flowable6.3功能以及性能基准测试报告
上周,我们在AWS上创建的服务器上启动和完成了超过3100万个流程实例。目的为了测试和验证即将发布的flowable6.3版本。flowable6.3版本
我们收集了大量的数据。我们对flowable6.3性能基准测试不失望:大多数的基准至少显示两位数增加吞吐量。
当然,和往常一样,在性能基准上,不要给数字数据太多的意义。基准总是及时的快照,而在硬件、设置或甚至是时间上的细微变化都可以改变结果。本文中数字和图表的主要目标是突出显示性能提升的flowable不同版本之间的相对差异。
引擎的改进
在flowable 6.3版本中已经做出了各种各样的变化,小而大。以下主要的重构已经达到了一个非常快的引擎,许多改进都集中在避免或减少对数据库服务器的网络访问上:
1、依赖实体计数。在我们的分析过程中发现了一个问题,很明显,流程实例执行运行时结构的清理通常会超过实际运行时程序所花费的时间。解决这个问题的方法是花更多的时间来排查插入或更新时间,进而计算依赖数据实体的数量,而不是花费在清理阶段的时间。这个特性在Flowable引擎中已经存在了一段时间,作为一种实验性的选择。现在已经扩展到更多的实体类型,并且在高并发性场景下已经进行了修改,以保持引擎继续正常工作。
2、复杂实体的抓取。主要示例是cmmn计划项目运行时结构或bpmn执行。通过获取多于所需的数据,对复杂数据或相关实体的其他部分进行后续调用,将受益于这种短暂的缓存。这个特性被添加到最低的数据层,并且在上面的应用层中是看不到的。
3、Cross-pollination引擎。当思考一个问题时,从另一个角度看问题往往会有所帮助。实现CMMN引擎已经给出了确切的答案。执行一个CMMN案例与执行一个结构化的流程完全不同。通过实现这个CMMN引擎,我们学到的一些东西让我们重新审视了如何优化BPMN引擎的某些部分。
4、内部的持久性。许多与持久性相关的底层类都经过了修改和优化,以便在必要时更聪明地处理这些问题。
开始测试
运行基准测试的代码可以在这里找到:https://github.com/flowable/flowable-benchmark/tree/8a804764115c476ea90f1826aab9161d27f35094/2018-03,所以你可以很容易地验证我们声称的结果。
在下面的结果中,第一个安装程序在与数据库相同的服务器上运行。在本例中,使用了以下默认配置。
1、一个AWS EC2(Ubuntu)镜像,c3.4xlarge(16个vCPUs,30块内存,SSD有供给的iop)
2、在同一台机器上,默认情况下(简单地使用apt-get安装,不调整配置)Postgres 10.2数据库。
