Elasticsearch Suggester详解
非常全面的一篇关于ElasticSearch提示词的文章,一步一步简单清晰,我就是照这个把项目的提示词功能做出来的。
原文地址:http://elasticsearch.cn/article/142
原文作者:kennywu76
原文社区:Elastic中文社区
现代的搜索引擎,一般会具备"Suggest As You Type"功能,即在用户输入搜索的过程中,进行自动补全或者纠错。 通过协助用户输入更精准的关键词,提高后续全文搜索阶段文档匹配的程度。例如在Google上输入部分关键词,甚至输入拼写错误的关键词时,它依然能够提示出用户想要输入的内容:
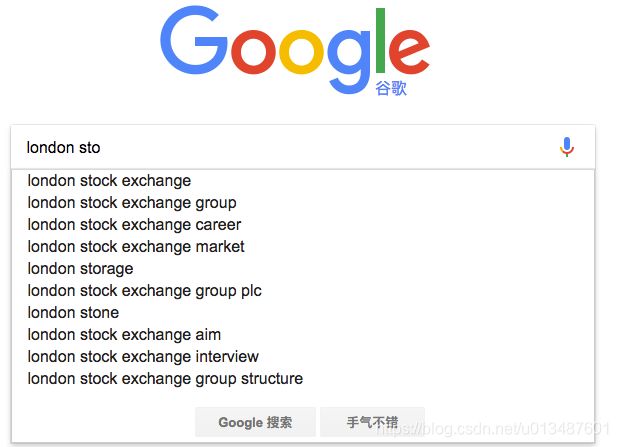

如果自己亲手去试一下,可以看到Google在用户刚开始输入的时候是自动补全的,而当输入到一定长度,如果因为单词拼写错误无法补全,就开始尝试提示相似的词。
那么类似的功能在Elasticsearch里如何实现呢? 答案就在Suggesters API。
Suggesters基本的运作原理是将输入的文本分解为token,然后在索引的字典里查找相似的term并返回。 根据使用场景的不同,Elasticsearch里设计了4种类别的Suggester,分别是:
- Term Suggester
- Phrase Suggester
- Completion Suggester
- Context Suggester
在官方的参考文档里,对这4种Suggester API都有比较详细的介绍,但苦于只有英文版,部分国内开发者看完文档后仍然难以理解其运作机制。 本文将在Elasticsearch 5.x上通过示例讲解Suggester的基础用法,希望能帮助部分国内开发者快速用于实际项目开发。限于篇幅,更为高级的Context Suggester会被略过。
首先来看一个Term Suggester的示例:
准备一个叫做blogs的索引,配置一个text字段。
PUT /blogs/
{
"mappings": {
"properties": {
"body": {
"type": "text"
}
}
}
}
通过bulk api写入几条文档
POST _bulk/?refresh=true
{ "index" : { "_index" : "blogs"} }
{ "body": "Lucene is cool"}
{ "index" : { "_index" : "blogs"} }
{ "body": "Elasticsearch builds on top of lucene"}
{ "index" : { "_index" : "blogs"} }
{ "body": "Elasticsearch rocks"}
{ "index" : { "_index" : "blogs"} }
{ "body": "Elastic is the company behind ELK stack"}
{ "index" : { "_index" : "blogs"} }
{ "body": "elk rocks"}
{ "index" : { "_index" : "blogs"} }
{ "body": "elasticsearch is rock solid"}
此时blogs索引里已经有一些文档了,可以进行下一步的探索。为帮助理解,我们先看看哪些term会存在于词典里。
将输入的文本分析一下(这步仅仅是看看ElasticSearch对他们的分词效果):
POST _analyze
{
"text": [
"Lucene is cool",
"Elasticsearch builds on top of lucene",
"Elasticsearch rocks",
"Elastic is the company behind ELK stack",
"elk rocks",
"elasticsearch is rock solid"
]
}
(由于结果太长,此处略去)
这些分出来的token都会成为词典里一个term,注意有些token会出现多次,因此在倒排索引里记录的词频会比较高,同时记录的还有这些token在原文档里的偏移量和相对位置信息。
执行一次suggester搜索看看效果:
POST /blogs/_search
{
"suggest": {
"my-suggestion": {
"text": "lucne rock",
"term": {
"suggest_mode": "missing",
"field": "body"
}
}
}
}
suggest就是一种特殊类型的搜索;DSL内部的"text"指的是api调用方提供的文本,也就是通常用户界面上用户输入的内容。这里的lucne是错误的拼写,模拟用户输入错误。- "
term"表示这是一个term suggester。; - "
field"指定suggester针对的字段; - 另外有一个可选的"
suggest_mode"。 范例里的"missing"实际上就是缺省值,它是什么意思?有点挠头… 还是先看看返回结果吧:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"hits": {
"total": 0,
"max_score": 0,
"hits":
},
"suggest": {
"my-suggestion": [
{
"text": "lucne",
"offset": 0,
"length": 5,
"options": [
{
"text": "lucene",
"score": 0.8,
"freq": 2
}
]
},
{
"text": "rock",
"offset": 6,
"length": 4,
"options":
}
]
}
}
在返回结果里"suggest" -> “my-suggestion“部分包含了一个数组,每个数组项对应从输入文本分解出来的token(存放在”text“这个key里)以及为该token提供的建议词项(存放在options数组里)。 示例里返回了”lucne”,"rock“这2个词的建议项(options),其中”rock“的options是空的,表示没有可以建议的选项,为什么? 上面提到了,我们为查询提供的suggest mode是”missing",由于"rock"在索引的词典里已经存在了,够精准,就不建议啦。 只有词典里找不到词,才会为其提供相似的选项。
如果将"suggest_mode“换成"popular"会是什么效果?
