使用开源ASR框架在Mono和.NET C#中进行语音识别
目录
介绍
背景
GitHub储存库
入门
在MonoDevelop中
在Visual Studio中
获取所需文件
转录没有语法的音频文件
获取日志信息
为什么有那么多Path.Combine(s)?
启动StreamSpeechRecognizer
无需语法即可转录音频文件的总体代码
使用语法(JSGF)转录音频文件
使用语法转录音频文件的总体代码
外部资源
兴趣点
- 从GitHub下载项目(〜34.1 MB)
(包含Mono项目文件,包括所有必需的声学模型和2个其他Sample Wave音频文件。只需单击右下角的“下载zip”按钮。)
本文中使用的框架可以作为开源项目使用。您可以在下面找到到存储库的链接。
https://github.com/SynHub/syn-speech
介绍
本文通过采用2种不同的方法将音频文件(以WAVE格式编码)转录为文本来说明Mono中连续的独立于说话者的语音识别。
背景
进入Mono Linux中的语音识别——我一直在耐心等待一个启示的降临。尤其是因为我正在从事智能住宅项目,并且我不希望将Windows用作该项目的主要操作系统。相反,我使用Linux和Mono框架。我确实确实需要我可以使用的语音识别库。因此,经过数月的互联网抱怨之后,我终于找到了合适的库。
GitHub储存库
最近(在撰写本文时),该框架已开源。您可以在此处找到语音识别引擎的完整源代码。
入门
现在进入正题,我不打算创建一些科幻的GUI来演示功能和使用范例。相反,我将使用老式Console界面。
在MonoDevelop中
我将与MonoDevelop合作,但是Visual Studio开发人员应该不难遵循。相反,这对于使用Visual Studio的开发人员来说应该更容易。
启动MonoDevelop-> File-> New-> Solution并选择Console C#
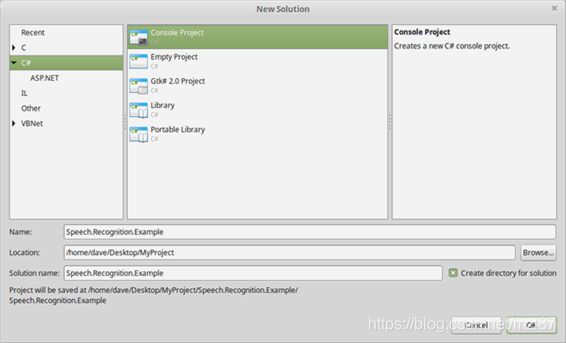
创建控制台项目后,必须继续并导入所需的NuGet包。
为此(如果您已经在MonoDevelop中安装了NuGet软件包管理器),请右键单击您的项目名称,然后选择管理NuGet软件包...
系统将显示“管理软件包...”对话框。在搜索框中,键入Syn.Speech并按Enter。
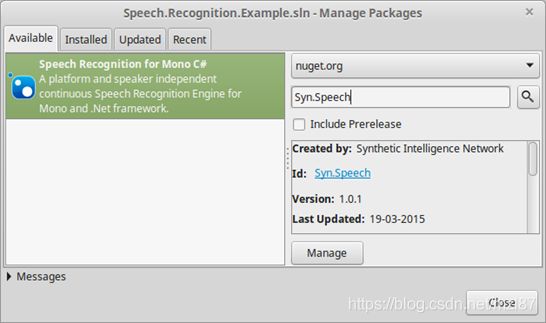
找到库后,单击添加。
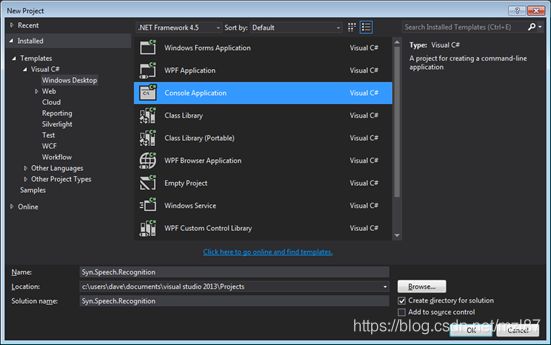
在Visual Studio中
选择FILE-> New-> Project-> Visual C#-> Console Application
要将库导入到项目中,请单击工具-> NuGet软件包管理器->软件包管理器控制台,然后键入:
PM> Install-Package Syn.Speech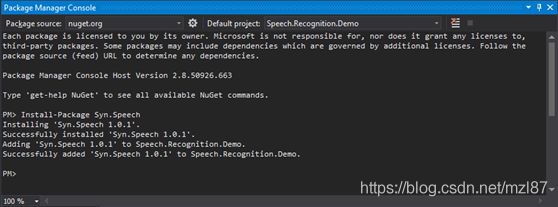
太棒了!我们已经导入了所需的库。
继续前进,库本身不能仅在没有一些数据备份的情况下转录给定的音频文件。在语音识别领域,这些被称为声学模型。
获取所需文件
大多数模型非常庞大,因为它们接受了大量数据的训练并描述了复杂的语言。这就是为什么我没有将它们上传到本文的原因之一。
因此,请忍受并下载本文所附的项目文件。
下载文件后,解压缩存档。浏览Bin/Debug目录,您将找到Models和Audio文件夹。将这些文件夹复制并粘贴到Mono Project的Bin/Debug目录中。
好了,因此我们有了所需的模型(声学模型)和音频文件可以转录。
是时候写一些代码了...
