施主分享随缘,评论随心,@author:白袍小道
小道暗语:
1、因为小道这里博客目录没自己整,暂时就用随笔目录结构,所以二级目录那啥就忽略了。标题格式大致都是(原or转) 二级目录 (标题)
2、因为所看和以前记录太过杂乱,所以只能手动一点点搬移(回忆,整理)。欢迎讨论,知识和能力总是被问出来了不是(嘿嘿,这样才能成长), 若有不对别喷就好哈哈。
引言:
文章四方面包括了从游戏线程、渲染线程、GPU、内存等的优化,提升游戏技术底子。
原作者:王祢,Epic Games 资深开发者技术支持,管理虚幻引擎技术支持的程序员团队,拥有近15年虚幻引擎使用经验。
正文:
优化肯定是有个前提和需求背景的,本文的前提:在移动设备上做大地型的多人游戏。
需求背景:
1、开放地图:视野宽,视距远,地图大
2、场景:风格变化多
3、同屏人不少
4、交互也不少
(看到这里对吧,UE +上述 就直接说堡垒之夜就好了呗)
(由于篇幅较长,小道就直接拆开了,各位看官)
一、游戏线程的优化

(重要度管理,这个东西提出挺不错)
1、重要度管理Significance Manager
|
|
例子LOD: |
结论:重要度管理(可以自己整一个Manager,再在Manager下划分多个Manager,实现Iman)
的引入
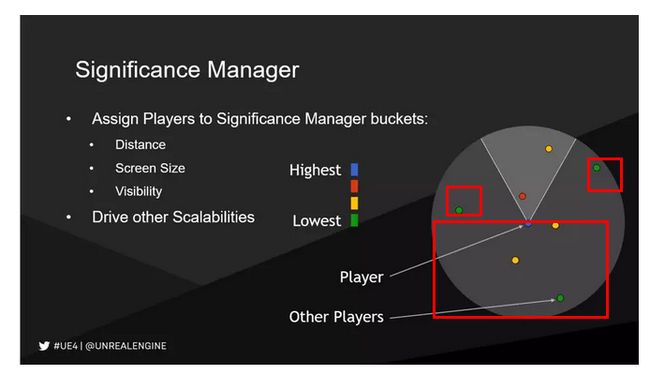
原文:
我们怎么样让各个游戏模块从游戏逻辑层去修正LOD的计算?这时我们引入Significance Manager,我们会分配针对每个平台的 Bucket,大家可以看到右下示意图中蓝色的小点代表玩家控制的角色,边上的小点是别的玩家和交互的动态对象。我们根据离主角玩家的距离,在屏幕上的尺寸或者可见性,决定使用什么Bucket。例如基于可见性的计算,虽然离我很近,但是因为在我的背后,可能很多时候我都感受不到,Bucket就可以分得不一样,通过Bucket我们会用来控制、修正LOD的各种计算。
这里是一个例子,我们这个系统本身用于我们自己比较火热的游戏《堡垒之夜》它在手机、掌机、电脑都可以跑,我们兼容所有的平台可以连机玩,游戏在不同平台上的场景、复杂程度其实是一样的。这种情况下,硬件的计算能力有非常大的差别,所以我们针对移动平台和主机Bucket也不一样,除了自身控制的角色给的Bucket比较高,剩下的角色的比较低,主机有四个,手机有一个,这个设置不仅按平台来,也可以按设备来,移动设备好的和差的硬件计算能力差很多,我们可以在Device profile指定当前这台设备Bucket的规划。
刚才是比较全局的系统,接下来我们看游戏线程里开销最大的部分就是我们的动画,动画系统大部分角色是可以定制的,角色会分为几个部分,绘制调用的数量、动画骨骼更新、不同部件的不同动画计算量非常大,针对Fortnite这样的游戏有一些特殊的游戏模式,例如50V50,这种情况下,最终在缩圈以后,同屏会出现超过50甚至80个角色,每个角色还分了好几个部件,背包、武器都有不同的动画,这个时候计算量非常大,我们需要对动画做非常大量的优化。
2、动画