尝试一下,重新执行查询,返回结果里”rock"这个词的option不再是空的,而是建议为rocks。
"suggest": {
"my-suggestion": [
{
"text": "lucne",
"offset": 0,
"length": 5,
"options": [
{
"text": "lucene",
"score": 0.8,
"freq": 2
}
]
},
{
"text": "rock",
"offset": 6,
"length": 4,
"options": [
{
"text": "rocks",
"score": 0.75,
"freq": 2
}
]
}
]
}
回想一下,rock和rocks在索引词典里都是有的。 不难看出即使用户输入的token在索引的词典里已经有了,但是因为存在一个词频更高的相似项,这个相似项可能是更合适的,就被挑选到options里了。 最后还有一个"always" mode,其含义是不管token是否存在于索引词典里都要给出相似项。
有人可能会问,两个term的相似性是如何判断的? ES使用了一种叫做Levenstein edit distance的算法,其核心思想就是一个词改动多少个字符就可以和另外一个词一致。 Term suggester还有其他很多可选参数来控制这个相似性的模糊程度,这里就不一一赘述了。
Term suggester正如其名,只基于analyze过的单个term去提供建议,并不会考虑多个term之间的关系。API调用方只需为每个token挑选options里的词,组合在一起返回给用户前端即可。 那么有无更直接办法,API直接给出和用户输入文本相似的内容? 答案是有,这就要求助Phrase Suggester了。
Phrase suggester范例
Phrase suggester在Term suggester的基础上,会考量多个term之间的关系,比如是否同时出现在索引的原文里,相邻程度,以及词频等等。看个范例就比较容易明白了:
POST /blogs/_search
{
"suggest": {
"my-suggestion": {
"text": "lucne and elasticsear rock",
"phrase": {
"field": "body",
"highlight": {
"pre_tag": "",
"post_tag": ""
}
}
}
}
}
返回结果:
"suggest": {
"my-suggestion": [
{
"text": "lucne and elasticsear rock",
"offset": 0,
"length": 26,
"options": [
{
"text": "lucene and elasticsearch rock",
"highlighted": "lucene and elasticsearch rock",
"score": 0.004993905
},
{
"text": "lucne and elasticsearch rock",
"highlighted": "lucne and elasticsearch rock",
"score": 0.0033391973
},
{
"text": "lucene and elasticsear rock",
"highlighted": "lucene and elasticsear rock",
"score": 0.0029183894
}
]
}
]
}
options直接返回一个phrase列表,由于加了highlight选项,被替换的term会被高亮。因为lucene和elasticsearch曾经在同一条原文里出现过,同时替换2个term的可信度更高,所以打分较高,排在第一位返回。Phrase suggester有相当多的参数用于控制匹配的模糊程度,需要根据实际应用情况去挑选和调试。
最后来谈一下Completion Suggester
它主要针对的应用场景就是"Auto Completion"。 此场景下用户每输入一个字符的时候,就需要即时发送一次查询请求到后端查找匹配项,在用户输入速度较高的情况下对后端响应速度要求比较苛刻。因此实现上它和前面两个Suggester采用了不同的数据结构,索引并非通过倒排来完成,而是将analyze过的数据编码成FST和索引一起存放。对于一个open状态的索引,FST会被ES整个装载到内存里的,进行前缀查找速度极快。但是FST只能用于前缀查找,这也是Completion Suggester的局限所在。
为了使用Completion Suggester,字段的类型需要专门定义如下:
PUT /blogs_completion/
{
"mappings": {
"properties": {
"body": {
"type": "completion"
}
}
}
}
用bulk API索引点数据:
POST _bulk/?refresh=true
{ "index" : { "_index" : "blogs_completion"} }
{ "body": "Lucene is cool"}
{ "index" : { "_index" : "blogs_completion"} }
{ "body": "Elasticsearch builds on top of lucene"}
{ "index" : { "_index" : "blogs_completion"} }
{ "body": "Elasticsearch rocks"}
{ "index" : { "_index" : "blogs_completion"} }
{ "body": "Elastic is the company behind ELK stack"}
{ "index" : { "_index" : "blogs_completion"} }
