Python 爬取 B 站 5000 条视频,揭秘为何千万人为它流泪!
这个夏天,《哪吒之魔童降世》碾压其他暑期档电影,成为最强黑马。我身边的朋友,不是已经N刷了这部电影,就是在赶去N刷的路上。从票房上也可窥见一斑:

数据爬取
在浏览器开发者模式CTRL+F很容易就能找到所需要的信息,就在页面源码中:

因此我们用beautifulsoup库就能快速方便地获取想要的信息啦。
因为B站视频数量有限定,每次搜索只能显示20条*50页=1000个视频信息。

为了尽可能多的获取视频信息,我另外还选了“最多点击”“最新发布”“最多弹幕”和“最多收藏”4个选项。

- http://search.bilibili.com/all?keyword=哪吒之魔童降世&from_source=nav_search&order=totalrank&duration=0&tids_1=0&page={}
- http://search.bilibili.com/all?keyword=哪吒之魔童降世&from_source=nav_search&order=click&duration=0&tids_1=0&page={}
- http://search.bilibili.com/all?keyword=哪吒之魔童降世&from_source=nav_search&order=stow&duration=0&tids_1=0&page={}
- http://search.bilibili.com/all?keyword=哪吒之魔童降世&from_source=nav_search&order=dm&duration=0&tids_1=0&page={}
- http://search.bilibili.com/all?keyword=哪吒之魔童降世&from_source=nav_search&order=pubdate&duration=0&tids_1=0&page={}
5个URL,一共爬取5000条视频,去重之后还剩下2388条信息。
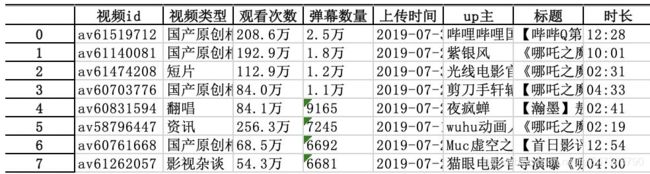
为了得到“转评赞”数据,我还以视频id里面的数字(去掉“av”)为索引,遍历访问了每个视频页面获取了更详细的数据,最终得到以下字段:

数据分析

电影在7月18、19日就进行了全国范围的点映,正式上映时间为7月26日,在这之后相关视频数量有明显的上升。
在这时间之前的,最早发布时间可以追溯到2018年11月份,大部分都是预告类视频:

在8月7日之后视频数量猛增,单单8月7日一天就新上传了319个相关视频。
从标题名字中我们可以大致了解视频的内容:

毫无疑问,“哪吒”和“敖丙”作为影片两大主角是视频的主要人物;因为他们同生共患难的情谊,“藕饼”(“哪吒+敖丙”组合)也是视频的关键词;除此之外,“国漫”也是一大主题词,毕竟我们这次是真正地被我们的国产动漫震撼到了。

