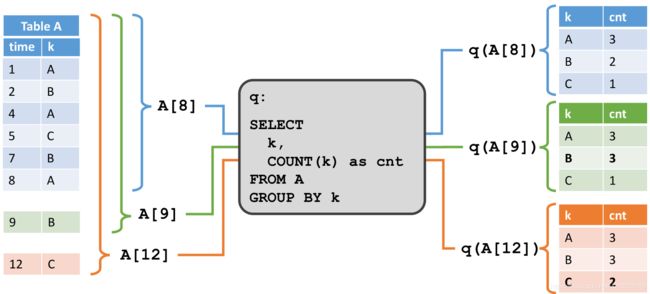
上例中的查询是一个简单的分组聚合(没有窗口)查询,因此,结果表的大小取决于输入表的不同分组键的数量。另外,值得注意的是,查询会不断更新其先前提交的结果行,而不是仅添加新行。
第二个示例显示了一个相似的查询,但在一个重要方面有所不同。除了对键属性 k k k 进行分组外,查询还将记录分为 5 秒钟的滚动窗口,这意味着它每五秒钟计算k的每个值的计数。同样,我们可以使用 Calcite 的分组窗口函数指定这个查询。在图的左边,我们看到输入表 A A A,以及它如何在追加模式下随时间变化的。在图的右边,我们看到结果表和它又如何随时间演变的。
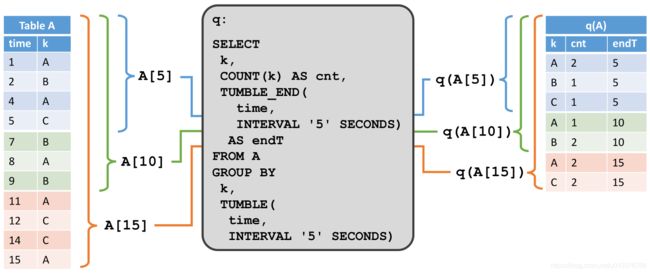
与第一个示例的结果相比,它的结果表相对于时间增长,例如,每五秒钟计算一次新的结果行(假设输入表在最近五秒钟内收到了更多记录)。虽然无窗口化查询(大多数情况下)会更新结果表的行,但窗口聚合查询只会将新行追加到结果表中。
尽管本文侧重于动态表上 SQL 查询的语义,而不是如何有效处理此类查询,但我们想指出的是,无论输入表何时更新,都不可能从头计算查询的完整结果。取而代之的是,查询被编译为流式程序,该流式程序将根据其输入的变化持续更新其结果。这意味着并不是所有有效的 SQL 查询都支持,而仅支持那些可以连续,增量和有效地计算的查询。 我们计划在后续文章中讨论有关对动态表上的 SQL 查询进行评估的详细信息。
生成动态表
查询动态表会生成另一个动态表,该表表示这个查询的结果。根据查询及其输入表,结果表会像常规数据库表一样通过插入,更新和删除进行连续更新。它可能是一个只有一行且不断更新的表,一个没有更新只有插入的表,或介于两者之间的任何内容。
传统的数据库系统在发生故障时使用日志来重建表并进行复制。这些日志技术包括 UNDO、REDO 和 UNDO/REDO 日志。简而言之,UNDO 日志记录已修改元素的先前值以回滚未完成的事务,REDO 日志记录修改后的元素的新值以重做已完成事务丢失的更改,UNDO/REDO 日志记录已更改元素的旧值和新值以撤消未完成的事务并重做已完成事务丢失的更改。根据这些日志技术的原理,可以将动态表转换为两种类型的变更日志流:REDO 流和 REDO+UNDO 流。
通过将表的修改转换为流消息,动态表转换为 REDO+UNDO 流。插入修改生成一条新行的插入消息,删除修改生成一条旧行的删除消息,更新修改生成一条旧行的删除消息和一条新行的插入消息,如下图所示。
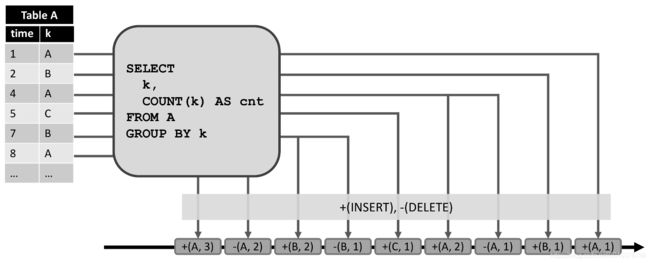
图中左边的动态表维护在追加模式下,并且作为图中间查询的输入。这个查询的结果转换为 REDO+UNDO 流呈现在图的底部。输入表的第一条记录 ( 1 , A ) (1,A) (1,A) 在结果表中产生一条新记录,因此在该流中产生一条插入消息 + ( A , 1 ) +(A,1) +(A,1)。 k = A k = A k=A 的第二个输入记录 ( 4 , A ) (4,A) (4,A) 在结果表中产生 ( A , 1 ) (A,1) (A,1) 记录的更新,因此生成一条删除消息 − ( A , 1 ) -(A,1) −(A,1) 和一条插入消息 + ( A , 2 ) +(A,2) +(A,2)。所有下游算子或数据接收器都需要能够正确处理这两种类型的消息。
