【论文解读 AAAI 2020】Graph-Based Reasoning over Heterogeneous External Knowledge for 常识问答

论文题目:Graph-Based Reasoning over Heterogeneous External Knowledge for Commonsense Question Answering
论文来源:AAAI 2020 信工所,北大,微软
论文链接:https://arxiv.org/abs/1909.05311
关键词:知识图谱,机器推理,常识问答,GCN,Attention
官方介绍:机器推理系列第一弹:机器推理在常识问答任务中的应用
本文处理的是常识问答任务。使用结构化的ConceptNet和非结构化的Wikipedia中的纯文本,作为两个外部知识源,并根据问题和答案选项,从两个知识源中抽取出evidence。再根据evidence构建出图,提出算法重新定义单词间的距离,进行节点的表示学习。然后使用GCN和图注意力机制进行节点的编码和evidence的聚合,得到最终的表示,用于答案的推断。
文章目录
- 1 摘要
- 2 引言
- 3 方法概览
- 4 知识抽取
- 4.1 从ConceptNet抽取出知识
- 4.2 从Wikipedia中抽取出知识
- 5 基于图的推理
- 5.1 基于图的上下文表示学习模块
- 5.2 基于图的推断模块
- 6 实验
- 7 总结
1 摘要
常识问答的目的是回答那些需要背景知识的问题,而且这些知识并没有在问题中明确表达出来。
主要的挑战是:如何从外部知识中获取证据,并根据这些证据做出预测。
最近的研究工作:1)从人工标注的证据中生成证据,但是人工标注证据耗时耗力,难以收集;2)从结构化或非结构化的知识库中抽取出证据,但不能同时利用这两种资源。
本文提出新方法,自动地从异质知识来源(heterogeneous knowledge sources)中抽取出证据,并且基于这些证据进行问答。
抽取的证据来源有结构化的知识库(ConceptNet)和Wikipedia plain texts。作者将这些来源的信息构建成图,以得到证据间的关系结构。
模型由两个模块组成:1**)基于图的上下文相关的词表示学习模块;2)基于图的推断模块**。第一个模块利用了图结构的信息,来重新定义单词间的距离,以更好地学习上下文的词表示。第二个模块使用图卷积网络,将邻居信息融合到节点的表示中,并使用图注意力机制进行证据的聚合,以用于最终答案的预测。
实验结果显示,本文提出的方法在以色列特拉维夫大学常识问答任务CommmonsenseQA数据集上取得了目前state-of-the-art的准确率。
2 引言
(1)任务介绍
1)推理
推理是人工智能和自然语言处理中一项重要的富有挑战的任务,目的是从原理(principle)和证据(evidence)中推理出结论。如果把推理过程看成运行一个机器的话,evidence就是机器的燃料,principle就是机器本身,机器使用燃料来生成预测出的推理结果。
大多数研究只将当前的数据点作为输入,忽略了背景知识中的重要证据。
2)常识问答
本文研究的是常识问答,收集背景知识并使用这些知识推理出问题的答案。
CommmonsenseQA是这一领域很有影响力的数据集,任务是给定1个有 m m m个tokens的自然语言问题 Q Q Q和5个候选答案 { a 1 , a 2 , . . . a 5 } {\{a_1, a_2, ... a_5}\} {a1,a2,...a5}作为输入,要求输出正确的答案。
该数据集在构建过程中已经保证每个候选答案都和问题中的词汇具有语义关联,因此正确回答该数据集中的问题需要有效利用问题和候选答案的相关背景知识。