转录没有语法的音频文件
我们正在使用的语音识别引擎(在编写本教程时)只能处理WAVE Audio文件。
在Audio目录中,我们有2个音频文件,即Long Audio.wav和Long Audio 2.wav。在继续尝试转录这些文件之前,请听Long Audio 2.wav。您会发现有人说“时间现在正好是12:35 ”。
对于任何离线语音识别引擎(处理有限的声学模型集),以上句子都是要转录的很长的句子。但是我们还是要转录它,所以等等。
在您的控制台应用程序的MainClass中,添加以下C#代码:
static Configuration speechConfiguration;
static StreamSpeechRecognizer speechRecognizer;上面的代码声明了2个重要的对象,我们稍后将对其进行初始化。
首先是Configuration类。此类包含诸如声学模型、语言模型和字典的位置之类的信息。最重要的是,它还告诉语音识别器我们是否打算使用语法文件。
继续讲,StreamSpeechRecognizer类是允许您将Audio流定向到语音识别引擎的主要类。一旦计算完成,我们将使用相同的类来获取结果。
获取日志信息
我们不能盲目地让StreamSpeechRecognizer为我们转录音频文件而不知道内部发生了什么。相反,我们应该尝试更多地了解它。故事结局。
要获取由语音识别引擎生成的内部日志,请在上述静态变量下方添加以下C#代码。
static void LogReceived (object sender, LogReceivedEventArgs e)
{
Console.WriteLine (e.Message);
}现在在Main方法中,添加以下行:
Logger.LogReceived += LogReceived;因此,现在,无论记录器收到什么消息,它都将被写入控制台。
让我们初始化和设置Configuration和StreamSpeechRecognizer类。
在Main方法中添加以下代码。
var modelsDirectory = Path.Combine (Directory.GetCurrentDirectory (), "Models");
var audioDirectory = Path.Combine (Directory.GetCurrentDirectory (), "Audio");
var audioFile = Path.Combine (audioDirectory, "Long Audio 2.wav");
if (!Directory.Exists (modelsDirectory)||!Directory.Exists(audioDirectory)) {
Console.WriteLine ("No Models or Audio directory found!! Aborting...");
Console.ReadLine ();
return;
}
speechConfiguration = new Configuration ();
speechConfiguration.AcousticModelPath=modelsDirectory;
speechConfiguration.DictionaryPath = Path.Combine (modelsDirectory, "cmudict-en-us.dict");
speechConfiguration.LanguageModelPath = Path.Combine (modelsDirectory, "en-us.lm.dm在上面的代码中,我创建了一些变量,用于保存Bin/Debug文件夹中Models和Audio目录的位置。
在代码的后面,有一个麻烦的检查——验证是否已正确将Audio and Models目录复制到正确的文件夹中。
接下来,我们遇到speechConfiguration变量并初始化其属性。
- speechConfiguration.AcousticModelPath ——放置我们大多数声学模型文件的路径
- speechConfiguration.DictionaryPath——字典文件的路径(在我们的例子中位于Models目录中)
- speechConfiguration.LanguageModelPath——语言模型文件的路径(也存在于“模型”目录中)
在将配置转移到语音识别器之前,必须分配所有上述属性。
为什么有那么多Path.Combine(s)?
