CNN & Tensorflow 入门——以Cifar-10为例
其实这是算分Project的内容,受到CS231n启发,我和晶晶打算做图像分类的机器学习项目。很多人向我推荐tensorflow训练数据,因为有模板,不用手推python公式。
首先参考tensorflow官方文档中文版。
下载tensorflow (Mac OS) 很简单,安装了anaconda大礼包后,直接输入
$ pip install https://storage.googleapis.com/tensorflow/mac/tensorflow-0.5.0-py2-none-any.whl然后是入门级的学习笔记:tensorflow,张量+数据流,是基于graph的计算。
session是上下文。tf在生成graph后,选择必要的路径计算,而不是逐条语句执行,因而高效。
笔记1 笔记2
接着跟随官方文档的脚步,看MNIST入门。
(啊我没怎么看,只知道MNIST是手写字符识别…)
CNN到底是什么
在tensorflow的模板中,CNN的结构是这样的。
模型的预测流程由inference()构造,该函数会添加必要的操作步骤用于计算预测值的 logits,其对应的模型组织方式如下所示:

由conv卷积层,pool池化层,norm归一化,local全连接层,softmax输出层构成。
由于时间紧张,主要参考机器之心的知乎回答
以及神经网络的直观解释
brief history
Yann Lecun 是深度学习三大鼻祖之一,他在90年代初提出的LeNet-5成为NN的基础。
经典的网络结构:Lecun做的是字符识别。

这是现在的网络结构:图像分类。其实30年来差别不大。
CNN在2012年的翻身之作,标志着CNN进入computer vision,NIPS2012,深度学习三大鼻祖之一Hinton的论文《imagenet classification with deep CNN》中的网络结构(AlexNet):
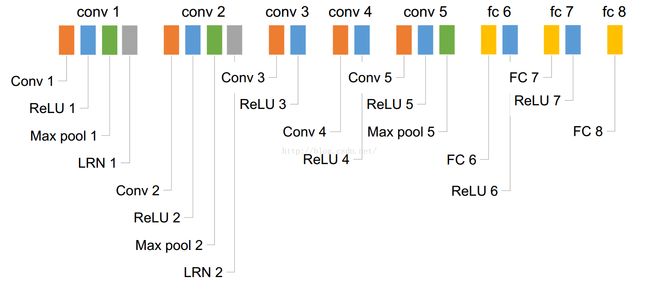
我已经存在本地了,经典之作必须阅读。
现在逐一解释:
pixel 像素
现在我已经明白,图像是RGB三通道的,就会是一个三维tensor,深度是3,存储red,green,blue分量的值[0,255]。
而为了存储方便,有时会采用灰度矩阵。RGB转灰度值的著名心理学公式:
Gray=R∗0.299+G∗0.587+B∗0.114
convolutional layer 卷积层
第一层往往是卷积层convolutional layer.
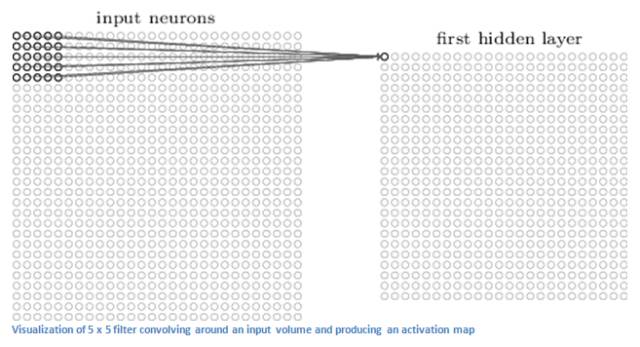
这是卷积层的卷积核——过滤器filter,比如它是一个5*5*3的tensor,和图像的相应5*5*3作卷积,不断遍历相邻的块,得到一个28*28*1的matrix。
过滤器是一个特征识别器。
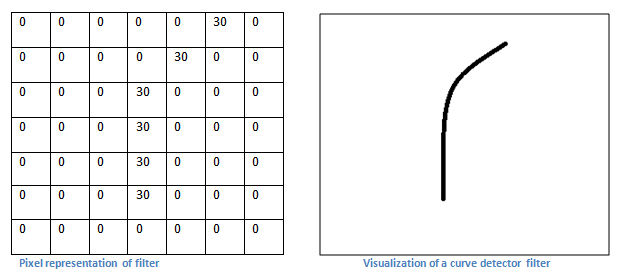
做卷积如图所示,符合这一特征的块对应的结果会很大。
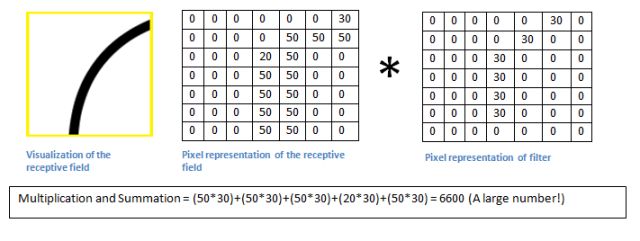
我们把这个结果称作激活图/特征图(activation map/),相当于图像的某个小块激活了某一特征。
各种filter的效果
不同的过滤器会得到不同的激活映射matrix,将其叠成tensor,就构成了28*28*n的卷积层(n个feature map)。
如这是两个filter特征提取的动画。
至于相邻的卷积层,是指后一层的卷积层的输入是前一层的输出。这样越深的卷积层的视野越开阔,能看到更大的图像部分,提取整体的特征。如第一层是判断曲线直线,第二层是鼻子嘴,第三层是脸手。
