faster rcnn的tensorflow代码的理解
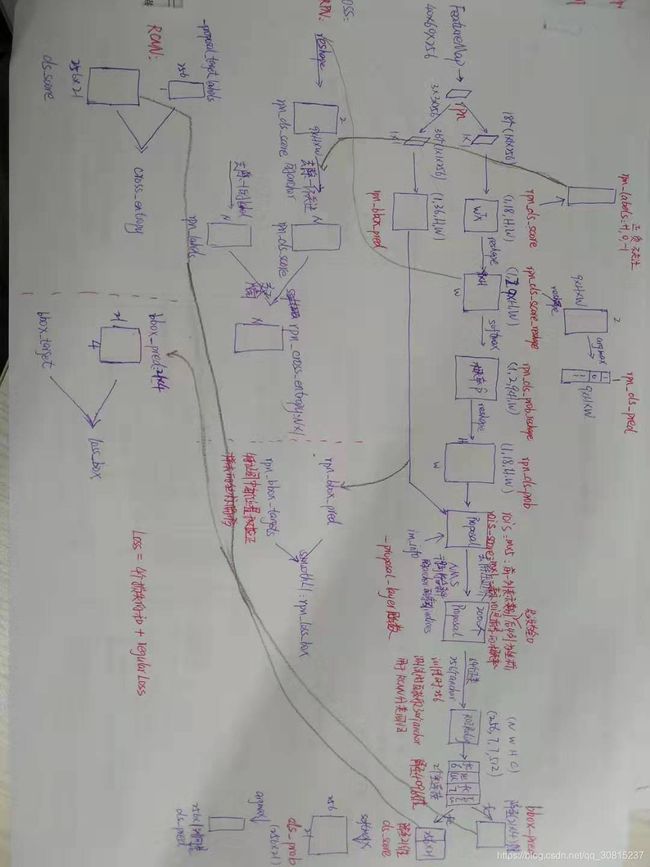
faster rcnn主要包括两部分:rpn网络和rcnn网络。rpn网络用于保留在图像内部的archors,同时得到这些archors是正样本还是负样本还是不关注。最终训练时通过nms保留最多2000个archors,测试时保留300个archors。另一方面,rpn网络会提供256个archors给rcnn网络,用于rcnn分类及回归坐标位置。
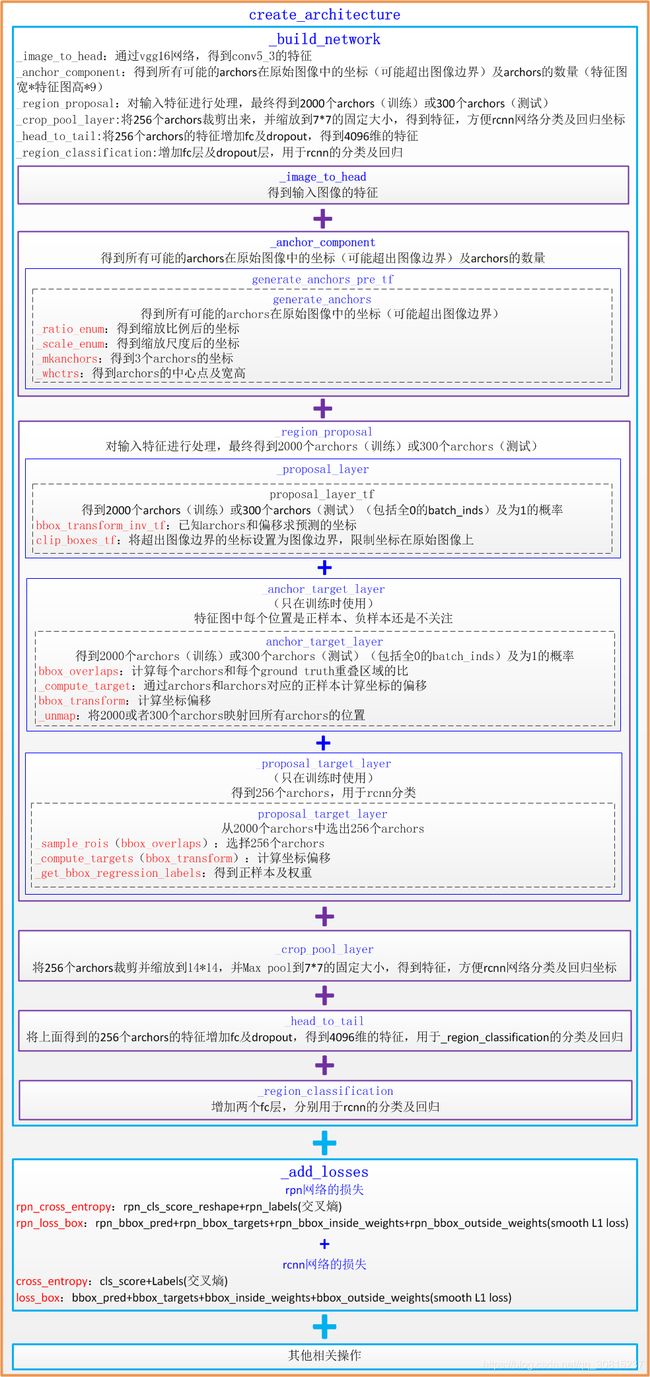
下文将主要介绍RPN网络和分类回归网络,构建网络的代码为network.py中的_build_network()函数:
def _build_network(self, is_training=True):
# select initializers
if cfg.TRAIN.TRUNCATED:
initializer = tf.truncated_normal_initializer(mean=0.0, stddev=0.01)
initializer_bbox = tf.truncated_normal_initializer(mean=0.0, stddev=0.001)
else:
initializer = tf.random_normal_initializer(mean=0.0, stddev=0.01)
initializer_bbox = tf.random_normal_initializer(mean=0.0, stddev=0.001)
net_conv = self._image_to_head(is_training)
with tf.variable_scope(self._scope, self._scope):
# build the anchors for the image
self._anchor_component()
# region proposal network
rois = self._region_proposal(net_conv, is_training, initializer)
# region of interest pooling
if cfg.POOLING_MODE == 'crop':
pool5 = self._crop_pool_layer(net_conv, rois, "pool5")
else:
raise NotImplementedError
fc7 = self._head_to_tail(pool5, is_training)
with tf.variable_scope(self._scope, self._scope):
# region classification
cls_prob, bbox_pred = self._region_classification(fc7, is_training,
initializer, initializer_bbox)
self._score_summaries.update(self._predictions)
return rois, cls_prob, bbox_pred_build_network用于创建网络
_build_network = _image_to_head + //得到输入图像的特征
_anchor_component + //得到所有可能的archors在原始图像中的坐标(可能超出图像边界)及archors的数量
_region_proposal + //对输入特征进行处理,最终得到2000个archors(训练)或300个archors(测试)
_crop_pool_layer + //将256个archors裁剪出来,并缩放到7*7的固定大小,得到特征
_head_to_tail + //将256个archors的特征增加fc及dropout,得到4096维的特征
_region_classification // 增加fc层及dropout层,用于rcnn的分类及回归
总体流程:网络通过vgg1-5得到特征net_conv后,送入rpn网络得到候选区域archors,去除超出图像边界的archors并选出2000个archors用于训练rpn网络(300个用于测试)。并进一步选择256个archors(用于rcnn分类)。之后将这256个archors的特征根据rois进行裁剪缩放及pooling,得到相同大小7*7的特征pool5,pool5通过两个fc层得到4096维特征fc7,fc7送入_region_classification(2个并列的fc层),得到21维的cls_score和21*4维的bbox_pred。
1、cfg.TRAIN.TRUNCATED
cfg是定义在model/config.py文件中,cfg中定义了动量项,学习率,衰减率等等,
__C.TRAIN.TRUNCATED = False # 是否使用截断的正态分布初始化权重 
easydict的作用:可以使得以属性的方式去访问字典的值!
