【目标检测】YOLO v1 (You Only Look Once) 详细解读
对应论文:《You Only Look Once: Unified, Real-Time Object Detection》
[unofficial code - tensorflow]: https://github.com/hizhangp/yolo_tensorflow
YOLO(You Only Look Once),由 R.Joseph 等人在 2015 提出,是 YOLO 系列的 开山之作,也是 深度学习领域第一个 one-stage detector。它速度极快,在VOC上保证 mAP=52.7% 时能跑到 155fps。
作为一个 one-stage 检测器,YOLO 没有生成建议框这一步骤,它 直接将图片划分为 S×S 个网格 (grid cell),每个网格对 中心点落入其中的目标 进行检测【如果目标的中心点落入某个格子中,我们就说这个格子 “包含” 了这个目标,就由这个格子负责对这个目标的检测】。
YOLO 进行目标检测是 端到端 (end-to-end) 的,直接从输入到输出,一步到位,没有中间步骤。而且,YOLO 的训练也是端到端的。
通常对于一个目标,它落在哪个网格里是很清楚的,网络只需要对它做出一个 bounding box 预测即可,但有时有一些 大的目标 或者 处在在多个网格边界处的目标 可能会被多个网络同时检测,这个我们则可以通过非极大值抑制算法(NMS)对重叠框进行剔除。

方法介绍
网络结构
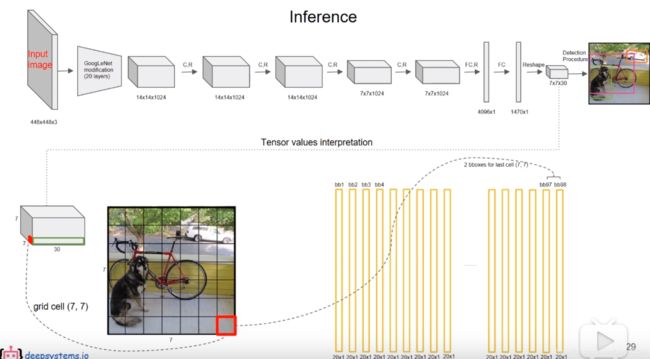
YOLO v1 的网络结构如图所示:

借鉴了 GoogLeNet ,网络包含 24个卷积层(用来提取特征)和 2个全连接层(用来预测)。
- 使用1×1卷积来做 channle reduction (通道方向上的降维),然后紧跟3×3卷积。
- 对于卷积层和全连接层,采用 Leaky ReLU 激活函数【最后一层输出层除外,采用线性激活函数】。
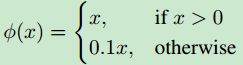
除了上面这个网络结构,文章还提出了一个 轻量级版本 Fast Yolo,仅使用9个卷积层,并且卷积层中使用更少的卷积核。
网络输出
YOLO v1 使用7×7个网格,每个网格给出两个 bounding box 的预测 (x, y, w, h, confidence score 五个参数),以及该网格属于20个类别的条件类别概率 (conditional class probabilities)。
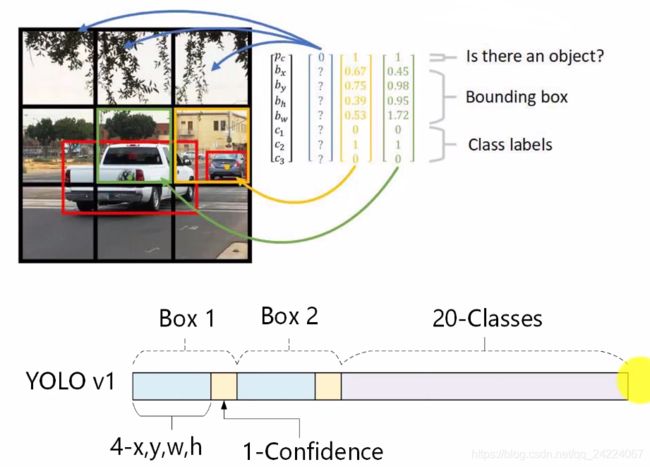
bounding box坐标 (x,y,w,h)
每个 bounding box 的位置由 (x, y, w, h) 四个变量唯一确定,其中:
- x, y 为 bounding box 中心 相对于 当前网格的左上角的 偏移量(offset),范围在0到1之间;
- w, h 使用整张图像的宽高进行归一化,范围也在0到1之间。
置信度得分 (confidence score)
每个 bounding box 有一个置信度得分。置信度得分是 bounding box 包含目标的可能性 以及 bounding box 定位的准确程度 的 综合反映。
定义为: P r ( o b j e c t ) ∗ I O U p r e d t r u t h Pr(object)*IOU_{pred}^{truth} Pr(object)∗IOUpredtruth
其中, P r ( o b j e c t ) Pr(object) Pr(object) 表示 bounding box是否包含目标。
- 若网格中不包含目标,即 P r ( o b j e c t ) = 0 Pr(object)=0 Pr(object)=0,则置信度为0
- 若网格中包含目标,即 P r ( o b j e c t ) = 1 Pr(object)=1 Pr(object)=1,则置信度等于预测的 bounding box 和 ground truth 的 IoU。
条件类别概率(conditional class probabilities)
每个 grid cell 有 C 个条件类别概率,即 P r ( C l a s s i ∣ O b j e c t ) Pr(Class_i|Object) Pr(Classi∣Object),表示一个 grid cell 在包含 object 的条件下属于某个类别的概率【只有在 grid cell 包含 object 情况下才进行类别预测】。
在测试阶段,将 条件类别概率 和 置信度相乘,得到 bounding box 针对 特定类别 的 类别置信度得分【即 bounding box 分类得分和定位得分 的 综合反映】。