ReLU层 rectified linear units
在每个卷积层之后,通常会立即应用一个非线性层(或激活层)。其目的是给一个在卷积层中刚经过线性计算操作(只是数组元素依次(element wise)相乘与求和)的系统引入非线性特征。过去,人们用的是像双曲正切和 S 型函数这样的非线性方程,但研究者发现 ReLU 层效果好得多,因为神经网络能够在准确度不发生明显改变的情况下把训练速度提高很多(由于计算效率增加)。它同样能帮助减轻梯度消失的问题——由于梯度以指数方式在层中消失,导致网络较底层的训练速度非常慢。ReLU 层对输入内容的所有值都应用了函数 f(x) = max(0, x)。用基本术语来说,这一层把所有的负激活(negative activation)都变为零。这一层会增加模型乃至整个神经网络的非线性特征,而且不会影响卷积层的感受野。
修正线性单元层。
简单来说,卷积层都是tensor乘法,线性代数,难免会有局限性。在卷积层之后加入ReLU层,把特征图的负激活值抹去,引入非线性特征?
当然还有sigmoid tanh代替ReLu层。
pooling layer 池化层
在样例代码中,conv和relu合并,之后是pooling,又称为downsampling。
通常取maxpooling(or averagepooling),即选取conv+relu的特征图的局部最大值。
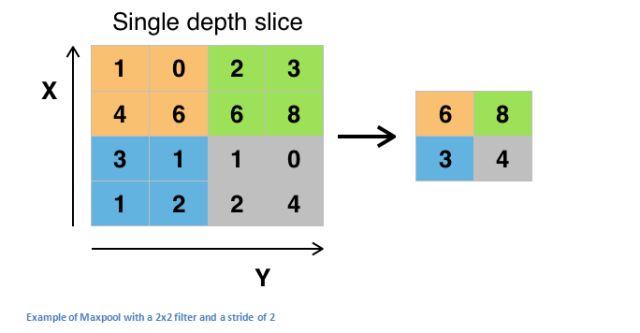
作用:缩小空间维度+防止过拟合
Local Response Normalization
局部响应归一化。LRN
这一层没介绍,但代码里有。
公式是:
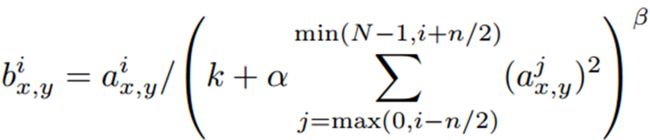
将相邻feature maps取“局部归一”处理。好像没啥用…
三剑客conv+ReLu+pooling负责特征提取,full connected负责分类
full connected layer 全连接层
最后一层是全连接层,比较简单。输入是tensor,输出是每个类别的概率向量。方法有softmax计算概率。每个类别有自己的特征组合,全连接层就是比对不同特征组合的吻合度。相当于一个分类器。
how to train
这是cifar10_train.py 内容。
一个学习周期:前向传播(CNN),损失函数(计算loss),反向传播(梯度下降),参数更新。
这里参数就是卷积层的那么多过滤器吧。初识化过滤器是随机的。
我们在全连接层得到结果后,与真实的标签作loss function,通过梯度下降法,指定学习率,更新参数。
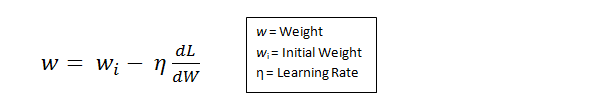
关于参数
普通的权值参数就是过滤器本身的值。
超参数也很多,有步幅stride(过滤器一次移动几格),零填充(在图像周围填上0,处理边界,使得输出也是32*32*3),当然还有过滤器尺寸。
学习率,损失函数的选取,那真是更大的超参数。
stride=2
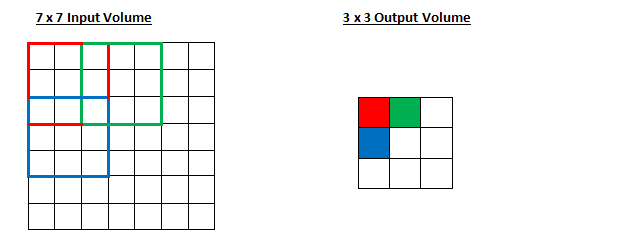
zero padding=2

dropout layer
直接暴力丢弃一些激活结果的值,置为0.防止过拟合。
我们发现,训练和测试用的模型是同一个2333,当然dropout只在训练中使用。
Data Augmentation
正如我们下面cifar10_input.py中看到的,保持标签不变,改变图片的性质(子图,翻转,旋转,白化,亮度,对比度),扩大数据集,防止过拟合
训练过程梗概
完整的卷积网络的训练过程可以总结如下:
第一步:我们初始化所有的滤波器,使用随机值设置参数/权重
第二步:网络接收一张训练图像作为输入,通过前向传播过程(卷积、ReLU 和池化操作,以及全连接层的前向传播),找到各个类的输出概率