>>> from easydict import EasyDict as edict
>>> d = edict({'foo':3, 'bar':{'x':1, 'y':2}})
>>> d.bar.x
1
2、tf.truncated_normal_initializer 表示从截断的正态分布中输出随机值。生成的值服从具有指定平均值和标准偏差的正态分布,如果生成的值大于平均值2个标准偏差的值则丢弃重新选择。
ARGS:
mean:一个python标量或一个标量张量。要生成的随机值的均值。
stddev:一个python标量或一个标量张量。要生成的随机值的标准偏差。
seed:一个Python整数。用于创建随机种子。查看 tf.set_random_seed 行为。
dtype:数据类型。只支持浮点类型。
这是神经网络权重和过滤器的推荐初始值。
3、tf.random_normal_initializer 用正态分布产生张量的初始化器.这两个函数的输入参数几乎完全一致,而其主要的区别在于,tf.truncated_normal的输出如字面意思是截断的,而截断的标准是2倍的stddev。
举例,当输入参数mean = 0 , stddev =1时,使用tf.truncated_normal的输出是不可能出现[-2,2]以外的点的,而如果shape够大的话,tf.random_normal却会产生2.2或者2.4之类的输出。
4、net_conv = self._image_to_head(is_training)
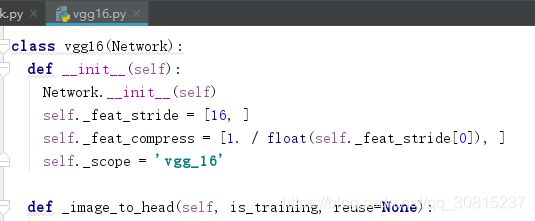
_image_to_head来自nets/vgg16.py,这个函数主要构造了vgg16网络前5组卷积层,返回一个网络结构。用于得到输入图像的特征。
5、 self._anchor_component() # 生成anchors,在network.py定义的子函数
def _anchor_component(self):
with tf.variable_scope('ANCHOR_' + self._tag) as scope:
# just to get the shape right
height = tf.to_int32(tf.ceil(self._im_info[0] / np.float32(self._feat_stride[0])))
width = tf.to_int32(tf.ceil(self._im_info[1] / np.float32(self._feat_stride[0])))
if cfg.USE_E2E_TF:
anchors, anchor_length = generate_anchors_pre_tf(
height,
width,
self._feat_stride,
self._anchor_scales,
self._anchor_ratios
)
else:
anchors, anchor_length = tf.py_func(generate_anchors_pre,
[height, width,
self._feat_stride, self._anchor_scales, self._anchor_ratios],
[tf.float32, tf.int32], name="generate_anchors")
anchors.set_shape([None, 4])
anchor_length.set_shape([])
self._anchors = anchors #赋值
self._anchor_length = anchor_length #赋值5.1、_tag。。。。。。
5.2、_im_info,在network.py文件中:

查找blobs函数,在minibatch.py文件中:

_get_image_blob定义在test.py文件中,返回值为:
5.3、_feat_stride[0]在vgg16.py文件中,表示一共缩放了16倍
height = tf.to_int32(tf.ceil(self._im_info[0] / np.float32(self._feat_stride[0])))
width = tf.to_int32(tf.ceil(self._im_info[1] / np.float32(self._feat_stride[0])))
得到输出的特征图的尺寸5.4、_anchor_scales由create_architecture函数定义

5.5、generate_anchors_pre_tf函数定义在layer_utils/snippets.py文件
函数调用了generate_anchors函数,该函数定义在layer_utils/generate_anchors.py文件中,用于产生anchor框。
generate_anchors_pre_tf函数,返回 return tf.cast(anchors_tf, dtype=tf.float32)(框的坐标点位置), length(框的个数)
总结:_anchor_component:用于得到所有可能的archors在原始图像中的坐标(可能超出图像边界)及archors的数量(特征图宽*特征图高*9)。该函数使用的self._im_info,为一个3维向量,[0]代表图像宽,[1]代表图像高,[2]代表图像缩放的比例(将图像宽缩放到600,或高缩放到1000的最小比例,比如缩放到600*900、850*1000)。该函数调用generate_anchors_pre_tf并进一步调用generate_anchors来得到所有可能的archors在原始图像中的坐标及archors的个数(由于图像大小不一样,因而最终archor的个数也不一样)。
generate_anchors_pre_tf步骤如下:1. 通过_ratio_enum得到archor时,使用 (0, 0, 15, 15) 的基准窗口,先通过ratio=[0.5,1,2]的比例得到archors。ratio指的是像素总数(宽*高)的比例,而不是宽或者高的比例,得到如下三个archor(每个archor为左上角和右下角的坐标):

2. 而后在通过scales=(8, 16, 32)得到放大倍数后的archors。scales时,将上面的每个都直接放大对应的倍数,最终得到9个archors(每个archor为左上角和右下角的坐标)。将上面三个archors分别放大就行了。
3. 之后通过tf.add(anchor_constant, shifts)得到缩放后的每个点的9个archor在原始图的矩形框。anchor_constant:1*9*4。shifts:N*1*4。N为缩放后特征图的像素数。将维度从N*9*4变换到(N*9)*4,得到缩放后的图像每个点在原始图像中的archors。
def _anchor_component(self):
with tf.variable_scope('ANCHOR_' + self._tag) as scope:
height = tf.to_int32(tf.ceil(self._im_info[0] / np.float32(self._feat_stride[0]))) # 图像经过vgg16得到特征图的宽高