实现代码
bilibili.py
import requests
import re
from datetime import datetime
import pandas as pd
import random
import time
'''
更多Python学习资料以及源码教程资料,可以在群821460695 免费获取
'''
video_time=[]
abstime=[]
userid=[]
comment_content=[]
def dateRange(beginDate, endDate):
dates = []
dt = datetime.datetime.strptime(beginDate, "%Y-%m-%d")
date = beginDate[:]
while date <= endDate:
dates.append(date)
dt = dt + datetime.timedelta(1)
date = dt.strftime("%Y-%m-%d")
return dates
#视频发布时间~当日
search_time=dateRange("2016-01-10", "2019-06-25")
headers = {
'Host': 'api.bilibili.com',
'Connection': 'keep-alive',
'Content-Type': 'text/xml',
'Upgrade-Insecure-Requests': '1',
'User-Agent': '',
'Origin': 'https://www.bilibili.com',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
# 'Cookie': 'finger=edc6ecda; LIVE_BUVID=AUTO1415378023816310; stardustvideo=1; CURRENT_FNVAL=8; buvid3=0D8F3D74-987D-442D-99CF-42BC9A967709149017infoc; rpdid=olwimklsiidoskmqwipww; fts=1537803390'
}
#cookie用火狐浏览器找,以字典形式写入
cookie={
# '_dfcaptcha':'2dd6f170a70dd9d39711013946907de0',
# 'bili_jct':'9feece81d443f00759b45952bf66dfff',
# 'buvid3':'DDCE08BC-0FFE-4E4E-8DCF-9C8EB7B2DD3752143infoc',
# 'CURRENT_FNVAL':'16',
# 'DedeUserID':'293928856',
# 'DedeUserID__ckMd5':'6dc937ced82650a6',
# 'LIVE_BUVID':'AUTO7815513331706031',
# 'rpdid':'owolosliwxdossokkkoqw',
# 'SESSDATA':'7e38d733,1564033647,804c5461',
# 'sid':' 9zyorvhg',
# 'stardustvideo':'1',
}
url='https://api.bilibili.com/x/v2/dm/history?type=1&oid=5627945&date={}'
for search_data in search_time:
print('正在爬取{}的弹幕'.format(search_data))
full_url=url.format(search_data)
res=requests.get(full_url,headers=headers,timeout=10,cookies=cookie)
res.encoding='utf-8'
data_number=re.findall('d p="(.*?)">',res.text,re.S)
data_text=re.findall('">(.*?)',res.text,re.S)
comment_content.extend(data_text)
for each_numbers in data_number:
each_numbers=each_numbers.split(',')
video_time.append(each_numbers[0])
abstime.append(time.strftime("%Y/%m/%d %H:%M:%S", time.localtime(int(each_numbers[4]))))
userid.append(each_numbers[6])
time.sleep(random.random()*3)
print(len(comment_content))
print('爬取完成')
result={'用户id':userid,'评论时间':abstime,'视频位置(s)':video_time,'弹幕内容':comment_content}
results=pd.DataFrame(result)
final= results.drop_duplicates()
final.info()
final.to_excel('B站弹幕(天鹅臂)最后.xlsx')
bilibili_danmu.py
import requests
import re
import datetime
import pandas as pd
import random
import time
'''
更多Python学习资料以及源码教程资料,可以在群821460695 免费获取
'''
video_time=[]
abstime=[]
userid=[]
comment_content=[]
def dateRange(beginDate, endDate):
dates = []
dt = datetime.datetime.strptime(beginDate, "%Y-%m-%d")
date = beginDate[:]
while date <= endDate:
dates.append(date)
dt = dt + datetime.timedelta(1)
date = dt.strftime("%Y-%m-%d")
return dates
#视频发布时间~当日
search_time=dateRange("2019-07-26", "2019-08-09")
headers = {
'Host': 'api.bilibili.com',
'Connection': 'keep-alive',
'Content-Type': 'text/xml',
'Upgrade-Insecure-Requests': '1',
'User-Agent': '',
'Origin': 'https://www.bilibili.com',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
#cookie用火狐浏览器找,以字典形式写入
cookie={
# '_dfcaptcha':'2dd6f170a70dd9d39711013946907de0',
'bili_jct':'bili_jct5bbff2af91bd6d6c219d1fafa51ce179',