蓝色的单词是来自问题的信息(concept),绿色的单词是ConceptNet中的证据(evidence),红色的单词表示根据证据选择出的答案。
上图就展示了CommmonsenseQA数据集中的一个例子,做出正确的决策需要多个外部知识。根据ConcepNet中结构化的知识,可以选出 ( A , C ) (A, C) (A,C);根据Wikipedia中的知识可以选出 ( C , E ) (C, E) (C,E)。结合这两个外部知识可以得出正确的答案 C C C。
(2)现有的方法
近些年有学者提出了一些方法来抽取出证据并基于证据进行推理。然而,这些方法要不是根据人工标注的证据生成新证据,要不就是从异质的知识来源中抽取出证据,例如ConceptNet中结构化的知识、Wikipedia中的纯文本(plain texts)。这些方法都只针对一种知识来源,不能同时利用这两种知识来源(结构化的知识和非结构化的纯文本知识)。
结构化的知识来源中包含着不同概念间的结构化关联信息,有助于机器推理,但是它们的覆盖率很低。纯文本可以提供丰富的高覆盖率的证据,可以对结构化的知识进行补充。
(3)作者提出
从异质的外部知识库中自动收集证据,并基于这些证据实现常识知识问答。
方法分为两个部分:1)知识抽取;2)基于图的推理。
在知识抽取部分,我们自动地从ConceptNet抽取出图路径并从Wilipedia中抽取出句子。为了更好地利用证据之间的关系信息,我们使用语义角色标注(SRL)从Wikipedia的句子中抽取出三元组并从ConceptNet中抽取出图路径,从而构建出图。
在基于图的推理部分,我们提出一个基于图的方法来更好地使用图中的信息。提出了两个基于图的模块:
1)基于图的上下文词表示学习模块:使用了图结构信息,对单词之间的距离进行重定义,以学习到更好的上下文词表示;
2)基于图的推断模块:先使用GCN将邻居的信息编码到节点的表示中,然后使用图注意力机制进行证据的聚合。
作者在CommonsenseQA数据集上进行实验,结果显示这两个模块都促进了模型性能的提升。
(4)贡献
-
使用基于图的方法,利用异质信息来源中的证据信息,以进行常识问答;
-
提出基于图的上下文词表示学习模块和基于图的推理模块,以更好地利用图中的信息,用于常识问答。
-
在在CommonsenseQA数据集上进行实验,实现了state-of-the-art。
3 方法概览
本文方法的概览如图2所示,由两部分组成:知识抽取和基于图的推理。

(1)知识抽取
根据给出的问题和选项,从结构化的知识库ConcpetNet和Wikipedia纯文本数据中抽取出知识,并使用这些知识的关联结构,构建成图。
(2)基于图的推理
提出两个模块:
1)基于图的上下文词表示学习模块:使用图信息重新定义单词间的距离,以更好地学习词表示;
2)基于图的推断模块:使用GCN和图注意力机制,聚合邻居的信息,得到节点的表示,以用于最终的预测。
接下来将详细介绍模型的每一个部分。
4 知识抽取
给定问题和选项,使用本文的方法从ConceptNet和Wikipedia中抽取出证据。
4.1 从ConceptNet抽取出知识
ConceptNet是常用的常识知识库,包含有百万级别的节点和边。ConceptNet中的三元组包括4个部分:两个节点,一个关系以及关系的权重。
针对每个问题和选项,首先识别出其在给定的ConceptNet图中对应的实体。然后在图中搜索从问题中的实体到选项中的实体的路径,路径小于3。接着,将覆盖到的三元组合并到一个图中,其中节点是三元组,边表示三元组间的关系。我们将此图称为Concept-Graph。
如果两个三元组 s i , s j s_i, s_j si,sj有相同的实体,则为两个三元组间添加连边。
为了获得ConceptNet节点的上下文词表示,我们根据ConceptNet中的关系模板,将三元组转换为自然语言序列。
4.2 从Wikipedia中抽取出知识
使用Spacy从Wikipedia中抽取出107M个句子,并使用Elastic Search tools为句子添加索引。
Spacy:https://spacy.io/
Elastic Search tools:https://www.elastic.co/
首先,去掉给定问题和选项中的停用词;然后将单词拼接起来作为queries,在Elastic Search engine中进行搜索。这个引擎会根据queries和所有Wikipedia句子的匹配得分进行排序。我们选取top K(实验中K=10)个句子作为Wikipedia的证据(evidence)。
为了得到Wikipedia证据中的结构信息,我们将这些证据构建成图。利用语义角色标注(SRL)为句中的每个谓词抽取出对应的要素(argument,例如主语、宾语)。图中的节点就是这些要素和谓词,两者之间的关系对应图中的边。
为了增强图的连通性,我们去掉了停用词并根据以下规则在节点 a , b a, b a,b间连边:
(1)节点 a a a包含于节点 b b b,且 a a a中的单词(word)数量大于3;
(2)节点 a a a和节点 b b b只有一个单词不同,并且 a a a和 b b b中单词的数量均大于3。
我们将Wikipedia图定义为Wiki-Graph。
5 基于图的推理
我们在抽取出的证据的基础上,提出基于图的推理模型,如图3所示。