width = tf.to_int32(tf.ceil(self._im_info[1] / np.float32(self._feat_stride[0])))
if cfg.USE_E2E_TF:
# 通过特征图宽高、_feat_stride(特征图相对原始图缩小的比例)及_anchor_scales、_anchor_ratios得到原始图像上
# 所有可能的archors(坐标可能超出原始图像边界)和archor的数量
anchors, anchor_length = generate_anchors_pre_tf(height, width, self._feat_stride, self._anchor_scales, self._anchor_ratios )
else:
anchors, anchor_length = tf.py_func(generate_anchors_pre,
[height, width, self._feat_stride, self._anchor_scales, self._anchor_ratios], [tf.float32, tf.int32], name="generate_anchors")
anchors.set_shape([None, 4]) # 起点坐标,终点坐标,共4个值
anchor_length.set_shape([])
self._anchors = anchors
self._anchor_length = anchor_length
def generate_anchors_pre_tf(height, width, feat_stride=16, anchor_scales=(8, 16, 32), anchor_ratios=(0.5, 1, 2)):
shift_x = tf.range(width) * feat_stride # 得到所有archors在原始图像的起始x坐标:(0,feat_stride,2*feat_stride...)
shift_y = tf.range(height) * feat_stride # 得到所有archors在原始图像的起始y坐标:(0,feat_stride,2*feat_stride...)
shift_x, shift_y = tf.meshgrid(shift_x, shift_y) # shift_x:height个(0,feat_stride,2*feat_stride...);shift_y:width个(0,feat_stride,2*feat_stride...)'
sx = tf.reshape(shift_x, shape=(-1,)) # 0,feat_stride,2*feat_stride...0,feat_stride,2*feat_stride...0,feat_stride,2*feat_stride...
sy = tf.reshape(shift_y, shape=(-1,)) # 0,0,0...feat_stride,feat_stride,feat_stride...2*feat_stride,2*feat_stride,2*feat_stride..
shifts = tf.transpose(tf.stack([sx, sy, sx, sy])) # width*height个四位矩阵
K = tf.multiply(width, height) # 特征图总共像素数
shifts = tf.transpose(tf.reshape(shifts, shape=[1, K, 4]), perm=(1, 0, 2)) # 增加一维,变成1*(width*height)*4矩阵,而后变换维度为(width*height)*1*4矩阵
anchors = generate_anchors(ratios=np.array(anchor_ratios), scales=np.array(anchor_scales)) #得到9个archors的在原始图像中的四个坐标(放大比例默认为16)
A = anchors.shape[0] # A=9
anchor_constant = tf.constant(anchors.reshape((1, A, 4)), dtype=tf.int32) # anchors增加维度为1*9*4
length = K * A # 总共的archors的个数(每个点对应A=9个archor,共K=height*width个点)
# 1*9*4的base archors和(width*height)*1*4的偏移矩阵进行broadcast相加,得到(width*height)*9*4,并改变形状为(width*height*9)*4,得到所有的archors的四个坐标
anchors_tf = tf.reshape(tf.add(anchor_constant, shifts), shape=(length, 4))
return tf.cast(anchors_tf, dtype=tf.float32), length
def generate_anchors(base_size=16, ratios=[0.5, 1, 2], scales=2 ** np.arange(3, 6)):
"""Generate anchor (reference) windows by enumerating aspect ratios X scales wrt a reference (0, 0, 15, 15) window."""
base_anchor = np.array([1, 1, base_size, base_size]) - 1 # base archor的四个坐标
ratio_anchors = _ratio_enum(base_anchor, ratios) # 通过ratio得到3个archors的坐标(3*4矩阵)
anchors = np.vstack([_scale_enum(ratio_anchors[i, :], scales) for i in range(ratio_anchors.shape[0])]) # 3*4矩阵变成9*4矩阵,得到9个archors的坐标
return anchors
def _whctrs(anchor):
""" Return width, height, x center, and y center for an anchor (window). """
w = anchor[2] - anchor[0] + 1 # 宽
h = anchor[3] - anchor[1] + 1 # 高
x_ctr = anchor[0] + 0.5 * (w - 1) # 中心x
y_ctr = anchor[1] + 0.5 * (h - 1) # 中心y
return w, h, x_ctr, y_ctr
def _mkanchors(ws, hs, x_ctr, y_ctr):
""" Given a vector of widths (ws) and heights (hs) around a center (x_ctr, y_ctr), output a set of anchors (windows)."""