P.S:注意,条件类别概率是针对grid cell的,confidence score是针对bounding box的。
思考
1、YOLO 将图像划分网格进行预测,每个网格单元的尺寸很有限,为何能够检测比网格大很多的物体 (比如某个物体占了十几个网格)?
YOLO 并不是将图片分割成 单独的独立的 网格 分别 输入模型进行预测,实际上,YOLO 网络最后的卷积层在原图上的感受野是远大于网格大小的,网格只是用于物体中心位置归属哪个网格的划分。
网络预测流程
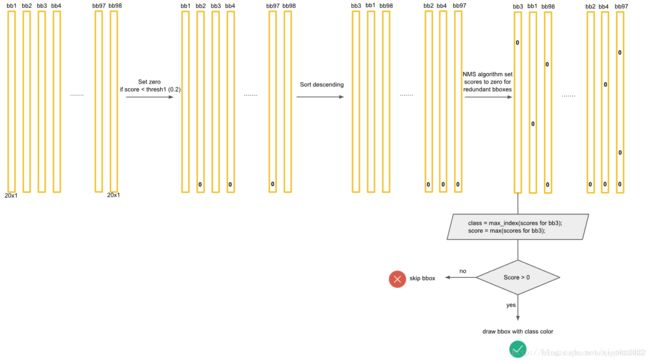
1、输入448×448×3的图片,网络输出7×7×30的张量,对应49个网格,每个网格给出 2个bounding box的预测,以及20个类别的条件类别概率

2、将 每个 bounding box 的置信度 和 其所属 grid cell 的条件类别概率 相乘,得到 每个 bounding box 的类别置信度【20×98的矩阵】
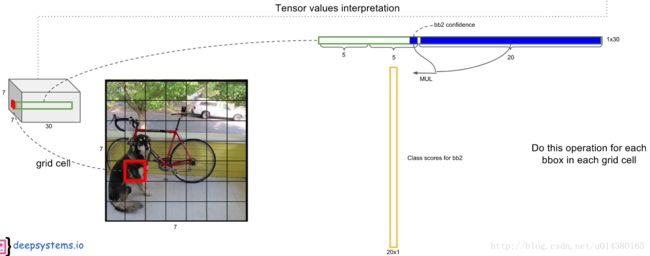
3、对20个类别(即每一行)分别进行以下操作:
- 先剔除(置0)得分小于阈值【这里取0.2】的 bounding box

- 按得分从高到低排序,利用 NMS 剔除(置0)重叠的bounding box
4、最后,对每个 bounding box(即每一列) 的20个 score 取最大值作为 bounding box 的 score,将最大值对应的类别作为 bounding box 的类别。
- 如果最大值大于0,则输出
- 如果最大值等于0,则将这个 bounding box 忽略。
思考
1、为什么不先对 grid cell 根据最大的条件类别概率确定类别,从而确定直接其对应的两个 bounding box 的类别,再进行NMS?反正最后也是要对bounding box的类别概率取最大,这不是一样吗?这样不是可以节省许多没必要的比较操作?
网络训练(training)
1、CNN网络预训练 (pretrained network)
首先在 ImageNet 上对 CNN网络 进行预训练,预训练的分类模型采用上图中的 前20个卷积层,接一个 average-pooling层 和 全连接层。
2、特定域下的网络微调 (domain-specific fine-tuning)
模型结构调整
- 在预训练网络的前20层卷积层上加上 随机初始化的4个卷积层和2个全连接层。
由于检测任务一般需要更高清的图片,所以 将网络的输入从224x224增加到了448x448。
训练损失函数
YOLO 的训练是端到端的,所有东西 放到一起训练。
损失函数包括三个部分:
- ① coordinate error (coordError, 位置相关误差,即定位的误差)
- ② iouError (IOU误差,即置信度的误差)
- ③ classification error (classError, 分类误差)。
Yolo算法将目标检测看成回归问题,所以作者 简单粗暴的全部采用了均方差损失函数(sum-squared error loss) 【YOLO v1将类别预测也看成了回归问题,用的MSE= =】。
具体损失函数如下,