刚刚我们已经说到角色可能分为几个部分,有一些不同的策略,引擎提供各种方式,一种是将不同的部位的Mesh合成为一个,这个模型有一个问题,材质是要合并起来的,你的表情的动画就没有了,在这个方案上我们做了一些取舍,最终决定不在Fortnite用这种方式。
另一种,身上不需要动画的刚体挂件可以方便的挂在角色骨骼的Socket上面,这是比较简单的方式。还有Master-Slave的方式,主体动画是一套完整的骨骼,身上挂载的动画是这个骨骼的子支,这个时候我们可以把这些挂载的部件的动画完全跳过自己的动画更新计算,完全用Master驱动。这样的骨骼动画直接使用Master的骨骼矩阵,没有办法扩展,比如Master Skeleton没有尾巴或是披风的骨骼,尾巴或是披风的独立动画或者物理模拟就没办法做。针对这种情况,我们还有一个解决方案是Copy Pose,可以把主体的计算完的骨骼矩阵拷贝给附属的骨骼矩阵,只要保持目标骨骼和原骨骼的层级结构一致,就可以在目标骨骼上增加扩展性的骨骼,可以根据自己的状态播自己的动画,也可以模拟物理。
四种多部件角色setup的方案,无论使用哪一种,都需要对骨骼模型和骨架设置LOD,这是下面提到多种优化的前提。
2.1 |
Event Graph |
在动画更新的时候会有大量的逻辑事件的计算,我们称之为Event Graph,这是UE4提供的图形化的脚本功能,Event Graph是需要经过图形化的脚本虚拟机,这个调用在动画逻辑比较复杂的时候开销有点高,我们把在虚拟机上计算的Event Grape转到C++,省掉了大量开销。
2.2 |
Anim Graph |
我们根据当前的状态选择不同的骨骼层级,播放哪个动画,或是经过哪些骨骼控制节点,比如说IK、物理模拟最终的POSE的计算
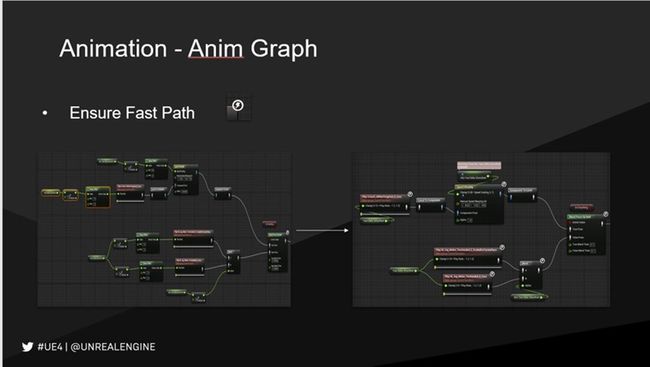
在这个计算中间有一些步骤会用到数学计算,因为是在Graph,会有一些额外的开销。我们做了一些优化,我们把所有这些独立计算的模块通通纳入到一些基础的骨骼动画混合节点,包括偏移和缩放,这样可以减少虚拟机的调用开销,我们把这些包含简单计算项的动画混合节点叫做Fast Path节点(右上角有闪电小图标),骨骼混合的计算逻辑通通是用Fast Path可以完全消除在虚拟机上的开销。
同屏有那么多的角色要做骨骼动画计算,大家知道移动设备是多核设备,为了更好的利用多核的定性,我们需要把刚刚这种虚拟机上的调用更好的平摊到不同的线程。基于上面两个优化方向,我们不要使用Event Graph,把游戏逻辑更新的部分放在AnimInstanceProxy上,这样引擎会自动判断这个Event Graph是不是可以放在别的线程上更新。如果你用了Fast Path,我们就可以把骨骼的update和evaluation都放到working thread上面去,例如有50个角色,在任意一角色更新开始,就把计算分到别的线程上面,主线程继续往下走。
即使我们能利用多线程,计算量还是非常大的,我们要减少动画更新的数据量,已经有些设置可以帮助动画在不渲染的时候跳过 Tick pose,也可以通过Singnificance Manager跳过附属武器、背包的更新,除了自己的主角,别的角色离你远一些,信息不更新其实你是注意不到的。
我们的掉落物会模拟物理,是骨骼物体。骨骼计算有一个问题,是走的Dynamic Path。我们引擎的中的静态对象,会在加到场景中的时候就直接排序分组到自己的Drawing Policy,绘制的时候可以很大程度减少渲染状态的切换。而动态的单位,是每一帧在渲染开始的InitViews阶段动态获取到数据,它和静态获取数据的方式不一样,不会进入到静态排序的表里,绘制的效率比较低。针对这种实际每一帧渲染数据不发生变化的骨骼物体,我们把这些物体额外加到了一个StaticRenderPath,加速了这些物体的渲染。(这里可以跳Unreal搬山)
2.3 |
URO(Update Rate Optimization) |
URO(Update Rate Optimization),我们其实没有必要对所有的角色在每一帧都做骨骼计算(频率看着办,公开吧)