ws = ws[:, np.newaxis] # 3维向量变成3*1矩阵
hs = hs[:, np.newaxis] # 3维向量变成3*1矩阵
anchors = np.hstack((x_ctr - 0.5 * (ws - 1), y_ctr - 0.5 * (hs - 1), x_ctr + 0.5 * (ws - 1), y_ctr + 0.5 * (hs - 1))) # 3*4矩阵
return anchors
def _ratio_enum(anchor, ratios): # 缩放比例为像素总数的比例,而非单独宽或者高的比例
""" Enumerate a set of anchors for each aspect ratio wrt an anchor. """
w, h, x_ctr, y_ctr = _whctrs(anchor) # 得到中心位置和宽高
size = w * h # 总共像素数
size_ratios = size / ratios # 缩放比例
ws = np.round(np.sqrt(size_ratios)) # 缩放后的宽,3维向量(值由大到小)
hs = np.round(ws * ratios) # 缩放后的高,两个3维向量对应元素相乘,为3维向量(值由小到大)
anchors = _mkanchors(ws, hs, x_ctr, y_ctr) # 根据中心及宽高得到3个archors的四个坐标
return anchors
def _scale_enum(anchor, scales):
""" Enumerate a set of anchors for each scale wrt an anchor. """
w, h, x_ctr, y_ctr = _whctrs(anchor) # 得到中心位置和宽高
ws = w * scales # 得到宽的放大倍数
hs = h * scales # 得到宽的放大倍数
anchors = _mkanchors(ws, hs, x_ctr, y_ctr) # 根据中心及宽高得到3个archors的四个坐标
return anchors6、 rois = self._region_proposal(net_conv, is_training, initializer) # RPN网络,_region_proposal定义在network.py文件,调用_softmax_layer函数计算损失函数。
_region_proposal用于将vgg16的conv5的特征通过3*3的滑动窗得到rpn特征,进行两条并行的线路,分别送入cls和reg网络。cls网络判断通过1*1的卷积得到archors是正样本还是负样本(由于archors过多,还有可能有不关心的archors,使用时只使用正样本和负样本),用于二分类rpn_cls_score;
reg网络对通过1*1的卷积回归出archors的坐标偏移rpn_bbox_pred。这两个网络共用3*3 conv(rpn)。由于每个位置有k个archor,因而每个位置均有2k个soores和4k个coordinates。
cls(将输入的512维降低到2k维):3*3 conv + 1*1 conv(2k个scores,k为每个位置archors个数,如9)
在第一次使用_reshape_layer时,由于输入bottom为1*?*?*18,先得到caffe中的数据顺序(tf为batchsize*height*width*channels,caffe中为batchsize*channels*height*width)to_caffe:1*18*?*?,而后reshape后得到reshaped为1*2*?*?,最后在转回tf的顺序to_tf为1*?*?*2,得到rpn_cls_score_reshape。之后通过rpn_cls_prob_reshape(softmax的值,只针对最后一维,即2计算softmax),得到概率rpn_cls_prob_reshape(其最大值,即为预测值rpn_cls_pred),再次_reshape_layer,得到1*?*?*18的rpn_cls_prob,为原始的概率。
reg(将输入的512维降低到4k维):3*3 conv + 1*1 conv(4k个coordinates,k为每个位置archors个数,如9)。
def _region_proposal(self, net_conv, is_training, initializer): # 对输入特征图进行处理
rpn = slim.conv2d(net_conv, cfg.RPN_CHANNELS, [3, 3], trainable=is_training, weights_initializer=initializer, scope="rpn_conv/3x3") #3*3的conv,作为rpn网络
self._act_summaries.append(rpn)
rpn_cls_score = slim.conv2d(rpn, self._num_anchors * 2, [1, 1], trainable=is_training, weights_initializer=initializer, # _num_anchors为9
padding='VALID', activation_fn=None, scope='rpn_cls_score') #1*1的conv,得到每个位置的9个archors分类特征1*?*?*(9*2)(二分类),判断当前archors是正样本还是负样本
rpn_cls_score_reshape = self._reshape_layer(rpn_cls_score, 2, 'rpn_cls_score_reshape') # 1*?*?*18==>1*(?*9)*?*2
rpn_cls_prob_reshape = self._softmax_layer(rpn_cls_score_reshape, "rpn_cls_prob_reshape") # 以最后一维为特征长度,得到所有特征的概率1*(?*9)*?*2
rpn_cls_pred = tf.argmax(tf.reshape(rpn_cls_score_reshape, [-1, 2]), axis=1, name="rpn_cls_pred") # 得到每个位置的9个archors预测的类别,(1*?*9*?)的列向量
rpn_cls_prob = self._reshape_layer(rpn_cls_prob_reshape, self._num_anchors * 2, "rpn_cls_prob") # 变换会原始维度1*(?*9)*?*2==>1*?*?*(9*2)
rpn_bbox_pred = slim.conv2d(rpn, self._num_anchors * 4, [1, 1], trainable=is_training, weights_initializer=initializer,
padding='VALID', activation_fn=None, scope='rpn_bbox_pred') #1*1的conv,每个位置的9个archors回归位置偏移1*?*?*(9*4)
if is_training:
# 每个位置的9个archors的类别概率和每个位置的9个archors的回归位置偏移得到post_nms_topN=2000个archors的位置(包括全0的batch_inds)及为1的概率
rois, roi_scores = self._proposal_layer(rpn_cls_prob, rpn_bbox_pred, "rois")
rpn_labels = self._anchor_target_layer(rpn_cls_score, "anchor") # rpn_labels:特征图中每个位置对应的是正样本、负样本还是不关注
with tf.control_dependencies([rpn_labels]): # Try to have a deterministic order for the computing graph, for reproducibility
rois, _ = self._proposal_target_layer(rois, roi_scores, "rpn_rois") #通过post_nms_topN个archors的位置及为1(正样本)的概率得到256个rois(第一列的全0更新为每个archors对应的类别)及对应信息
else:
if cfg.TEST.MODE == 'nms':
# 每个位置的9个archors的类别概率和每个位置的9个archors的回归位置偏移得到post_nms_topN=300个archors的位置(包括全0的batch_inds)及为1的概率
rois, _ = self._proposal_layer(rpn_cls_prob, rpn_bbox_pred, "rois")
elif cfg.TEST.MODE == 'top':
rois, _ = self._proposal_top_layer(rpn_cls_prob, rpn_bbox_pred, "rois")
else:
raise NotImplementedError
self._predictions["rpn_cls_score"] = rpn_cls_score # 每个位置的9个archors是正样本还是负样本
self._predictions["rpn_cls_score_reshape"] = rpn_cls_score_reshape # 每个archors是正样本还是负样本
self._predictions["rpn_cls_prob"] = rpn_cls_prob # 每个位置的9个archors是正样本和负样本的概率
self._predictions["rpn_cls_pred"] = rpn_cls_pred # 每个位置的9个archors预测的类别,(1*?*9*?)的列向量
self._predictions["rpn_bbox_pred"] = rpn_bbox_pred # 每个位置的9个archors回归位置偏移
self._predictions["rois"] = rois # 256个archors的类别(第一维)及位置(后四维)
return rois # 返回256个archors的类别(第一维,训练时为每个archors的类别,测试时全0)及位置(后四维)
def _reshape_layer(self, bottom, num_dim, name):
input_shape = tf.shape(bottom)
with tf.variable_scope(name) as scope:
to_caffe = tf.transpose(bottom, [0, 3, 1, 2]) # NHWC(TF数据格式)变成NCHW(caffe格式)
reshaped = tf.reshape(to_caffe, tf.concat(axis=0, values=[[1, num_dim, -1], [input_shape[2]]])) # 1*(num_dim*9)*?*?==>1*num_dim*(9*?)*? 或 1*num_dim*(9*?)*?==>1*(num_dim*9)*?*?