模型由两个模块组成:
(1)基于图的上下文表示学习模块:使用图信息重新定单词间的距离,学习到更好的上下文词表示;
(2)基于图的推断模块:使用GCN和图注意力机制,得到节点的表示,用于最终的预测。
5.1 基于图的上下文表示学习模块
(1)引入预训练语言模型
一个简单的方式是:将所有的证据连接成一个序列,将其输入到XLNet中,得到每个单词的表示。
对于出现在不同的证据句子中但语义相关的单词,这种做法会增加单词间的距离。
(2)使用图结构
因此我们使用图结构来重新定义证据单词(evidence sentences)间的相对位置。这样的话,语义相关联的单词会有较短的相对距离,还可以使用证据内部的关系结构以得到更好的上下文单词表示。
(3)拓扑排序算法
作者使用如下的拓扑排序算法(算法1),根据构建的图来重新对输入的证据进行排序。

1)对于Wikipedia中的句子
对于Wikipedia中的句子,首先,我们构建一个句子图。evidence sentences S S S是图中的节点。对于两个句子 s i , s j s_i, s_j si,sj,若在Wiki-Graph中存在边 ( p , q ) (p, q) (p,q),其中 p , q p,q p,q分别存在于 s i , s j s_i, s_j si,sj中,则在句子图中添加边 ( s i , s j ) (s_i, s_j) (si,sj)。
然后,根据算法1,我们就可以得到排序后的evidence sentences S ′ S^{'} S′。
2)对于ConceptNet中结构化的三元组
对于ConceptNet中结构化的三元组,我们不直接将其表示成自然语言的形式。而是使用ConceptNet提供的关系模板将三元组转换成自然语言文本句子。
例如,“mammals HasA hair”降被转换成“mammals has hair”。通过这种方式,我们就得到抽取出的图(Concept-Graph)的基于三元组的句子集合 S T S_T ST。然后使用算法1中的方法,得到重新排序后的evidence S T ′ S^{'}_T ST′。
(4)融合两个来源的知识得到词表示
将排序后的ConceptNet evidence sentences S T ′ S^{'}_T ST′,排序后的Wikipedia evidence sentences S ′ S^{'} S′,问题 q q q以及选项 c c c,四部分进行拼接,作为XLNet的输入。XLNet的输出就是上下文的word piece的表示。
通过将抽取出的图(Concept-Graph和Wiki-Graph)转换成自然语言文本,实现了对两种异质知识来源信息的融合,将其整合到了同一个表示空间中。
5.2 基于图的推断模块
上述的基于XLNet的模型为预测提供了有效的word-level的信息。除此之外,图还可以提供semantic-level的信息,比如关系中的主语/宾语。因此,我们对图级别的evidence信息进行聚合,用于最终的预测。
(1)图卷积的使用
我们将Concept-Graph和Wiki-Graph两个evidence图视为一个图,并使用GCN编码图结构的信息,得到节点的表示。为了在evidence间传递信息并在图上进行推理,GCN通过对邻接节点的特征进行池化,来更新节点的特征。由于关系型的GCN通常会over-parameterize模型,因此我们在无向图上使用GCN。
第 i i i个节点的表示 h i 0 h^0_i hi0计算如(1)式所示:
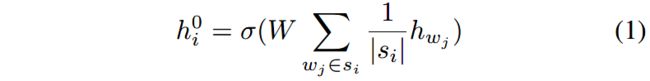
其中 s i = { w 0 , . . . , w t } s_i = {\{w_0, ..., w_t}\} si={w0,...,wt}是第 i i i个节点对应的evidence; h w j h_{w_j} hwj是XLNet输出的token w j w_j wj的上下文token表示; W ∈ R d × k W\in R^{d\times k} W∈Rd×k是用来降维的,将维度从 d d d减少到 k k k。
为了在图上进行推理,我们使用两个步骤实现信息的传播:聚合和结合。
1)聚合
从每个节点的邻居聚合信息,针对第 i i i个节点,聚合得到的信息 z i l z^l_i zil如(2)式所示。其中 N i N_i Ni表示第 i i i个节点的邻居, h j l h^l_j hjl是第 j j j个节点在第 l l l层的表示。