'buvid3':'4136E3A9-5B93-47FD-ACB8-6681EB0EF439155803infoc',
'CURRENT_FNVAL':'16',
'DedeUserID':'293928856',
'DedeUserID__ckMd5':'6dc937ced82650a6',
'LIVE_BUVID':'AUTO6915654009867897',
# 'rpdid':'owolosliwxdossokkkoqw',
'SESSDATA':'72b81477%2C1567992983%2Cbd6cb481',
'sid':'i2a1khkk',
'stardustvideo':'1',
}
url='https://api.bilibili.com/x/v2/dm/history?type=1&oid=105743914&date={}'
for search_data in search_time:
print('正在爬取{}的弹幕'.format(search_data))
full_url=url.format(search_data)
res=requests.get(full_url,headers=headers,timeout=10,cookies=cookie)
res.encoding='utf-8'
data_number=re.findall('d p="(.*?)">',res.text,re.S)
data_text=re.findall('">(.*?)',res.text,re.S)
comment_content.extend(data_text)
for each_numbers in data_number:
each_numbers=each_numbers.split(',')
video_time.append(each_numbers[0])
abstime.append(time.strftime("%Y/%m/%d %H:%M:%S", time.localtime(int(each_numbers[4]))))
userid.append(each_numbers[6])
time.sleep(random.random()*3)
print(len(comment_content))
print('爬取完成')
result={'用户id':userid,'评论时间':abstime,'视频位置(s)':video_time,'弹幕内容':comment_content}
results=pd.DataFrame(result)
final= results.drop_duplicates()
final.info()
final.to_excel('B站弹幕(哪吒).xlsx')
bilibili_detailpage.py
from bs4 import BeautifulSoup
import requests
import warnings
import re
from datetime import datetime
import json
import pandas as pd
import random
import time
import datetime
from multiprocessing import Pool
'''
更多Python学习资料以及源码教程资料,可以在群821460695 免费获取
'''
url='https://api.bilibili.com/x/web-interface/view?aid={}'
headers = {
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1',
'Referer':'https://www.bilibili.com/',
'Connection':'keep-alive'}
cookies={'cookie':'LIVE_BUVID=AUTO6415404632769145; sid=7lzefkl6; stardustvideo=1; CURRENT_FNVAL=16; rpdid=kwmqmilswxdospwpxkkpw; fts=1540466261; im_notify_type_293928856=0; CURRENT_QUALITY=64; buvid3=D1539899-8626-4E86-8D7B-B4A84FC4A29540762infoc; _uuid=79056333-ED23-6F44-690F-1296084A1AAE80543infoc; gr_user_id=32dbb555-8c7f-4e11-beb9-e3fba8a10724; grwng_uid=03b8da29-386e-40d0-b6ea-25dbc283dae5; UM_distinctid=16b8be59fb13bc-094e320148f138-37617e02-13c680-16b8be59fb282c; DedeUserID=293928856; DedeUserID__ckMd5=6dc937ced82650a6; SESSDATA=b7d13f3a%2C1567607524%2C4811bc81; bili_jct=6b3e565d30678a47c908e7a03254318f; _uuid=01B131EB-D429-CA2D-8D86-6B5CD9EA123061556infoc; bsource=seo_baidu'}
k=0
def get_bilibili_detail(id):
global k
k=k+1
print(k)
full_url=url.format(id[2:])
try:
res=requests.get(full_url,headers=headers,cookies=cookies,timeout=30)
time.sleep(random.random()+1)
print('正在爬取{}'.format(id))
content=json.loads(res.text,encoding='utf-8')
test=content['data']
except:
print('error')
info={'视频id':id,'最新弹幕数量':'','金币数量':'','不喜欢':'','收藏':'','最高排名':'','点赞数':'','目前排名':'','回复数':'','分享数':'','观看数':''}
return info
else:
danmu=content['data']['stat']['danmaku']
coin=content['data']['stat']['coin']
dislike=content['data']['stat']['dislike']
favorite=content['data']['stat']['favorite']
his_rank=content['data']['stat']['his_rank']
like=content['data']['stat']['like']
now_rank=content['data']['stat']['now_rank']
reply=content['data']['stat']['reply']
share=content['data']['stat']['share']