to_tf = tf.transpose(reshaped, [0, 2, 3, 1])
return to_tf
def _softmax_layer(self, bottom, name):
if name.startswith('rpn_cls_prob_reshape'): # bottom:1*(?*9)*?*2
input_shape = tf.shape(bottom)
bottom_reshaped = tf.reshape(bottom, [-1, input_shape[-1]]) # 只保留最后一维,用于计算softmax的概率,其他的全合并:1*(?*9)*?*2==>(1*?*9*?)*2
reshaped_score = tf.nn.softmax(bottom_reshaped, name=name) # 得到所有特征的概率
return tf.reshape(reshaped_score, input_shape) # (1*?*9*?)*2==>1*(?*9)*?*2
return tf.nn.softmax(bottom, name=name)
rpn_cls_pred = tf.argmax(tf.reshape(rpn_cls_score_reshape, [-1, 2]), axis=1, name="rpn_cls_pred")
tf.reshape(rpn_cls_score_reshape, [-1, 2])把rpn_cls_score_reshape(1,2,9*H,W)变形为(9*H*W,2)的矩阵;argmax,在矩阵行中最大值的索引,返回一个(9*H*W,1)的列向量,向量中元素值为0,1,分别代表9*H*W个anchor属于前景还是背景。
6.1、_proposal_layer
rois, roi_scores = self._proposal_layer(rpn_cls_prob, rpn_bbox_pred, "rois")
_proposal_layer调用proposal_layer_tf,通过(N*9)*4个archors,计算估计后的坐标(bbox_transform_inv_tf),并对坐标进行裁剪(clip_boxes_tf)及非极大值抑制(tf.image.non_max_suppression,得到符合条件的索引indices的archors:rois及这些archors为正样本的概率:rpn_scores。rois为m*5维(后四位是roi的两个坐标点,第一位是标志位,先设为全0),rpn_scores为m*1维,其中m为经过非极大值抑制后得到的候选区域个数(训练时2000个,测试时300个)。m*5的第一列为全为0的batch_inds,后4列为坐标(坐上+右下)
def _proposal_layer(self, rpn_cls_prob, rpn_bbox_pred, name): #每个位置的9个archors的类别概率和每个位置的9个archors的回归位置偏移得到post_nms_topN个archors的位置及为1的概率
with tf.variable_scope(name) as scope:
if cfg.USE_E2E_TF: # post_nms_topN*5的rois(第一列为全0的batch_inds,后4列为坐标);rpn_scores:post_nms_topN*1个对应的为1的概率
rois, rpn_scores = proposal_layer_tf(rpn_cls_prob, rpn_bbox_pred, self._im_info, self._mode, self._feat_stride, self._anchors, self._num_anchors)
else:
rois, rpn_scores = tf.py_func(proposal_layer, [rpn_cls_prob, rpn_bbox_pred, self._im_info, self._mode,
self._feat_stride, self._anchors, self._num_anchors], [tf.float32, tf.float32], name="proposal")
rois.set_shape([None, 5])
rpn_scores.set_shape([None, 1])
return rois, rpn_scores
def proposal_layer_tf(rpn_cls_prob, rpn_bbox_pred, im_info, cfg_key, _feat_stride, anchors, num_anchors): #每个位置的9个archors的类别概率和每个位置的9个archors的回归位置偏移
if type(cfg_key) == bytes:
cfg_key = cfg_key.decode('utf-8')
pre_nms_topN = cfg[cfg_key].RPN_PRE_NMS_TOP_N
post_nms_topN = cfg[cfg_key].RPN_POST_NMS_TOP_N # 训练时为2000,测试时为300
nms_thresh = cfg[cfg_key].RPN_NMS_THRESH # nms的阈值,为0.7
scores = rpn_cls_prob[:, :, :, num_anchors:] # 1*?*?*(9*2)取后9个:1*?*?*9。应该是前9个代表9个archors为背景景的概率,后9个代表9个archors为前景的概率(二分类,只有背景和前景)
scores = tf.reshape(scores, shape=(-1,)) # 所有的archors为1的概率
rpn_bbox_pred = tf.reshape(rpn_bbox_pred, shape=(-1, 4)) # 所有的archors的四个坐标
proposals = bbox_transform_inv_tf(anchors, rpn_bbox_pred) # 已知archor和偏移求预测的坐标
proposals = clip_boxes_tf(proposals, im_info[:2]) # 限制预测坐标在原始图像上
indices = tf.image.non_max_suppression(proposals, scores, max_output_size=post_nms_topN, iou_threshold=nms_thresh) # 通过nms得到分值最大的post_nms_topN个坐标的索引
boxes = tf.gather(proposals, indices) # 得到post_nms_topN个对应的坐标
boxes = tf.to_float(boxes)
scores = tf.gather(scores, indices) # 得到post_nms_topN个对应的为1的概率
scores = tf.reshape(scores, shape=(-1, 1))
batch_inds = tf.zeros((tf.shape(indices)[0], 1), dtype=tf.float32) # Only support single image as input
blob = tf.concat([batch_inds, boxes], 1) # post_nms_topN*1个batch_inds和post_nms_topN*4个坐标concat,得到post_nms_topN*5的blob
return blob, scores
def bbox_transform_inv_tf(boxes, deltas): # 已知archor和偏移求预测的坐标
boxes = tf.cast(boxes, deltas.dtype)
widths = tf.subtract(boxes[:, 2], boxes[:, 0]) + 1.0 # 宽
heights = tf.subtract(boxes[:, 3], boxes[:, 1]) + 1.0 # 高
ctr_x = tf.add(boxes[:, 0], widths * 0.5) # 中心x
ctr_y = tf.add(boxes[:, 1], heights * 0.5) # 中心y
dx = deltas[:, 0] # 预测的dx
dy = deltas[:, 1] # 预测的dy
dw = deltas[:, 2] # 预测的dw
dh = deltas[:, 3] # 预测的dh
