论文笔记 Unsupervised Extraction of Video Highlights Via Robust Recurrent Auto-encoders
本文提出了一个视频精彩片段检测算法
之前的精彩视频剪辑的方法常用的是处于监督学习或者启发式规则下,本文采用的无监督学习的方法,同时也借助到Youtube上各种各样的用户剪辑过的视频用于训练,同时作者考虑到在用户剪辑过的视频中,精彩部分出现的频率和时长肯定会大于不是那么精彩部分出现的时长。
视频的highlights存在着三个巨大的挑战,第一个是尽管大部分人对于highlight有着相同的概念但是出于主观因素还是会存在不同点;第二个是在数据的收集上,如果再youtube上输入GoPro surfing会存在着噪声数据;第三点就是除了搜索到的视频信息没有其他信息是可用的。也不同于监督学习,我们的视频数据中没有对于highlight和非highlights的定义。
这篇文章提出了两个motivations
第一个是对于同一类型的许多video,highlights在这些video中必定是频繁出现的,同时如果视频是用户上传并剪辑过的视频,那么highlights的画面出现的必定更加的频繁,因此可以认为在同一类型的video中存在着相似性。
第二个是作者提出了一个models建立在a robust recurrent auto-encoder with a shrinking exponential loss function and bidirectional LSTM cells ,同时对于video的highlight的detection采用非监督学习的方法,这样能够充分利用网络上短视频的多样性。
Auto-Encoder-Based Removal of Outliers
作者这里建立了一个Encoder用于移除输入数据中的噪声,即将输入视频中异常的视频移除出数据集。这里设计的自动编码器也是一个神经网络能够重建输入的数据,同时重建后的数据就表示为原数据的压缩形式。
Encoder实现的方法就是用含有一个隐藏层的神经网络进行reconstruction.
首先从输入层映射到隐藏层,s为激活函数,w,b为可以学习参数,w维度为d’*d,b是一个bias vector.
.![]()
第二层也是相同的方式映射到输出层,
![]()
因此最后的输出Y就是 ;
需要注意的是输出层的节点数目和输入节点的数目是相同的。
这里的损失函数是,我们需要优化θ和θ’即该神经网络的参数。损失函数用到了平方损失。

系统的整理过程有
Acquisition of Training Data:该方法就是在Youtube上用keyword搜索相关的视频,比如所搜“gopro surfing”就可以找到相关的视频,同时这些视频的highlight中都存在着一点的相似性,收集好数据之后就可以通过auto-encoder进行预处理模型的训练
Temporal Segmentation:进行视频的时序上的切割,保证每一段都在48-96的帧数
Feature Representation:通过C3D的方式提取视频的特征(16 input frames)
Unsupervised Learning:这里作者提出本文使用的是无监督学习,并不是多样例学习的弱监督方式,(因为:Since a video does not necessarily contain at least one highlight snippet, such as when the video is actually unrelated to the keyword, the bag and instance relationship is hard to define.)
下图是训练过程图:

Robust Autoencoder Via Shrinking Exponential Loss
为了减少网上视频数据中存在的负样本,作者使用了一个方法来减少负样本对损失函数的影响

同时作者考虑到在训练一开始所有的数据形成的损失都很大,但是随着训练的进行,负样本对损失函数的影响越来越大,因此λ的数值在一开始可以初始化的比较大,但是后面就要逐渐缩小λ的数值,以减少负样本对损失函数的影响。因此作者设计了λ的变化函数。

Recurrent AutoEncoder with LSTM Cells
作者考虑到一个运动的过程肯定包含着运动前动作和运动后动作,这些都对highlight有着显著的影响,因此作者采用双向的lstm网络
实验
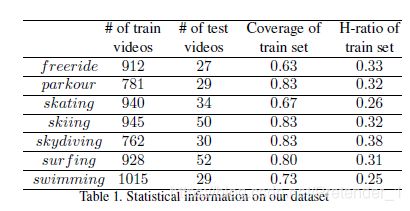
上图是作者收集的数据。
作者比较了2D和3D卷积的结果。

同时还对λ的初始化进行了实验,试验不同的初始化对结果的影响:

总结
这篇文章主要提出了对highlight的一种无监督的方法,和如何通过网上的多样性数据进行模型的训练同时能够减少负样本数据对模型的影响。
我个人觉得如果能够结合上音频的信息进行处理效果应该会更好,因此就需要考虑到如何结合,最近看的论文还不多,后面也许会有些思路。