嗯,Windows和Linux中的路径分隔符不同,即Windows使用反斜杠(\),而Linux使用正斜杠(/)。Path.Combine在合并路径时会处理这些混乱情况,以确保我们的代码在Windows和Linux中均可正常工作。
启动StreamSpeechRecognizer
在上面的代码之后添加以下代码:
speechRecognizer = new StreamSpeechRecognizer (speechConfiguration);
speechRecognizer.StartRecognition (new FileStream (audioFile, FileMode.Open));
Console.WriteLine ("Transcribing...");
var result = speechRecognizer.GetResult ();
if (result != null) {
Console.WriteLine ("Result: " + result.GetHypothesis ());
}
else {
Console.WriteLine ("Sorry! Coudn't Transcribe");
}
Console.ReadLine ();在上面的代码中,我们首先实例化该speechRecogizer对象,然后调用该StartRecognition方法,并传递一个指向要尝试转录的音频文件的FileStream。
语音识别实际上是在我们调用StartRecognition方法后才开始的,而是仅在调用GetResult方法时才开始计算。
计算完结果后,我们将调用GetHypothesis方法以将假设检索为string。
无需语法即可转录音频文件的总体代码
using System;
using Syn.Speech.Api;
using System.IO;
using Syn.Logging;
namespace Speech.Recognition.Example
{
class MainClass
{
static Configuration speechConfiguration;
static StreamSpeechRecognizer speechRecognizer;
static void LogReceived (object sender, LogReceivedEventArgs e)
{
Console.WriteLine (e.Message);
}
public static void Main (string[] args)
{
Logger.LogReceived += LogReceived;
var modelsDirectory = Path.Combine (Directory.GetCurrentDirectory (), "Models");
var audioDirectory = Path.Combine (Directory.GetCurrentDirectory (), "Audio");
var audioFile = Path.Combine (audioDirectory, "Long Audio 2.wav");
if (!Directory.Exists (modelsDirectory)||!Directory.Exists(audioDirectory)) {
Console.WriteLine ("No Models or Audio directory found!! Aborting...");
Console.ReadLine ();
return;
}
speechConfiguration = new Configuration ();
speechConfiguration.AcousticModelPath=modelsDirectory;
speechConfiguration.DictionaryPath = Path.Combine (modelsDirectory, "cmudict-en-us.dict");
speechConfiguration.LanguageModelPath = Path.Combine (modelsDirectory, "en-us.lm.dmp");
speechRecognizer = new StreamSpeechRecognizer (speechConfiguration);
speechRecognizer.StartRecognition (new FileStream (audioFile, FileMode.Open));
Console.WriteLine ("Transcribing...");
var result = speechRecognizer.GetResult ();
if (result != null) {
Console.WriteLine ("Result: " + result.GetHypothesis ());
} else {
Console.WriteLine ("Sorry! Couldn't Transcribe");
}
Console.ReadLine ();
}
}
}如果运行上面的代码(在MonoDevelop中按Ctrl + F5),您应该会看到一个控制台,其中包含大量信息。最后(几秒钟后),您应该在屏幕上看到结果。类似于以下内容:
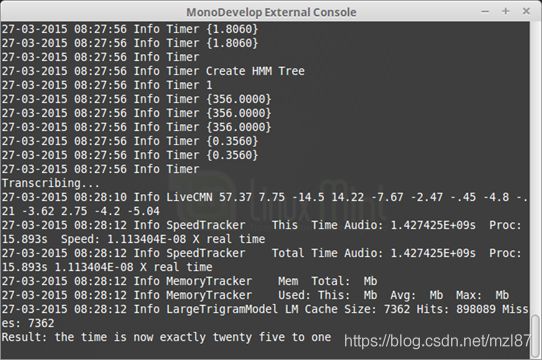
希望您已经转录了音频文件。
您可能已经注意到,该应用程序花了几秒钟来转录Long Audio 2.wav文件。这是因为我们在配置中没有使用任何语法文件。这会将搜索域缩小为有限数量的指定标记。
接下来,我们将看到如何使用语法文件来指定一组我们希望识别的单词和句子。
使用语法(JSGF)转录音频文件
要使用语法转录音频文件或流,我们首先需要创建一个语法文件duh!该库支持JSGF(JSpeech语法格式)语法文件。
JSGF的语法非常简单,它是从中最初衍生出SRGS(语音识别语法规范)的实际语法。
JSGF语法不在本文讨论范围之内。但是,我将在您前面放置一个简单的示例代码。
假设您希望识别2个离奇的孤立句子,例如:
- 现在的时间正好是12:35
- 这三个在左侧最靠近我们
