Python时间序列分析
引入数据包
from __future__ import print_function
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
from statsmodels.graphics.api import qqplot
from statsmodels.graphics.tsaplots import plot_acf1.读取数据
# 参数初始化
discfile = '../data/arima_data.xls'
# 读取数据,指定日期列为指标,Pandas自动将“日期”列识别为Datetime格式
data = pd.read_excel(discfile,index_col=0)
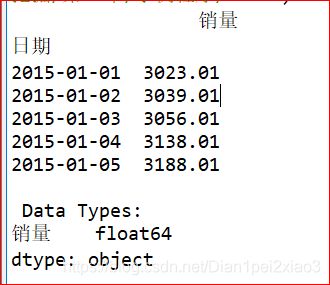
print(data.head())
print('\n Data Types:')
print(data.dtypes)
2.绘制时间序列图
# 时序图
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
data.plot(title="某餐厅厅的销量数据图示")
plt.show()
3.自相关性判断
#自相关图
plot_acf(data).show()
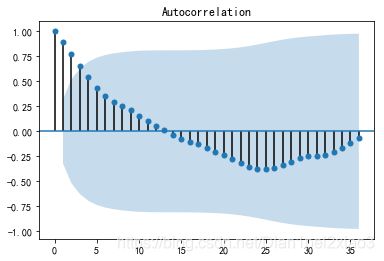
由自相关图可以看出,在4阶后才落入区间内 ,并且自相关系数长期大于零,显示出很强的自相关性。
4.平稳性检验
#平稳性检测
from statsmodels.tsa.stattools import adfuller as ADF
print(u'原始序列的ADF检验结果为:', ADF(data[u'销量']))
#返回值依次为adf、pvalue、usedlag、nobs、critical values、icbest、regresults、resstore原始序列的ADF检验结果为: (1.8137710150945272, 0.9983759421514264, 10, 26, {'10%': -2.6300945562130176, '5%': -2.981246804733728, '1%': -3.7112123008648155}, 299.46989866024177)
从返回的结果看p=0.9983>0.05,判断该序列为非平稳序列。
5.时间序列的差分d
#差分后的时序图
D_data = data.diff().dropna()
D_data.columns = [u'销量差分']
D_data.plot(title="差分后的时序图") #时序图
plt.show()
对差分后的序列做自相关检验和偏相关检验:
#自相关图
plot_acf(D_data).show()
#偏自相关图
from statsmodels.graphics.tsaplots import plot_pacf
plot_pacf(D_data).show() 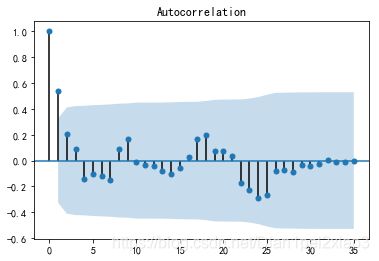
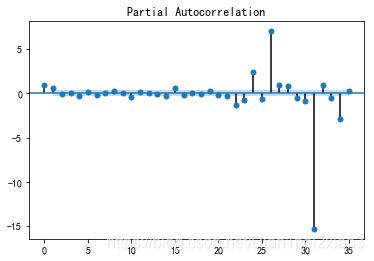
由上面左图可以看出,对于差分后的序列迅速落入区间内,并呈现出向0靠拢的趋势,序列没有自相关性。右图展示的差分后的偏自相关图,也没有显示出偏自相关性。
对差分后的序列做平稳性检测 :
#平稳性检测
print(u'差分序列的ADF检验结果为:', ADF(D_data[u'销量差分'])) 差分序列的ADF检验结果为: (-3.1560562366723537, 0.022673435440048798, 0, 35, {'10%': -2.6130173469387756, '5%': -2.9485102040816327, '1%': -3.6327426647230316}, 287.5909090780334)
p=0.0226<0.05 ,说明一阶差分后是平稳序列。
对差分后的序列做噪声检验:
#白噪声检验
from statsmodels.stats.diagnostic import acorr_ljungbox
print(u'差分序列的白噪声检验结果为:', acorr_ljungbox(D_data, lags=1))
#返回统计量和p值 差分序列的白噪声检验结果为: (array([11.30402222]), array([0.00077339]))
p=0.000773<0.05,说明 该序列为 白噪声序列。
比较一阶差分和二阶差分后的序列:
# 一阶差分
fig = plt.figure()
ax1= fig.add_subplot(111)
diff1 = data.diff(1)
diff1.plot(ax=ax1,title="一阶差分后的序列")
# 二阶差分
fig = plt.figure()
ax2= fig.add_subplot(111)
diff2 = data.diff(2)
diff2.plot(ax=ax2,title="二阶差分后的序列")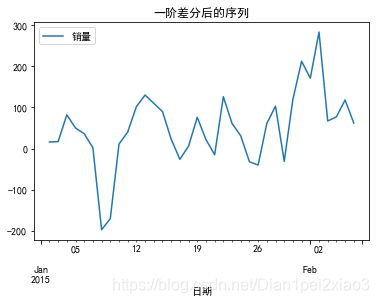

可以看出一阶差分和二阶差分后的时间序列相差不大,并且二者随着时间推移,时间序列的均值和方差保持不变。因此可以将差分次数d设置为1.