在第二个设置中,数据库实例不在同一服务器上。运行基准测试的服务器机器与上面的相同。该数据库具有以下特点:
3、AWS Aurora(兼容MySQL 5.6)的db.r3.4xlarge。
所有服务器都位于同一区域)。
注意,这些服务器有很多RAM,但实际上并没有使用太多。Flowable不会占用太多内存,而且内存很好。例如,基准服务器在第一个设置中从未使用超过2 GB,在第二个设置中使用了1.5 GB。
我们在此使用的设置是故意简单的。通过添加更多的服务器、负载平衡器等等,我们可以做更多的事情。在解释结果时,要使用各种方法以此获得更高的测试数字。
所选择的流程定义比较简单,用于测试发动机的特定区域,因此我们可以对实际的过程执行作出有意义的结论。对于每个流程定义,都度量了结束时间以及开始时间。这意味着不仅要考虑流程实例的启动,还要查询用户任务并完成它们。从基准项目的代码中可以看出,在开始测量前,对JVM进行了充分预热。
Start to End –本地数据库: 26%-141%
让我们看一看基准测试中使用的流程定义,以及各种Flowable版本和配置的结果。
描述:第一 个“流程定义”并不是一个流程。它只是简单的开始和结束。
为什么:尽管没有执行任何功能,但是这个流程定义让我们清楚地了解了调用流引擎的开销。这是基线,其他的总是比这个慢。
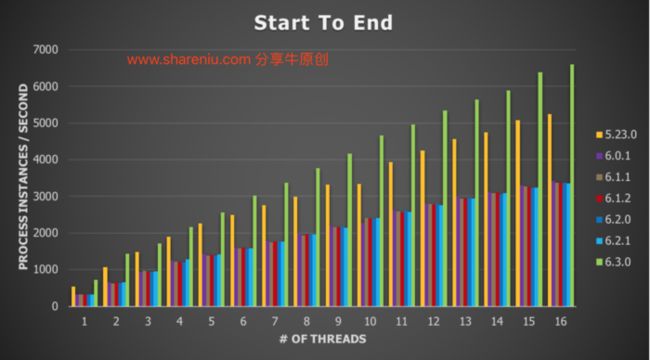
让我们看一下在同一服务器上运行基准代码和数据库时的结果:
y轴显示每秒的流程实例。在本例中,这意味着一秒钟内启动了多少个流程实例,完成了和存储在数据库中的历史记录。x轴显示在threadpool中使用的线程数。
下面的图表显示了最好的情况(16个线程):
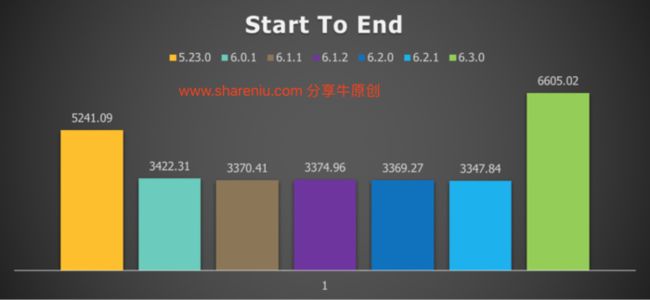
对于这个用例的结果:
1、跟V5版本相比增长了26%的吞吐量。
2、吞吐量比6.3之前的版本增加了一倍。
一些额外的说明
这些图表的其他一些观察结果如下:
1、在上一节中预测的模式(v5版本v6版本)在这里非常清楚。原因很简单:运行时数据结构的大小增加了一倍,因为在v5中只有一个执行实体,而v6有两个。这在版本5和pre-6.3.0的结果之间的差别是显而易见的。
2、但是,version 6.3.0中的优化避免了这种惩罚,并且实际上改进了它。V5版本每秒有5241.09流程实例,6.3版本每秒有6605流程实例。
3、另一个观察是,flowable可以扩展并处理并发负载。这当然是因为flowable引擎的设计是考虑到高并发性的。当添加更多的线程时,这里有一个很好的线性趋势。当然,在某些时候CPU会有物理限制,但是这个16核心的机器还没有达到那个点(我们还没有测试更多的线程,这可能会告诉我们这个临界点)。