为了让各损失项得到平衡,采用了不同的权重值:
对于定位误差项:
- 8维的 localization error 和20维的 classification error 对网络loss的贡献值是不同的,使用λcoord = 5 进行修正。
- 此外,相同的bbox误差,对大bbox的影响会小于小bbox的影响【小bbox对误差更敏感,对大bbox而言只是一点点的变化,对小bbox来讲就很巨大了】。我们希望对给小bbox的误差引入更大的惩罚,对所以将对 w w w和 h h h求平方根来改进这个问题【事实上这个方法并不能完全解决这个问题】。
- I i j o b j \mathbb{I}_{ij}^{obj} Iijobj ,表示第 i i i个格子的第 j j j个bounding box“包含”目标时,才计算定位误差【不然定位输出没有意义】
对于IOU误差(置信度误差):
- 考虑到很多grid cell不包含目标,直接将置信度push到0,这对于较少的包含目标的grid cell的置信度预测会造成很大的打压,所以采用使用 λ n o o b j = 0.5 λ_{noobj}= 0.5 λnoobj=0.5 进行修正。
- I i j o b j \mathbb{I}_{ij}^{obj} Iijobj 和 I i j n o o b j \mathbb{I}_{ij}^{noobj} Iijnoobj 对“包含”目标的box和不包含目标的box进行区分
对于分类误差:
- I i o b j \mathbb{I}_{i}^{obj} Iiobj 表示只有当一个单元格内确实存在目标时,才计算分类误差项。
思考
1、如果一个单元格内存在多个目标怎么办?
此时Yolo v1就只能选择其中一个来训练,这也是v1的缺点之一。
YOLO v1的优点与不足
优点:
- 快。YOLO将物体检测作为回归问题进行求解,整个检测网络pipeline简单。在titan x GPU上,在保证检测准确率的前提下(63.4% mAP,VOC 2007 test set),可以达到45fps的检测速度。
- 背景误检率低。YOLO在训练和推理过程中能‘看到’整张图像的整体信息【用了全连接层】,而基于region proposal的物体检测方法(如rcnn/fast rcnn),在检测过程中,只‘看到’候选框内的局部图像信息。因此,若当图像背景(非物体)中的部分数据被包含在候选框中送入检测网络进行检测时,容易被误检测成物体。测试证明,YOLO对于背景图像的误检率低于fast rcnn误检率的一半。
- 通用性强。YOLO对于艺术类作品中的物体检测同样适用。它对非自然图像物体的检测率远远高于DPM和RCNN系列检测方法。
局限:
- 由于 YOLO v1 中采用了全连接层,全连接层的输入大小是固定的,所以只能测试固定大小的输入图像
- 对小物体检测不敏感。因为虽然每个cell都可以预测出B个bounding box,但是在最终只选择IOU最高的bounding box作为物体检测输出,即:每个cell只能预测出一个物体。当物体较小时,所占画面比例较小,比如图像中包含牲畜群的时候,每个网格包含多个物体,但是最后只能检测出其中的一个。
- YOLO方法模型训练依赖于物体识别标注数据,因此,对于非常规的物体形状或比例,YOLO的检测效果并不理想。
- YOLO采用了多个下采样层,网络学到的物体特征并不精细,因此也会影响检测效果。
- YOLO loss函数中,大物体IOU误差和小物体IOU误差对网络训练中loss贡献值接近(虽然采用求平方根方式,但没有根本解决问题)。因此,对于小物体,小的IOU误差也会对网络优化过程造成很大的影响,从而降低了物体检测的定位准确性。
[1] YOLO目标检测中损失函数loss的理解及部分代码实现
[2] YOLO(You Only Look Once)算法详解
视频资料:
[1] CVPR2016 作者详细讲解YOLO (目标检测 深度学习) 视频
[2] YOLO v1深度解读 视频
PPT:
YOLO v1幻灯片