{ "body": "the elk stack rocks"}
{ "index" : { "_index" : "blogs_completion"} }
{ "body": "elasticsearch is rock solid"}
查找:
POST blogs_completion/_search?pretty
{ "size": 0,
"suggest": {
"blog-suggest": {
"prefix": "elastic i",
"completion": {
"field": "body"
}
}
}
}
结果:
"suggest": {
"blog-suggest": [
{
"text": "elastic i",
"offset": 0,
"length": 9,
"options": [
{
"text": "Elastic is the company behind ELK stack",
"_index": "blogs_completion",
"_type": "tech",
"_id": "AVrXFyn-cpYmMpGqDdcd",
"_score": 1,
"_source": {
"body": "Elastic is the company behind ELK stack"
}
}
]
}
]
}
值得注意的一点是Completion Suggester在索引原始数据的时候也要经过analyze阶段,取决于选用的analyzer不同,某些词可能会被转换,某些词可能被去除,这些会影响FST编码结果,也会影响查找匹配的效果。
比如我们删除上面的索引,重新设置索引的mapping,将analyzer更改为"english":
PUT /blogs_completion/
{
"mappings": {
"properties": {
"body": {
"type": "completion",
"analyzer": "english"
}
}
}
}
bulk api索引同样的数据后,执行下面的查询:
POST blogs_completion/_search?pretty
{ "size": 0,
"suggest": {
"blog-suggest": {
"prefix": "elastic i",
"completion": {
"field": "body"
}
}
}
}
居然没有匹配结果了,多么费解! 原来我们用的english analyzer会剥离掉stop word,而is就是其中一个,被剥离掉了!
用analyze api测试一下:
POST _analyze?analyzer=english
{
"text": "elasticsearch is rock solid"
}
会发现只有3个token:
{
"tokens": [
{
"token": "elasticsearch",
"start_offset": 0,
"end_offset": 13,
"type": "" ,
"position": 0
},
{
"token": "rock",
"start_offset": 17,
"end_offset": 21,
"type": "" ,
"position": 2
},
{
"token": "solid",
"start_offset": 22,
"end_offset": 27,
"type": "" ,
"position": 3
}
]
}
FST只编码了这3个token,并且默认的还会记录他们在文档中的位置和分隔符。 用户输入"elastic i“进行查找的时候,输入被分解成”elastic“和”i",FST没有编码这个“i” , 匹配失败。
好吧,如果你现在还足够清醒的话,试一下搜索"elastic is",会发现又有结果,why? 因为这次输入的text经过english analyzer的时候is也被剥离了,只需在FST里查询"elastic"这个前缀,自然就可以匹配到了。
其他能影响completion suggester结果的,还有诸如"preserve_separators","preserve_position_increments“等等mapping参数来控制匹配的模糊程度。以及搜索时可以选用Fuzzy Queries,使得上面例子里的”elastic i"在使用english analyzer的情况下依然可以匹配到结果。
因此用好Completion Sugester并不是一件容易的事,实际应用开发过程中,需要根据数据特性和业务需要,灵活搭配analyzer和mapping参数,反复调试才可能获得理想的补全效果。
回到篇首Google搜索框的补全/纠错功能,如果用ES怎么实现呢?我能想到的一个的实现方式:
- 在用户刚开始输入的过程中,使用
Completion Suggester进行关键词前缀匹配,刚开始匹配项会比较多,随着用户输入字符增多,匹配项越来越少。如果用户输入比较精准,可能Completion Suggester的结果已经够好,用户已经可以看到理想的备选项了。 - 如果
Completion Suggester已经到了零匹配,那么可以猜测是否用户有输入错误,这时候可以尝试一下Phrase Suggester。 - 如果
Phrase Suggester没有找到任何option,开始尝试term Suggester。
精准程度上(Precision)看: Completion > Phrase > term, 而召回率上(Recall)则反之。从性能上看,Completion Suggester是最快的,如果能满足业务需求,只用Completion Suggester做前缀匹配是最理想的。
Phrase和Term由于是做倒排索引的搜索,相比较而言性能应该要低不少,应尽量控制suggester用到的索引的数据量,最理想的状况是经过一定时间预热后,索引可以全量map到内存。