我们假设船这张图像的输出概率是 [0.2, 0.4, 0.1, 0.3]
因为对于第一张训练样本的权重是随机分配的,输出的概率也是随机的第三步:在输出层计算总误差(计算 4 类的和)
Total Error = ∑ ½ (target probability – output probability) ²第四步:使用反向传播算法,根据网络的权重计算误差的梯度,并使用梯度下降算法更新所有滤波器的值/权重以及参数的值,使输出误差最小化
权重的更新与它们对总误差的占比有关
当同样的图像再次作为输入,这时的输出概率可能会是 [0.1, 0.1, 0.7, 0.1],这就与目标矢量 [0, 0, 1, 0] 更接近了
这表明网络已经通过调节权重/滤波器,可以正确对这张特定图像的分类,这样输出的误差就减小了
像滤波器数量、滤波器大小、网络结构等这样的参数,在第一步前都是固定的,在训练过程中保持不变——仅仅是滤波器矩阵的值和连接权重在更新第五步:对训练数据中所有的图像重复步骤 1 ~ 4
当然conv,pool层的分配及数量由我们自己决定,几十层乃至上百层效果更好。
3d数字识别
tf-CNN
时隔两周,让我们直奔主题。Cifar CNN
目前在我可怜的Macbook Air上运行着,第一次体会到炼丹的时间之漫长…估计要两三个小时。正好我可以学习tf。
对CIFAR-10 数据集的分类是机器学习中一个公开的基准测试问题,其任务是对一组32x32RGB的图像进行分类,这些图像涵盖了10个类别:
飞机, 汽车, 鸟, 猫, 鹿, 狗, 青蛙, 马, 船以及卡车。
本教程的重点
CIFAR-10 教程演示了在TensorFlow上构建更大更复杂模型的几个种重要内容:
- 相关核心数学对象,如卷积、修正线性激活、最大池化以及局部响应归一化
- 训练过程中一些网络行为的可视化,这些行为包括输入图像、损失情况、网络行为的分布情况以及梯度
- 算法学习参数的移动平均值的计算函数,以及在评估阶段使用这些平均值提高预测性能
- 实现了一种机制,使得学习率随着时间的推移而递减
- 为输入数据设计预存取队列,将磁盘延迟和高开销的图像预处理操作与模型分离开来处理
我们也提供了模型的多GUP版本,用以表明:
- 可以配置模型后使其在多个GPU上并行的训练
- 可以在多个GPU之间共享和更新变量值
模型架构
本教程中的模型是一个多层架构,由卷积层和非线性层(nonlinearities)交替多次排列后构成。这些层最终通过全连通层对接到softmax分类器上。这一模型除了最顶部的几层外,基本跟Alex Krizhevsky提出的模型一致。
在一个GPU上经过几个小时的训练后,该模型达到了最高86%的精度。细节请查看下面的描述以及代码。模型中包含了1,068,298个学习参数,分类一副图像需要大概19.5M个乘加操作。
代码
- cifar10_input.py 读取本地CIFAR-10的二进制文件格式的内容。
- cifar10.py 建立CIFAR-10的模型。
- cifar10_train.py 在CPU或GPU上训练CIFAR-10的模型。
- cifar10_multi_gpu_train.py 在多GPU上训练CIFAR-10的模型。
- cifar10_eval.py 评估CIFAR-10模型的预测性能。
以下参考详细的博文,tf,及CNN分析源码。
一个标准的机器学习程序,应该包括数据输入、定义模型本身、模型训练和模型性能测试四大部分,可以分成四个.py文件。
输入数据 cifar10_input.py
输入模型是通过 inputs() 和distorted_inputs()函数建立起来的,这2个函数会从CIFAR-10二进制文件中读取图片文件,由于每个图片的存储字节数是固定的,因此可以使用tf.FixedLengthRecordReader函数。