6.选择合适的p,q
现在我们已经得到一个平稳的时间序列,接下来就是选择合适的ARIMA模型,即ARIMA模型中合适的p,q.
第一步我们先要检查平稳时间序列的自相关和偏相关图。
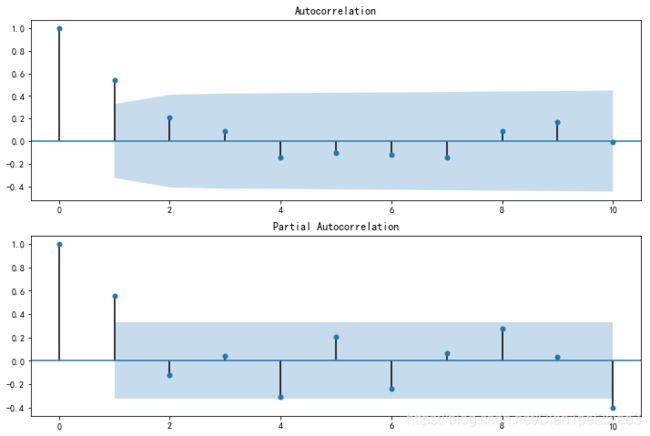
通过两图观察得到:
1).自相关图显示滞后有两个阶超出了置信边界。
2)偏相关图显示在滞后1阶时的偏自相关系数超出了置信边界,从 lag 1之后偏自相关系数值缩小至0;
则有以下模型可以供选择 :ARIMA(p,d,q)
1) ARMA(0,2) 模型:即自相关图在滞后2阶之后缩小为0,且偏自相关缩小至0,则是一个阶数q=2的移动模型。
2)ARMA(1,0)模型:即偏自相关图在滞后1阶之后缩小为0,且自相关缩小至0,则是一个阶数p=1的自回归模型。
3)ARMA(0,1)模型:即自相关图在滞后1阶之后缩小为0,且偏自相关缩小至0,则是一个阶数q=1的自回归模型。
#模型
arma_mod20 = sm.tsa.ARMA(dta,(2,0)).fit()
print(arma_mod20.aic,arma_mod20.bic,arma_mod20.hqic)
arma_mod01 = sm.tsa.ARMA(dta,(0,1)).fit()
print(arma_mod01.aic,arma_mod01.bic,arma_mod01.hqic)
arma_mod10 = sm.tsa.ARMA(dta,(1,0)).fit()
print(arma_mod10.aic,arma_mod10.bic,arma_mod10.hqic)#残差QQ图
resid = arma_mod01.resid
fig = plt.figure(figsize=(12,8))
ax = fig.add_subplot(111)
fig = qqplot(resid, line='q', ax=ax, fit=True)
#残差自相关检验
fig = plt.figure(figsize=(12,8))
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(arma_mod01.resid.values.squeeze(), lags=10, ax=ax1)
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(arma_mod01.resid, lags=10, ax=ax2)
#D-W检验
print(sm.stats.durbin_watson(arma_mod01.resid.values))# Ljung-Box检验
import numpy as np
r,q,p = sm.tsa.acf(resid.values.squeeze(), qstat=True)
datap = np.c_[range(1,36), r[1:], q, p]
table = pd.DataFrame(datap, columns=['lag', "AC", "Q", "Prob(>Q)"])
print(table.set_index('lag'))#预测
predict_sunspots = arma_mod01.predict('2015-2-07', '2015-2-15', dynamic=True)
fig, ax = plt.subplots(figsize=(12, 8))
print(predict_sunspots)
predict_sunspots[0] += data['2015-02-06':][u'销量']
data=pd.DataFrame(data)
for i in range(len(predict_sunspots)-1):
predict_sunspots[i+1]=predict_sunspots[i]+predict_sunspots[i+1]
print(predict_sunspots)
ax = data.ix['2015':].plot(ax=ax)
predict_sunspots.plot(ax=ax)
plt.show()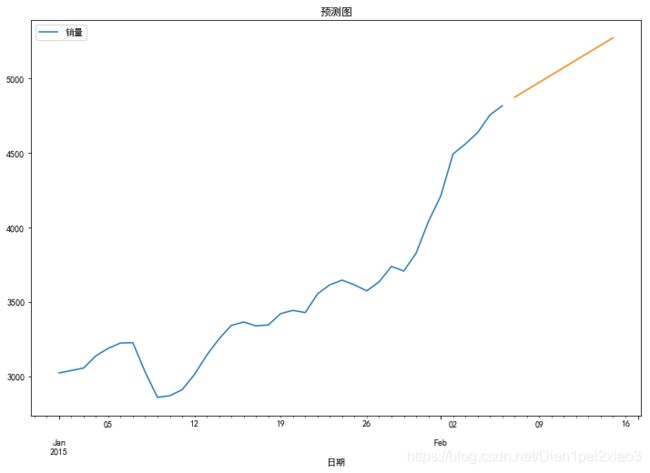
整个代码:
from __future__ import print_function
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
from statsmodels.graphics.api import qqplot
from statsmodels.graphics.tsaplots import plot_acf
# 参数初始化
discfile = '../data/arima_data.xls'
# 读取数据,指定日期列为指标,Pandas自动将“日期”列识别为Datetime格式
data = pd.read_excel(discfile,index_col=0)
print(data.head())
print('\n Data Types:')
print(data.dtypes)
# 时序图
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
data.plot(title="某餐厅厅的销量数据图示")
plt.show()
#自相关图
plot_acf(data).show()
#平稳性检测
from statsmodels.tsa.stattools import adfuller as ADF