请注意,当吞吐量增加时(我们可以在一秒钟内执行的流程实例的数量),一般来说,每个实例的平均执行时间会随着CPU和IO系统不经常进行上下文切换而上升。要考虑到我们没有给这些系统留出喘息的空间,因为我们经常不停地来轰炸他们。实际上,会有大量的停顿。但是,从图表中可以清楚地看出,随着个人平均执行时间的略微增加,系统的吞吐量在全球范围内增加。例如,我们来看看6.3 的平均计时图(我们只会展示一次,在随后的过程定义基准测试中,模式是相同
 的):
的):
同样值得注意的是:我们讨论的是一个流程实例执行的时间大概是1.5 - 2.5毫秒,这是非常低的。
在上面的数字中,历史数据(流程实例数据、开始和结束时间)被写入历史数据表,使用默认审计历史级别。让我们看看如果禁用它会发生什么:
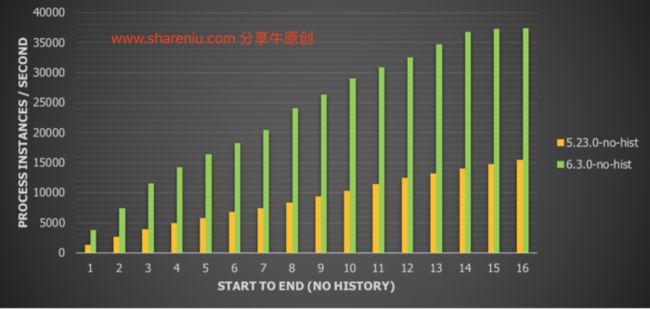
对于这个用例,我们看到吞吐量比V5增加了一倍以上(141%)。
为了清晰起见,我们忽略了6.3.0之前的结果。上面还发现了类似的模式。从这个图表可以清楚地看出,在没有历史记录的情况下,6.3.0版本比5.23.0版本要快很多。还要注意这里最好的结果(使用16个线程):37453流程实例/秒。只是把它放在一个角度来看:这是接近1.35亿的流程实例/小时。由于执行时间较低,且吞吐量非常高,因此可以安全地从这个简单流程的基准得出结论,即调用可流引擎的开销非常低。
Start to End –远程数据库: 16%-106%
上面的数字都在数据库和应用在同一个服务器上。如果数据库跟应用不在同一个服务器,那么肯定会产生网络延时,这些数字显然会改变:
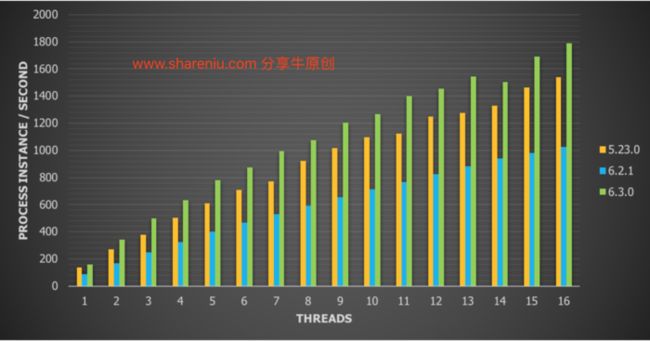
对于这个用例的结果:
3、跟V5版本相比增长了16%的吞吐量。
4、吞吐量比6.3之前的版本增长了74%。
一个即时的观察是,通过在网络上调用一个数据库(即使是AWS中设计良好的网络基础设施),也会产生巨大的影响(与第一次安装相比)。
没有历史数据记录的对应关系是这样的:
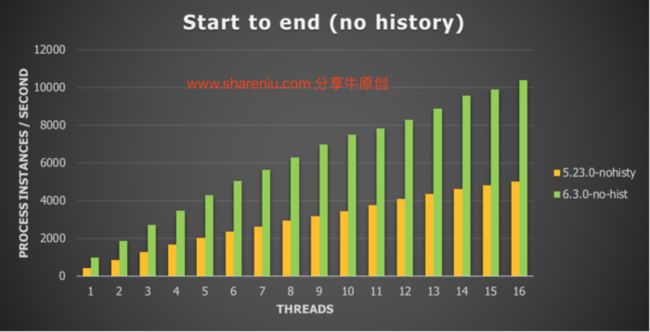
对于这个用例,我们看到吞吐量比V5增加了106%。
结论是一样的:6.3.0版本是一个显著的改进,调用引擎的开销非常低。
~~~~~~~~~~~~ 正文结束 下面没了 ~~~~~~~~~~~~
分享牛老师再出新作,倾力打造Activiti精品课程系列,以最短的时间高效完成学习目标,入门进阶与实战案例并重,是0基础的新手从入门到精通的必备课程。
《Activiti自定义设计器》------从零入门进阶的最佳课程------【点此查看详情】
《Activiti 中国式特色流程》------企业级实战视频------【点此查看详情】