注意我们下载的是二进制文件(即图片的像素点矩阵),相当于32*32*3 bits.
从概念上来说,这部分主要是关于数据管道(data pipe)的构建,数据流向为“二进制文件->文件名队列->数据队列->读取出的data-batch”。
分析源码
IMAGE_SIZE = 24
原图像的尺度为32*32,但根据常识,信息部分通常位于图像的中央,这里定义了以中心裁剪后图像的尺寸.
% Global constants describing the CIFAR-10 data set.
NUM_CLASSES = 10
NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN = 50000
NUM_EXAMPLES_PER_EPOCH_FOR_EVAL = 10000深度学习中batch_size指一次迭代的数据量,epoch指全体数据量。global constants
train和eval分别是训练和评价部分。
第一个函数负责格式转换->tensor.
def read_cifar10(filename_queue):
class CIFAR10Record(object):
pass
result = CIFAR10Record()
# 建立一个空对象?
label_bytes = 1
result.height = 32
result.width = 32
result.depth = 3
image_bytes = result.height * result.width * result.depth
record_bytes = label_bytes + image_bytes
# 每个图片的数据大小是确定的,image+label,label在像素点之前。
# Read a record, getting filenames from the filename_queue.
# 每次从reader里读入固定大小的数据(key,value),注意是文件名队列,FIFO,读完就指向下一个文件。
reader = tf.FixedLengthRecordReader(record_bytes=record_bytes)
result.key, value = reader.read(filename_queue)
# Convert from a string to a vector of uint8 that is record_bytes long.
record_bytes = tf.decode_raw(value, tf.uint8)
# The first bytes represent the label, which we convert from uint8->int32. 读取label
result.label = tf.cast(
tf.slice(record_bytes, [0], [label_bytes]), tf.int32)
# The remaining bytes after the label represent the image, which we reshape
# from [depth * height * width] to [depth, height, width]. 原本是一维向量,转换为三维tensor
depth_major = tf.reshape(tf.slice(record_bytes, [label_bytes], [image_bytes]),
[result.depth, result.height, result.width])