print(u'原始序列的ADF检验结果为:', ADF(data[u'销量']))
#返回值依次为adf、pvalue、usedlag、nobs、critical values、icbest、regresults、resstore
#差分后的时序图
D_data = data.diff().dropna()
D_data.columns = [u'销量差分']
D_data.plot(title="差分后的时序图") #时序图
plt.show()
#自相关图
plot_acf(D_data).show()
#偏自相关图
from statsmodels.graphics.tsaplots import plot_pacf
plot_pacf(D_data).show()
#平稳性检测
print(u'差分序列的ADF检验结果为:', ADF(D_data[u'销量差分']))
#白噪声检验
from statsmodels.stats.diagnostic import acorr_ljungbox
print(u'差分序列的白噪声检验结果为:', acorr_ljungbox(D_data, lags=1))
#返回统计量和p值
#
# 一阶差分
fig = plt.figure()
ax1= fig.add_subplot(111)
diff1 = data.diff(1)
diff1.plot(ax=ax1,title="一阶差分后的序列")
# 二阶差分
fig = plt.figure()
ax2= fig.add_subplot(111)
diff2 = data.diff(2)
diff2.plot(ax=ax2,title="二阶差分后的序列")
# 合适的p,q
dta = data.diff(1)[1:]
fig = plt.figure(figsize=(12,8))
ax1=fig.add_subplot(211)
fig1 = sm.graphics.tsa.plot_acf(dta[u'销量'],lags=10,ax=ax1)
ax2 = fig.add_subplot(212)
fig2 = sm.graphics.tsa.plot_pacf(dta[u'销量'],lags=10,ax=ax2)
#模型
arma_mod20 = sm.tsa.ARMA(dta,(2,0)).fit()
print(arma_mod20.aic,arma_mod20.bic,arma_mod20.hqic)
arma_mod01 = sm.tsa.ARMA(dta,(0,1)).fit()
print(arma_mod01.aic,arma_mod01.bic,arma_mod01.hqic)
arma_mod10 = sm.tsa.ARMA(dta,(1,0)).fit()
print(arma_mod10.aic,arma_mod10.bic,arma_mod10.hqic)
#残差QQ图
resid = arma_mod01.resid
fig = plt.figure(figsize=(12,8))
ax = fig.add_subplot(111)
fig = qqplot(resid, line='q', ax=ax, fit=True)
#残差自相关检验
fig = plt.figure(figsize=(12,8))
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(arma_mod01.resid.values.squeeze(), lags=10, ax=ax1)
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(arma_mod01.resid, lags=10, ax=ax2)
#D-W检验
print(sm.stats.durbin_watson(arma_mod01.resid.values))
# Ljung-Box检验
import numpy as np
r,q,p = sm.tsa.acf(resid.values.squeeze(), qstat=True)
datap = np.c_[range(1,36), r[1:], q, p]
table = pd.DataFrame(datap, columns=['lag', "AC", "Q", "Prob(>Q)"])
print(table.set_index('lag'))
#预测
predict_sunspots = arma_mod01.predict('2015-2-07', '2015-2-15', dynamic=True)
fig, ax = plt.subplots(figsize=(12, 8))
print(predict_sunspots)
predict_sunspots[0] += data['2015-02-06':][u'销量']
data=pd.DataFrame(data)
for i in range(len(predict_sunspots)-1):
predict_sunspots[i+1]=predict_sunspots[i]+predict_sunspots[i+1]
print(predict_sunspots)
ax = data.ix['2015':].plot(ax=ax)
predict_sunspots.plot(ax=ax,title="预测图")
plt.show()