pred_ctr_x = tf.add(tf.multiply(dx, widths), ctr_x) # 公式2已知xa,wa,tx反过来求预测的x中心坐标
pred_ctr_y = tf.add(tf.multiply(dy, heights), ctr_y) # 公式2已知ya,ha,ty反过来求预测的y中心坐标
pred_w = tf.multiply(tf.exp(dw), widths) # 公式2已知wa,tw反过来求预测的w
pred_h = tf.multiply(tf.exp(dh), heights) # 公式2已知ha,th反过来求预测的h
pred_boxes0 = tf.subtract(pred_ctr_x, pred_w * 0.5) # 预测的框的起始和终点四个坐标
pred_boxes1 = tf.subtract(pred_ctr_y, pred_h * 0.5)
pred_boxes2 = tf.add(pred_ctr_x, pred_w * 0.5)
pred_boxes3 = tf.add(pred_ctr_y, pred_h * 0.5)
return tf.stack([pred_boxes0, pred_boxes1, pred_boxes2, pred_boxes3], axis=1)
def clip_boxes_tf(boxes, im_info): # 限制预测坐标在原始图像上
b0 = tf.maximum(tf.minimum(boxes[:, 0], im_info[1] - 1), 0)
b1 = tf.maximum(tf.minimum(boxes[:, 1], im_info[0] - 1), 0)
b2 = tf.maximum(tf.minimum(boxes[:, 2], im_info[1] - 1), 0)
b3 = tf.maximum(tf.minimum(boxes[:, 3], im_info[0] - 1), 0)
return tf.stack([b0, b1, b2, b3], axis=1)6.2、rpn_labels = self._anchor_target_layer(rpn_cls_score, "anchor")
通过_anchor_target_layer首先去除archors中边界超出图像的archors。而后通过bbox_overlaps计算archors(N*4)和gt_boxes(M*4)的重叠区域的值overlaps(N*M),并得到每个archor对应的最大的重叠ground_truth的值max_overlaps(1*N),以及ground_truth的背景对应的最大重叠archors的值gt_max_overlaps(1*M)和每个背景对应的archor的位置gt_argmax_overlaps。之后通过_compute_targets计算anchors和最大重叠位置的gt_boxes的变换后的坐标bbox_targets(见公式2后四个)。最后通过_unmap在变换回和原始的archors一样大小的rpn_labels(archors是正样本、负样本还是不关注)。将archors对应的正样本的重叠区域中小于阈值的置0;将archors对应的正样本的重叠区域中大于阈值的置1;如果有过多的正样本,将多于的正样本设置为不关注
def _anchor_target_layer(self, rpn_cls_score, name): # rpn_cls_score:每个位置的9个archors分类特征1*?*?*(9*2)
with tf.variable_scope(name) as scope:
# rpn_labels; 特征图中每个位置对应的是正样本、负样本还是不关注(去除了边界在图像外面的archors)
# rpn_bbox_targets:# 特征图中每个位置和对应的正样本的坐标偏移(很多为0)
# rpn_bbox_inside_weights: 正样本的权重为1(去除负样本和不关注的样本,均为0)
# rpn_bbox_outside_weights: 正样本和负样本(不包括不关注的样本)归一化的权重
rpn_labels, rpn_bbox_targets, rpn_bbox_inside_weights, rpn_bbox_outside_weights = tf.py_func(
anchor_target_layer, [rpn_cls_score, self._gt_boxes, self._im_info, self._feat_stride, self._anchors, self._num_anchors],
[tf.float32, tf.float32, tf.float32, tf.float32], name="anchor_target")
rpn_labels.set_shape([1, 1, None, None])
rpn_bbox_targets.set_shape([1, None, None, self._num_anchors * 4])
rpn_bbox_inside_weights.set_shape([1, None, None, self._num_anchors * 4])
rpn_bbox_outside_weights.set_shape([1, None, None, self._num_anchors * 4])
rpn_labels = tf.to_int32(rpn_labels, name="to_int32")
self._anchor_targets['rpn_labels'] = rpn_labels # 特征图中每个位置对应的是正样本、负样本还是不关注(去除了边界在图像外面的archors)
self._anchor_targets['rpn_bbox_targets'] = rpn_bbox_targets # 特征图中每个位置和对应的正样本的坐标偏移(很多为0)
self._anchor_targets['rpn_bbox_inside_weights'] = rpn_bbox_inside_weights # 正样本的权重为1(去除负样本和不关注的样本,均为0)
self._anchor_targets['rpn_bbox_outside_weights'] = rpn_bbox_outside_weights # 正样本和负样本(不包括不关注的样本)归一化的权重
self._score_summaries.update(self._anchor_targets)
return rpn_labels
def anchor_target_layer(rpn_cls_score, gt_boxes, im_info, _feat_stride, all_anchors, num_anchors):# 1*?*?*(9*2); ?*5; 3; [16], ?*4; [9]
"""Same as the anchor target layer in original Fast/er RCNN """
A = num_anchors # [9]
total_anchors = all_anchors.shape[0] # 所有archors的个数,9*特征图宽*特征图高 个
K = total_anchors / num_anchors
_allowed_border = 0 # allow boxes to sit over the edge by a small amount
height, width = rpn_cls_score.shape[1:3] # rpn网络得到的特征的高宽
inds_inside = np.where( # 所有archors边界可能超出图像,取在图像内部的archors的索引
(all_anchors[:, 0] >= -_allowed_border) & (all_anchors[:, 1] >= -_allowed_border) &
(all_anchors[:, 2] < im_info[1] + _allowed_border) & # width
(all_anchors[:, 3] < im_info[0] + _allowed_border) # height
)[0]
anchors = all_anchors[inds_inside, :] # 得到在图像内部archors的坐标
labels = np.empty((len(inds_inside),), dtype=np.float32) # label: 1 正样本, 0 负样本, -1 不关注