2)结合
z i l z^l_i zil包含了第 i i i个节点在第 l l l层的邻居信息,将其和转换后的第 i i i个节点的表示相结合,得到更新后的节点表示 h i l + 1 h^{l+1}_i hil+1。
(2)图注意力的使用
使用图注意力机制聚合graph-level的表示来进行预测,如下式所示。其中 h i L h^L_i hiL表示第 i i i个节点在最后一层的表示; h c h_c hc是XLNet中最后一个token的表示,可视为输入表示; α i \alpha_i αi表示第 i i i个节点的重要性; h g h^g hg是graph representation(我认为 h g h^g hg是一个矩阵,包括了图中所有节点的表示,因为 N N N没有下标,也就是 N N N不是针对某一节点的邻居集合)。

(3)进行预测
将输入的表示 h c h^c hc和图表示 h g h^g hg拼接起来作为多层感知机(MLP)的输入,来计算置信度分值 s c o r e ( q , a ) score(q, a) score(q,a)。候选的答案 a a a是问题 q q q的真实答案的概率计算如下,其中 A A A是候选答案集合。

选择置信度分值最高的候选答案作为预测结果。
注意,如图3所示,针对每个候选答案都生成一个图的表示 h g h^g hg,用于预测该答案是正确答案的概率。
6 实验
1、实验设置
数据集为CommonsenseQA,包含12,102个例子,9,741个用于训练,1,221个用于验证,1,140个用于测试。
使用XLNet large cased作为预训练模型。在每个选项前拼接“The answer is”,将每个选项转换成一个句子。
每个选项的输入形式为“ question The answer is ”。
基于所有的选项总共得到5个置信度得分,然后使用softmax函数计算出真实值和预测值间的损失,使用交叉熵损失作为损失函数。
2、Baselines
从leaderborad中已发布的模型选择出要和本文模型进行对比的方法,并将其分为4组;
-
Group 1:不使用描述或papers的模型,包括SGN-lite, BECON (single), BECON (ensemble), CSR-KG and CSR-KG (AI2 IR);
-
Group 2:不使用抽取出的知识的模型,包括BERT-large, XLNet-large和RoBERTa ;
-
Group 3:使用抽取出的知识的模型,包括BERT + AMS和BERT + CSPT,这些模型使用了ConceptNet中结构化的知识来增强模型的能力;
-
Group 4:使用抽取出的无结构知识的模型,包括BERT + AMS和BERT + CSPT。
这些模型要不利用了结构化知识的evidence信息,要不利用了非结构化知识的evidence信息,没有同时利用这两种来源的知识。
3、实验结果
(1)和Baselines对比

(2)消融实验
基于图的推理模块的有效性:

异质知识来源的有效性:

(3)例子学习
问题是:“Animals who have hair and don’t lay eggs are what?”
答案是:“mammals”
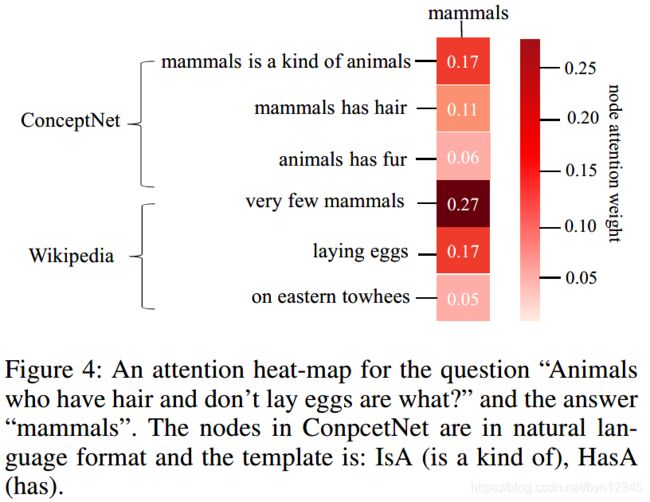
前三个节点是来源于ConceptNet evidence graph(Concept-Graph)的,可以看出“mammals is a kind of animals”和“mammals has hair”,为“mamals”和“animals”、“hair”两个概念间的关联提供了信息。
我们还需要能体现“lay eggs”和“mammals”间关联的evidence。
后三个节点来源于Wikipedia evidence graph(Wiki-Graph),它们提供了信息“very few mammals lay eggs”。
这个例子可以说明结构化的和非结构化的知识来源,对于推理出正确答案的必要性。
(4)错误分析
从验证集中选取了50个回答错误的样本,将其分成了三类:1)缺少evidence;2)有相似的evidence;3)数据集噪声。
有10个错误的样本是由于缺少evidence,例如图5中的第一个样本没有从ConceptNet和Wikipedia中抽取出evidence,因此没有足够的信息以得到正确的答案。使用增强的抽取的策略,增加更多的知识来源,可以缓解这一问题。

有38个错误的样本,它们得到了足够的evidence,但是evidence太相似了不能对选项加以区别。例如图5中的第二个例子,有“injury”和“puncture wound”两个选项,从两个知识源获取到的evidence有着相似的信息。为了缓解这一问题,应该从其他的知识源抽取出更多的evidence。
7 总结
本文解决的是常识问答问题。
本文提出的方法由知识抽取和基于图的推理两大部分组成。
在知识抽取部分,我们从异质的知识来源中抽取出来evidence信息。知识源包括:结构化的知识源ConceptNet和Wikipedia中的纯文本。我们使用两个来源的数据分别构建了图,并利用了关系结构信息。
在基于图的推理部分,我们提出了基于图的上下文词表示学习模块,以及基于图的推断模块。第一个模块使用了图结构信息对单词间的距离重定义,以学习到更好的上下文词表示。第二个模块使用了GCN将邻居信息编码到节点的表示中,然后使用图注意力机制进行evidence的聚合,用于最终答案的推断。
实验结果显示,本文的模型在CommonsenseQA leaderboard上实现了state-of-the-art。
未来工作:添加更多的异质知识源;改进本文模型中的推理模块以进一步提升模型性能。
本文的亮点在于:
(1)两种类型的外部知识库的利用
同时利用了结构化的外部知识源(ConceptNet)和非结构化的外部知识源(Wikipedia)。
其中,结构化的知识源包含概念之间的关联信息,有助于机器推理,但是覆盖率较低。非结构化的知识源包含丰富的高覆盖率的信息,对结构化知识进行了补充。实验也证明了同时使用这两种类型的知识源,可以提升模型的性能。
(2)基于图的方法充分利用了结构上的信息
知识抽取部分:
为了利用到更多的结构上的信息,作者将从两个外部知识库中抽取出的evidence信息构建成图。
基于图的推理部分:
1)上下文表示学习模块:为了减小在不同的evidence句子中,但是语义关联的单词间的相对距离,基于图结构的信息使用拓扑排序算法,对单词间的距离进行了重新的定义。将重新排序后两个图(Concept-Graph和Wiki-Graph)的evidence句子信息、问题和候选答案进行拼接,作为XLNet的输入,得到word-level的信息。
2)基于图的推断模块:在evidence图(将Concept-Graph和Wiki-Graph看成一个evidence图)上进行GCN并使用图注意力机制,得到每个节点(Concept-Graph中的节点是三元组,Wiki-Graph中的节点是谓词和要素)的表示。每个节点的向量表示罗列在一起得到图的表示矩阵。