您的JSGF语法文件的内容如下所示。
#JSGF V1.0;
grammar hello;
public = ( the time is now exactly twenty five to one |
this three left on the left side the one closest to us ); 有关创建JSGF语法的更多信息,请参见此处。
为简单起见,我已经为您创建了一个JSGF语法文件并将其放置在Models目录中。(名称为“hello.gram ”)。您在上面看到的内容。
要使StreamSpeechRecognizer使用我们创建的语法文件,需要在将Configuration类作为参数传递给StreamSpeechRecognizer之前设置类的3个重要属性。
speechConfiguration.UseGrammar = true;
speechConfiguration.GrammarPath = modelsDirectory;
speechConfiguration.GrammarName = "hello";- speechConfiguration.UseGrammar = true;——告诉语音识别器我们打算使用语法文件
- speechConfiguration.GrammarPath——语法文件所在的路径
- speechConfiguration.GrammarName——我们希望使用的语法名称(在Linux中区分大小写)。省略.gram扩展名,因为它是自动附加的
使用语法转录音频文件的总体代码
using System;
using Syn.Speech.Api;
using System.IO;
using Syn.Logging;
namespace Speech.Recognition.Example
{
class MainClass
{
static Configuration speechConfiguration;
static StreamSpeechRecognizer speechRecognizer;
static void LogReceived (object sender, LogReceivedEventArgs e)
{
Console.WriteLine (e.Message);
}
public static void Main (string[] args)
{
Logger.LogReceived += LogReceived;
var modelsDirectory = Path.Combine (Directory.GetCurrentDirectory (), "Models");
var audioDirectory = Path.Combine (Directory.GetCurrentDirectory (), "Audio");
var audioFile = Path.Combine (audioDirectory, "Long Audio 2.wav");
if (!Directory.Exists (modelsDirectory)||!Directory.Exists(audioDirectory)) {
Console.WriteLine ("No Models or Audio directory found!! Aborting...");
Console.ReadLine ();
return;
}
speechConfiguration = new Configuration ();
speechConfiguration.AcousticModelPath=modelsDirectory;
speechConfiguration.DictionaryPath = Path.Combine (modelsDirectory, "cmudict-en-us.dict");
speechConfiguration.LanguageModelPath = Path.Combine (modelsDirectory, "en-us.lm.dmp");
speechConfiguration.UseGrammar = true;
speechConfiguration.GrammarPath = modelsDirectory;
speechConfiguration.GrammarName = "hello";
speechRecognizer = new StreamSpeechRecognizer (speechConfiguration);
speechRecognizer.StartRecognition (new FileStream (audioFile, FileMode.Open));
Console.WriteLine ("Transcribing...");
var result = speechRecognizer.GetResult ();
if (result != null) {
Console.WriteLine ("Result: " + result.GetHypothesis ());
} else {
Console.WriteLine ("Sorry! Couldn't Transcribe");
}
Console.ReadLine ();
}
}
}如果您运行该应用程序,您将在几毫秒内录制好音频文件,并且输出仍将相同。
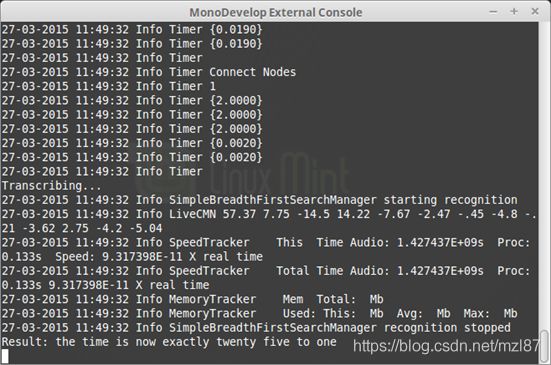
至此,我完成了此初始版本的工作。
外部资源
- GitHub Repository——外部演示项目可以在这里找到
- CMU的声学模型——包含CMU最新发布的声学模型
- GitHub中的项目文件——链接到我在其中上传了项目文件的GitHub存储库
兴趣点
转录音频文件是一个缓慢且耗时的过程。我建议坚持使用JSGF语法文件,以便更快地识别语音。但是请记住,在Linux中语法文件的名称区分大小写。
在性能方面,与Mono相比,该库在.NET Framework下的性能稍好,但是当我使用自定义大小限制的语法文件时,实际上不存在差异。
语音识别引擎可以利用卡耐基梅隆大学发布的所有声学模型。它们可在伪造源代码中找到,但我更希望使用Sphinx4项目的GitHub存储库中的最新声学模型数据。