labels.fill(-1)
# 计算每个anchors:n*4和每个真实位置gt_boxes:m*4的重叠区域的比的矩阵:n*m
overlaps = bbox_overlaps(np.ascontiguousarray(anchors, dtype=np.float), np.ascontiguousarray(gt_boxes, dtype=np.float))
argmax_overlaps = overlaps.argmax(axis=1) # 找到每行最大值的位置,即每个archors对应的正样本的位置,得到n维的行向量
max_overlaps = overlaps[np.arange(len(inds_inside)), argmax_overlaps] # 取出每个archors对应的正样本的重叠区域,n维向量
gt_argmax_overlaps = overlaps.argmax(axis=0) # 找到每列最大值的位置,即每个真实位置对应的archors的位置,得到m维的行向量
gt_max_overlaps = overlaps[gt_argmax_overlaps, np.arange(overlaps.shape[1])] # 取出每个真实位置对应的archors的重叠区域,m维向量
gt_argmax_overlaps = np.where(overlaps == gt_max_overlaps)[0] # 得到从小到大顺序的位置
if not cfg.TRAIN.RPN_CLOBBER_POSITIVES: # assign bg labels first so that positive labels can clobber them first set the negatives
labels[max_overlaps < cfg.TRAIN.RPN_NEGATIVE_OVERLAP] = 0 # 将archors对应的正样本的重叠区域中小于阈值的置0
labels[gt_argmax_overlaps] = 1 # fg label: for each gt, anchor with highest overlap 每个真实位置对应的archors置1
labels[max_overlaps >= cfg.TRAIN.RPN_POSITIVE_OVERLAP] = 1 # fg label: above threshold IOU 将archors对应的正样本的重叠区域中大于阈值的置1
if cfg.TRAIN.RPN_CLOBBER_POSITIVES: # assign bg labels last so that negative labels can clobber positives
labels[max_overlaps < cfg.TRAIN.RPN_NEGATIVE_OVERLAP] = 0
# 如果有过多的正样本,则只随机选择num_fg=0.5*256=128个正样本
num_fg = int(cfg.TRAIN.RPN_FG_FRACTION * cfg.TRAIN.RPN_BATCHSIZE) # subsample positive labels if we have too many
fg_inds = np.where(labels == 1)[0]
if len(fg_inds) > num_fg:
disable_inds = npr.choice(fg_inds, size=(len(fg_inds) - num_fg), replace=False)
labels[disable_inds] = -1 # 将多于的正样本设置为不关注
# 如果有过多的负样本,则只随机选择 num_bg=256-正样本个数 个负样本
num_bg = cfg.TRAIN.RPN_BATCHSIZE - np.sum(labels == 1) # subsample negative labels if we have too many
bg_inds = np.where(labels == 0)[0]
if len(bg_inds) > num_bg:
disable_inds = npr.choice(bg_inds, size=(len(bg_inds) - num_bg), replace=False)
labels[disable_inds] = -1 # 将多于的负样本设置为不关注
bbox_targets = np.zeros((len(inds_inside), 4), dtype=np.float32)
bbox_targets = _compute_targets(anchors, gt_boxes[argmax_overlaps, :]) # 通过archors和archors对应的正样本计算坐标的偏移
bbox_inside_weights = np.zeros((len(inds_inside), 4), dtype=np.float32)
bbox_inside_weights[labels == 1, :] = np.array(cfg.TRAIN.RPN_BBOX_INSIDE_WEIGHTS) # 正样本的四个坐标的权重均设置为1
bbox_outside_weights = np.zeros((len(inds_inside), 4), dtype=np.float32)
if cfg.TRAIN.RPN_POSITIVE_WEIGHT < 0: # uniform weighting of examples (given non-uniform sampling)
num_examples = np.sum(labels >= 0) # 正样本和负样本的总数(去除不关注的样本)
positive_weights = np.ones((1, 4)) * 1.0 / num_examples # 归一化的权重
negative_weights = np.ones((1, 4)) * 1.0 / num_examples # 归一化的权重
else:
assert ((cfg.TRAIN.RPN_POSITIVE_WEIGHT > 0) & (cfg.TRAIN.RPN_POSITIVE_WEIGHT < 1))
positive_weights = (cfg.TRAIN.RPN_POSITIVE_WEIGHT / np.sum(labels == 1))
negative_weights = ((1.0 - cfg.TRAIN.RPN_POSITIVE_WEIGHT) / np.sum(labels == 0))
bbox_outside_weights[labels == 1, :] = positive_weights # 归一化的权重
bbox_outside_weights[labels == 0, :] = negative_weights # 归一化的权重
# 由于上面使用了inds_inside,此处将labels,bbox_targets,bbox_inside_weights,bbox_outside_weights映射到原始的archors(包含未知
# 参数超出图像边界的archors)对应的labels,bbox_targets,bbox_inside_weights,bbox_outside_weights,同时将不需要的填充fill的值
labels = _unmap(labels, total_anchors, inds_inside, fill=-1)
bbox_targets = _unmap(bbox_targets, total_anchors, inds_inside, fill=0)
bbox_inside_weights = _unmap(bbox_inside_weights, total_anchors, inds_inside, fill=0) # 所有archors中正样本的四个坐标的权重均设置为1,其他为0
bbox_outside_weights = _unmap(bbox_outside_weights, total_anchors, inds_inside, fill=0)
labels = labels.reshape((1, height, width, A)).transpose(0, 3, 1, 2) # (1*?*?)*9==>1*?*?*9==>1*9*?*?
labels = labels.reshape((1, 1, A * height, width)) # 1*9*?*?==>1*1*(9*?)*?