在两种情况下,动态表可以转换为 REDO 流:要么它是仅追加(Append-Only)表(如,只有插入修改),要么它具有唯一键属性。动态表的每一个插入修改都会生成一条新行的插入信息到 REDO 流中。由于 REDO 流的限制,只有具有唯一键的表才能进行更新和删除修改。如果从具有键的动态表中删除了某个键,则可能是因为删除了行,或者因为修改了行的键属性,带有删除的键的删除消息会生成到 REDO 流中。更新修改产生具有更新的更新消息,即新行。由于删除和更新修改是根据唯一键定义的,因此下游算子需要能够通过键访问先前的值。下图显示了如何将与上述相同查询的结果表转换为 REDO 流。
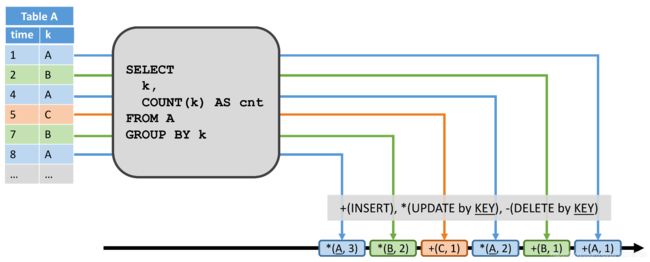
插入动态表的行 ( 1 , A ) (1,A) (1,A) 生成了 + ( A , 1 ) +(A,1) +(A,1) 的插入信息。更新的行 ( 4 , A ) (4,A) (4,A) 生成了 ∗ ( A , 2 ) *(A, 2) ∗(A,2) 的更新信息。
REDO 流的常见用例是将查询结果写入仅追加(Append-Only)存储系统,像滚动文件或Kafka Topic,或写入具有键访问的数据存储,如 Cassandra,关系型 DBMS 或压缩的 Kafka Topic。还可以在流应用程序内部将动态表物化为 Keyed State,以评估连续查询并使之可从外部系统查询。通过这种设计,Flink 自身可以在流上维护连续 SQL 查询的结果,并在结果表上提供键查找,例如从仪表板应用程序中查找。
切换到动态表时会发生的变化
在 1.2 版本中,Flink 关系 API 的所有流式算子,像过滤、投影和分组窗口聚合,只能够提交新行而没有更新先前已提交结果的能力。相反,动态表能够处理更新和删除修改。现在你可能会问自己,当前版本的处理模型如何与新的动态表模型关联呢?API的语义是否会完全改变,我们是否需要从头开始重新实现 API 以满足所需的语义?
所有这些问题的答案都是简单的。当前版本的处理模型是动态表模型一个子集。使用我们在本文中介绍的术语,当前模型以追加模式将流转换为动态表,即无限增长的表。由于所有的算子只接受插入更改,并在其结果表上生成插入更改(即生成新行),因此所有受支持的查询都将生成动态追加表,并使用仅追加(Append-Only)表的重做模型将其转换回 DataStream。所以,新的动态表模型完全覆盖并保留了当前模型的语义。
总结与展望
Flink 的关系 API 非常适合立即实施流分析应用程序,并且可以在多种生产环境中使用。在本文中,我们讨论了 Table API 和 SQL 的未来。这一努力将使 Flink 和流处理可供更多人使用。此外,用于查询历史数据和实时数据的统一语义以及查询和维护动态表的概念将大大简化许多令人兴奋的用例和应用程序的实现。在本文中我们主要在讨论流和动态表上的关系查询的语义,而没有讨论查询如何执行的详细信息,这其中包括撤回的内部实现,后期事件的处理,对早期结果的支持以及对边界空间的限制。我们计划在以后的某个时间发布有关此主题的后续文章。
最近几个月,Flink 社区的许多成员一直在讨论关系 API 并为之做出贡献。到目前为止,我们已经取得了很大进展。尽管大多数工作都集中在以追加模式处理流上,但是日程上的下一步是处理动态表以支持更新其结果的查询。如果您对使用 SQL 处理流的想法感到兴奋,并且希望为此做出贡献,请提供反馈,加入邮件列表中的讨论或解决 JIRA 问题。
扫码关注公众号:冰山烈焰的黑板报