# Convert from [depth, height, width] to [height, width, depth].
result.uint8image = tf.transpose(depth_major, [1, 2, 0])
return result
以上是将二进制文件流的一维字符串转换为一个个[height,width,depth]的tensor。
def _generate_image_and_label_batch(image, label, min_queue_examples,batch_size):
#Construct a queued batch of images and labels.第二个函数是随机生成一个tensor队列给每一个batch(注意我们不一定是顺序读)
第三个函数def distorted_inputs(data_dir, batch_size): 使图像变形!为了扩大数据量,防止过拟合。
# Randomly crop a [height, width] section of the image. 随机裁剪一个子图
distorted_image = tf.image.random_crop(reshaped_image, [height, width])
# Randomly flip the image horizontally.随机左右翻转
distorted_image = tf.image.random_flip_left_right(distorted_image)
# 随机调整亮度
distorted_image = tf.image.random_brightness(distorted_image, max_delta=63)
# 随机调整对比度
distorted_image = tf.image.random_contrast(distorted_image, lower=0.2, upper=1.8)
# 白化处理
float_image = tf.image.per_image_whitening(distorted_image)
多说一句白化处理:目的是降低输入图像的冗余性,尽量去除输入特征间的相关性。因为相邻像素往往特征一致,我们不希望冗余。
这个函数开了我的眼界。一张图片在我们的模型中是好几张图片,对称子图翻转亮度对比度白化,无所不用,使图片更普适。
Cifar10.py
build the network.
import cifar10_input 注意python直接import程序名进行调用,很方便
batch_size=128; 好像是为了cache,2的幂。
# Constants describing the training process.
MOVING_AVERAGE_DECAY = 0.9999 # The decay to use for the moving average.
NUM_EPOCHS_PER_DECAY = 350.0 # Epochs after which learning rate decays.
LEARNING_RATE_DECAY_FACTOR = 0.1 # Learning rate decay factor.
INITIAL_LEARNING_RATE = 0.1 # Initial learning rate.学习率即步长会随着batch的增多而衰减,我们规定了衰减因子。
重量级函数 inference 规定了网络结构:conv1-pool1-norm1-conv2-norm2-pool2-local3-local4-softmax
还是逐个解释吧
首先是conv函数
with tf.variable_scope('conv1') as scope:
# 建立64个5*5*3大小的卷积核(过滤器),即产生64个feature maps
kernel = _variable_with_weight_decay('weights', shape=[5, 5, 3, 64],stddev=1e-4, wd=0.0)
# 计算卷积,stride=1, padding=same?
conv = tf.nn.conv2d(images, kernel, [1, 1, 1, 1], padding='SAME')
biases = _variable_on_cpu('biases', [64], tf.constant_initializer(0.0))
bias = tf.nn.bias_add(conv, biases)
# 配上ReLu层,抹掉负值
conv1 = tf.nn.relu(bias, name=scope.name)
_activation_summary(conv1)接着是pooling
pool1 = tf.nn.max_pool(conv1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1],padding='SAME', name='pool1')得到的conv1,进行最大池化,3*3卷积核(注意pooling针对feature map平面),步长2*2?
然后是LRN局部归一化norm
norm1 = tf.nn.lrn(pool1, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75,name='norm1')公式见上文分析部分
最后的full connected layer
with tf.variable_scope('local3') as scope:
# Move everything into depth so we can perform a single matrix multiply.
dim = 1
for d in pool2.get_shape()[1:].as_list():
dim *= d
reshape = tf.reshape(pool2, [FLAGS.batch_size, dim])
weights = _variable_with_weight_decay('weights', shape=[dim, 384],stddev=0.04, wd=0.004)
biases = _variable_on_cpu('biases', [384], tf.constant_initializer(0.1))
# 关键是个矩阵乘法: W*X+B 得到一维向量:分类的概率 W的参数是最多的
**local3 = tf.nn.relu(tf.matmul(reshape, weights) + biases, name=scope.name)**
_activation_summary(local3)之后说是softmax,但我感觉还是fc。
计算loss function
def loss(logits, labels):
# label变换成dense_labels
# 重点是cross_entropy
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(
logits, dense_labels, name='cross_entropy_per_example')
cross_entropy_mean = tf.reduce_mean(cross_entropy, name='cross_entropy')
tf.add_to_collection('losses', cross_entropy_mean)
return tf.add_n(tf.get_collection('losses'), name='total_loss')核心是tf.nn.sparse_softmax_cross_entropy_with_logits 参考
先做softmax
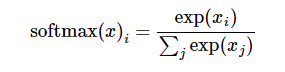
再做cross entropy
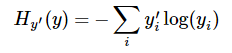
y′i=1 当且仅当i对应的是真实的标签, yi 是我们预测的概率
理论就省略了,引入log肯定有原因…
Cifar10_train.py
我们实际运行就是这个程序python cifar10_train.py
程序的主体是train 函数,调用了cifar10.py的train函数。以下是后者的描述:
def train(total_loss, global_step):
# 我选取了主体部分
# Decay the learning rate exponentially based on the number of steps.字面意思
lr = tf.train.exponential_decay(INITIAL_LEARNING_RATE,
global_step,
decay_steps,
LEARNING_RATE_DECAY_FACTOR,
staircase=True)
tf.summary.scalar('learning_rate', lr)
# Generate moving averages of all losses and associated summaries. 一个batch的loss平均
loss_averages_op = _add_loss_summaries(total_loss)
# Compute gradients. 计算梯度!
with tf.control_dependencies([loss_averages_op]):
opt = tf.train.GradientDescentOptimizer(lr)
grads = opt.compute_gradients(total_loss)回到cifar10_train.py
tf.app.flags.DEFINE_integer('max_steps', 100,"""Number of batches to run.""")
开头规定了batch多少次,即迭代次数,官方是100000次。相当于256 epochs,每张图片被提取256次。注意我们可不止学一遍!
Accuracy:
cifar10_train.py achieves ~86% accuracy after 100K steps (256 epochs of
data) as judged by cifar10_eval.py
86% accuracy GPU 4-5h。我的CPU估计要一两天了。
我尝试了2万次(李老板的修改版),72%。
这是宏观的train函数,梳理了每一步的逻辑。
def train():
"""Train CIFAR-10 for a number of steps."""
with tf.Graph().as_default():
global_step = tf.Variable(0, trainable=False)
# Get images and labels for CIFAR-10. 使用data augmentation技术
images, labels = cifar10.distorted_inputs()
# Build a Graph that computes the logits predictions from the inference model. 建立CNN
logits = cifar10.inference(images)
# Calculate loss. 计算Loss
loss = cifar10.loss(logits, labels)
# Build a Graph that trains the model with one batch of examples and updates the model parameters.
train_op = cifar10.train(loss, global_step)
# 漫长的炼丹之路
for step in xrange(FLAGS.max_steps):
start_time = time.time()
# train 一次
_, loss_value = sess.run([train_op, loss])
duration = time.time() - start_time
if step % 10 == 0:
num_examples_per_step = FLAGS.batch_size
examples_per_sec = num_examples_per_step / duration
sec_per_batch = float(duration)
# 每10步输出
format_str = ('%s: step %d, loss = %.2f (%.1f examples/sec; %.3f '
'sec/batch)')
print (format_str % (datetime.now(), step, loss_value,
examples_per_sec, sec_per_batch))
cifar10_eval.py
比较简单,从略。
def evaluate():
"""Eval CIFAR-10 for a number of steps."""
with tf.Graph().as_default():
# Get images and labels for CIFAR-10.
eval_data = FLAGS.eval_data == 'test'
images, labels = cifar10.inputs(eval_data=eval_data)
# Build a Graph that computes the logits predictions from the
# inference model.
logits = cifar10.inference(images)
# Calculate predictions.
top_k_op = tf.nn.in_top_k(logits, labels, 1)
#调用eval_once函数def eval_once(saver, summary_writer, top_k_op, summary_op):
true_count = 0 # Counts the number of correct predictions.
total_sample_count = num_iter * FLAGS.batch_size
step = 0
while step < num_iter and not coord.should_stop():
predictions = sess.run([top_k_op])
true_count += np.sum(predictions)
step += 1
# Compute precision @ 1.
precision = true_count / total_sample_count
print('%s: precision @ 1 = %.3f' % (datetime.now(), precision))输出precision。
写的好长,以后再学习。