比如画面中一个角色的POSE上半身动作是怎么样,下半身动作是怎么样,是否需要融合,什么频率融合,中间是不是要插值,这些设置可以非常大程度决定骨骼更新的计算量。大家可以看到下面的图,左一是每一幀都更新,左边二是每四幀更新一次,中间用插值,第三张图是每十幀更新一次,中间用插值,最后一张图是每四幀更新一次,不用插值(跳跳)。大家可以看到当角色占屏面积比较小,离得比较远的时候其实是没有大差别的。
刚才讲的这些是针对骨骼动画更新的优化,其实伴随着骨骼LOD的设置,我们在AnimGraph中可以设置骨骼控制节点从某一级LOD下不计算,比如说IK、物理模拟。
3、Scene Component
游戏线程还有大量的Scene Component,Scene Component是指世界中有坐标位置的对象,它的Transform更新都是在游戏线程中计算.

当你大地图、大场景动态更新对象非常多,同时每个对象身上会挂很多Scene Component的时候,计算量是非常大的。尽管我们会把Scene Component的计算踢到异步线程,但是计算量依然很大。我们做了一些改进,针对一些挂载在人物身上,不是处于激活状态的Scene Component做了自动的管理。
打开Auto Manage Attachment,对于音频和粒子特效,可以自动根据它是否激活的状态,决定是否挂在父级Scene Component。如果Detach掉,它的Transform就不会再更新。
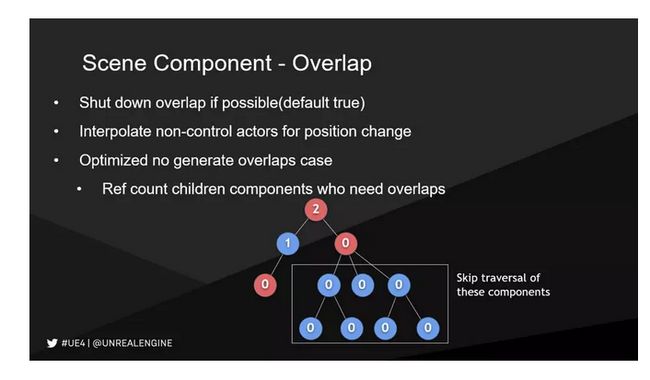
当Scene Component发生位置变化的时候会触发Overlap的检查,每一帧有大量运动对象时会产生大量Overlap事件,耗费比较大的开销。
优化的原则是尽可能把不需要产生Overlap的事件关掉,注意引擎默认是打开的。
我们对层级结构比较复杂的做了子Component是否打开overlap事件的引用计数,会看自己是不是打开了Overlap事件,以及自己的子对象有没有打开。这个时候我们在做Overlap检查的时候可以很快的跳过,这个节点往下都没有,就不需要再检查自己的子节点,这在场景的对象结构比较复杂的情况下是可观的优化。
4、Character Movement
( 小道说就注意一个检查这种逻辑若多的话,可以按重要度减少,再减少。单机游戏主角随意,对吧嘿嘿)(网络同步,特别VR上,需要同步的数据若可以插值尽量插值,简单粗暴效果也不差)

Character Movement,因为角色比较多,角色的移动更新是非常大的游戏线程的计算。针对这个计算,一部分是角色在移动的时候要检查新的位置是不是能站立,要做一些扫描,要做一些碰撞,还要找落脚点是不是斜坡,这个斜坡的斜率是不是角色可以站上的,往前走的高度变化是不是可以超过跨过阶梯最大的高度,角色一多计算量就非常大。所以除了玩家自己控制的角色,需要比较精确的计算外,其余角色分到的Significance Manager的Bucket我们最终是用了插值,通过网络同步过来的位置做简单的插值来模拟预测计算,在大部分时候都不容易注意到明显的差异,只有在帧数较低或者网络带宽受限比较严重的时候,对于落地点会有显著的偏差,大家可以对比看到这两个视频中左边是预测计算,右边是插值。
5、Physics
(物理是真实,但也会穿帮,一些程序麻烦点模拟模拟还是做的.前提还是重要度)
替代的Physics优化物理注册的对象