view=content['data']['stat']['view']
info={'视频id':id,'最新弹幕数量':danmu,'金币数量':coin,'不喜欢':dislike,'收藏':favorite,'最高排名':his_rank,'点赞数':like,'目前排名':now_rank,'回复数':reply,'分享数':share,'观看数':view}
return info
if __name__=='__main__':
df=pd.read_excel('哪吒.xlsx')
avids=df['视频id']
detail_lists=[]
for id in avids:
detail_lists.append(get_bilibili_detail(id))
reshape_df=pd.DataFrame(detail_lists)
final_df=pd.merge(df,reshape_df,how='inner',on='视频id')
final_df.to_excel('藕饼cp详情new.xlsx')
final_df.info()
# final_df.duplicated(['视频id'])
# reshape_df.to_excel('藕饼cp.xlsx')
bilibili_search.py
from bs4 import BeautifulSoup
import requests
import warnings
import re
from datetime import datetime
import json
import pandas as pd
import random
import time
import datetime
from multiprocessing import Pool
'''
更多Python学习资料以及源码教程资料,可以在群821460695 免费获取
'''
headers = {
'User-Agent': ''
'Referer':'https://www.bilibili.com/',
'Connection':'keep-alive'}
cookies={'cookie':''}
def get_bilibili_oubing(url):
avid=[]
video_type=[]
watch_count=[]
comment_count=[]
up_time=[]
up_name=[]
title=[]
duration=[]
print('正在爬取{}'.format(url))
time.sleep(random.random()+2)
res=requests.get(url,headers=headers,cookies=cookies,timeout=30)
soup=BeautifulSoup(res.text,'html.parser')
#avi号码
avids=soup.select('.avid')
#视频类型
videotypes=soup.find_all('span',class_="type hide")
#观看数
watch_counts=soup.find_all('span',title="观看")
#弹幕
comment_counts=soup.find_all('span',title="弹幕")
#上传时间
up_times=soup.find_all('span',title="上传时间")
#up主
up_names=soup.find_all('span',title="up主")
#title
titles=soup.find_all('a',class_="title")
#时长
durations=soup.find_all('span',class_='so-imgTag_rb')
for i in range(20):
avid.append(avids[i].text)
video_type.append(videotypes[i].text)
watch_count.append(watch_counts[i].text.strip())
comment_count.append(comment_counts[i].text.strip())
up_time.append(up_times[i].text.strip())
up_name.append(up_names[i].text)
title.append(titles[i].text)
duration.append(durations[i].text)
result={'视频id':avid,'视频类型':video_type,'观看次数':watch_count,'弹幕数量':comment_count,'上传时间':up_time,'up主':up_name,'标题':title,'时长':duration}
results=pd.DataFrame(result)
return results
if __name__=='__main__':
url_original='http://search.bilibili.com/all?keyword=哪吒之魔童降世&from_source=nav_search&order=totalrank&duration=0&tids_1=0&page={}'
url_click='http://search.bilibili.com/all?keyword=哪吒之魔童降世&from_source=nav_search&order=click&duration=0&tids_1=0&page={}'
url_favorite='http://search.bilibili.com/all?keyword=哪吒之魔童降世&from_source=nav_search&order=stow&duration=0&tids_1=0&page={}'
url_bullet='http://search.bilibili.com/all?keyword=哪吒之魔童降世&from_source=nav_search&order=dm&duration=0&tids_1=0&page={}'
url_new='http://search.bilibili.com/all?keyword=哪吒之魔童降世&from_source=nav_search&order=pubdate&duration=0&tids_1=0&page={}'
all_url=[url_bullet,url_click,url_favorite,url_new,url_original]
info_df=pd.DataFrame(columns = ['视频id','视频类型','观看次数','弹幕数量','上传时间','up主','标题','时长'])
for i in range(50):
for url in all_url:
full_url=url.format(i+1)
info_df=pd.concat([info_df,get_bilibili_oubing(full_url)],ignore_index=True)
print('爬取完成!')
#去重
info_df=info_df.drop_duplicates(subset=['视频id'])
info_df.info()
info_df.to_excel('哪吒.xlsx')