Physics,我们会尽可能的用一些替代的Physics优化物理注册的对象,有一组对象,比如说边界,不需要很细致的碰撞模型,我们可以用简单的volume来表达物理碰撞对象,减少注册到物理场景中的对象数量。物理的一个场景会有两个树,一个用以做Query,一个用于做Simulation,我们要尽可能保证注册进去的对象最优化。因此需要尽可能的简化每个物理对象的复杂度,以及减少整个场景注册的物理对象数。可以同时以比较小的内存开销打开异步的物理场景,Physics注册的对象是一样的,只不过他会用Shared Shape的方式加到Async Scene里,这样在场景做物理模拟的同时,他可以在异步的scene里做其他的query。
另外我还尝试过把同样mesh的不同实例对象用Shared shapes减少注册的物理对象的内存开销,在内存敏感的场景下也可以尝试。
还有一个思路是我们可以把物理对象和视觉对象解耦(就是碰的和看得丫的不是一个),默认的情况下,引擎的Mesh对象打开碰撞就会注册物理对象到PhysX Scene,增加了物理场景的复杂度和物理的内存占用。因此当你的Mesh加载到内存里,即使不被渲染出来,这些开销就在了,但是其实很多情况下视觉会看得更远一些,实际需要物理计算交互的距离在有些游戏中没那么远,我们可以用一些手段把视觉上对象的物理关掉,把这个物理属性转到一些新的Component和Actor上面放到新的Streaming Level里,用更近的加载卸载距离来管理,这样实际的物理场景复杂度和内存占用都会小很多。
另外移动端的布料,计算量和网格数量相关,在移动端会不太推荐使用那么复杂的模拟,引擎也就没有提供移动端的NvCloth的lib,所以我们一般会用刚体来模拟。
7、Ticking
XD关键词:
在蓝图事件卡上Tick更新,虚礼机调用开销。
Tick事件触发的执行队列

8、UI
多利用我们新出的SlatLayoutCaching和Invalidation Box来Cache Prepass减少widget transform更新的计算,这些Cache可以把计算的位置和大小记录下来,有一些可以把顶点Buffer Cache下来

另外,我们也需要尽量让UI的Widget可以Batching起来。引擎的一些布局空间会自动帮你布局子控件,例如Horizental和Vertical Box,Grid等,这时候子控件是在同一层(Layout)上,引擎会优先Batch起来。
当使用比较灵活的Canvas Panel时,会导致引擎默认的行为会把每个加入的子空间的Implicit Zorder自动增一,这时候如果你确定这些子Widget不重叠,其实可以手动控制这个ZOrder。当然Batch的前提还是你用了同样的材质和贴图。那么如果做一个背包界面,里有很多不同东西的图标,我们又希望这些图标有一些特效,我们可以用同一个材质,这只同一个Texture Altas,针对每个子控件设置不同的Vertex Color,在Vertex Shader里通过VC的值做为uv来使得这些子控件可以被Batching起来。
音频和特效,音频是比较大的开销,我们之前的堡垒之夜又是从主机到移动端兼容的项目,为了优化音频在移动端的开销,我们增加了做了很多设置,使得在移动端不同的设备可以设置不同的SoundCue并发的数量,以及SoundSource的数量。
其中SoundSource默认在移动端上总数是16个,主机上可能是32个。简单说明一下什么是SoundCue,这就是原始的SoundWave资源拿过来做一些实时处理封装后的音频资源,例如可以在多个SoundWave中做一些随机、拼接,以及一些声音效果的实时处理,这些处理效果对计算量要求比较大,我们可以针对不同的硬件设备做一些LOD的设置,比如说在比较差的CPU移动设备上,可以把Reverb,EQ等关掉,或者减少随机的Wave的数量等。
Particle比较显著的开销是Overdraw,我们在PC上有自动把贴图的Alpha切割出八面体,减少Overdraw的功能,但是这个功能之前在移动端无法使用,最近我发现其实只要支持SRV的设备,是完全可以用这个功能的,移动端上也可以打开。
(XD记下)另外,所有的半透也可以以独立的RenderPass以低分辨率绘制在upscale回来以减少overdraw带来的大量的fragment的开销。
9、关卡流
(异步,裁分)

10、Server
(丢包,Cache下来合并再发)