rpn_labels = labels # 特征图中每个位置对应的是正样本、负样本还是不关注(去除了边界在图像外面的archors)
bbox_targets = bbox_targets.reshape((1, height, width, A * 4)) # 1*(9*?)*?*4==>1*?*?*(9*4)
rpn_bbox_targets = bbox_targets # 特征图中每个位置和对应的正样本的坐标偏移(很多为0)
bbox_inside_weights = bbox_inside_weights.reshape((1, height, width, A * 4)) # 1*(9*?)*?*4==>1*?*?*(9*4)
rpn_bbox_inside_weights = bbox_inside_weights
bbox_outside_weights = bbox_outside_weights.reshape((1, height, width, A * 4)) # 1*(9*?)*?*4==>1*?*?*(9*4)
rpn_bbox_outside_weights = bbox_outside_weights # 归一化的权重
return rpn_labels, rpn_bbox_targets, rpn_bbox_inside_weights, rpn_bbox_outside_weights
def _unmap(data, count, inds, fill=0):
""" Unmap a subset of item (data) back to the original set of items (of size count) """
if len(data.shape) == 1:
ret = np.empty((count,), dtype=np.float32) # 得到1维矩阵
ret.fill(fill) # 默认填充fill的值
ret[inds] = data # 有效位置填充具体数据
else:
ret = np.empty((count,) + data.shape[1:], dtype=np.float32) # 得到对应维数的矩阵
ret.fill(fill) # 默认填充fill的值
ret[inds, :] = data # 有效位置填充具体数据
return ret
def _compute_targets(ex_rois, gt_rois):
"""Compute bounding-box regression targets for an image."""
assert ex_rois.shape[0] == gt_rois.shape[0]
assert ex_rois.shape[1] == 4
assert gt_rois.shape[1] == 5
# 通过公式2后四个,结合archor和对应的正样本的坐标计算坐标的偏移
return bbox_transform(ex_rois, gt_rois[:, :4]).astype(np.float32, copy=False) # 由于gt_rois是5列,去掉最后一列的batch_inds
def bbox_transform(ex_rois, gt_rois):
ex_widths = ex_rois[:, 2] - ex_rois[:, 0] + 1.0 # archor的宽
ex_heights = ex_rois[:, 3] - ex_rois[:, 1] + 1.0 # archor的高
ex_ctr_x = ex_rois[:, 0] + 0.5 * ex_widths #archor的中心x
ex_ctr_y = ex_rois[:, 1] + 0.5 * ex_heights #archor的中心y
gt_widths = gt_rois[:, 2] - gt_rois[:, 0] + 1.0 # 真实正样本w
gt_heights = gt_rois[:, 3] - gt_rois[:, 1] + 1.0 # 真实正样本h
gt_ctr_x = gt_rois[:, 0] + 0.5 * gt_widths # 真实正样本中心x
gt_ctr_y = gt_rois[:, 1] + 0.5 * gt_heights # 真实正样本中心y
targets_dx = (gt_ctr_x - ex_ctr_x) / ex_widths # 通过公式2后四个的x*,xa,wa得到dx
targets_dy = (gt_ctr_y - ex_ctr_y) / ex_heights # 通过公式2后四个的y*,ya,ha得到dy
targets_dw = np.log(gt_widths / ex_widths) # 通过公式2后四个的w*,wa得到dw
targets_dh = np.log(gt_heights / ex_heights) # 通过公式2后四个的h*,ha得到dh
targets = np.vstack((targets_dx, targets_dy, targets_dw, targets_dh)).transpose()
return targets6.3、_proposal_target_layer
_proposal_target_layer调用proposal_target_layer,并进一步调用_sample_rois从之前_proposal_layer中选出的2000个archors筛选出256个archors。_sample_rois将正样本数量固定为最大64(小于时补负样本),并根据公式2对坐标归一化,通过_get_bbox_regression_labels得到bbox_targets。用于rcnn的分类及回归。该层只在训练时使用;测试时,直接选择了300个archors,不需要该层了。
def _proposal_target_layer(self, rois, roi_scores, name): # post_nms_topN个archors的位置及为1(正样本)的概率
# 只在训练时使用该层,从post_nms_topN个archors中选择256个archors
with tf.variable_scope(name) as scope:
# labels:正样本和负样本对应的真实的类别
# rois:从post_nms_topN个archors中选择256个archors(第一列的全0更新为每个archors对应的类别)
# roi_scores:256个archors对应的为正样本的概率
# bbox_targets:256*(4*21)的矩阵,只有为正样本时,对应类别的坐标才不为0,其他类别的坐标全为0
# bbox_inside_weights:256*(4*21)的矩阵,正样本时,对应类别四个坐标的权重为1,其他全为0
# bbox_outside_weights:256*(4*21)的矩阵,正样本时,对应类别四个坐标的权重为1,其他全为0
rois, roi_scores, labels, bbox_targets, bbox_inside_weights, bbox_outside_weights = tf.py_func(
proposal_target_layer, [rois, roi_scores, self._gt_boxes, self._num_classes],
[tf.float32, tf.float32, tf.float32, tf.float32, tf.float32, tf.float32], name="proposal_target")
rois.set_shape([cfg.TRAIN.BATCH_SIZE, 5])
roi_scores.set_shape([cfg.TRAIN.BATCH_SIZE])
labels.set_shape([cfg.TRAIN.BATCH_SIZE, 1])
bbox_targets.set_shape([cfg.TRAIN.BATCH_SIZE, self._num_classes * 4])
bbox_inside_weights.set_shape([cfg.TRAIN.BATCH_SIZE, self._num_classes * 4])
bbox_outside_weights.set_shape([cfg.TRAIN.BATCH_SIZE, self._num_classes * 4])
self._proposal_targets['rois'] = rois
self._proposal_targets['labels'] = tf.to_int32(labels, name="to_int32")
self._proposal_targets['bbox_targets'] = bbox_targets
self._proposal_targets['bbox_inside_weights'] = bbox_inside_weights
self._proposal_targets['bbox_outside_weights'] = bbox_outside_weights
self._score_summaries.update(self._proposal_targets)
return rois, roi_scores
def proposal_target_layer(rpn_rois, rpn_scores, gt_boxes, _num_classes):
"""Assign object detection proposals to ground-truth targets. Produces proposal classification labels and bounding-box regression targets."""
# Proposal ROIs (0, x1, y1, x2, y2) coming from RPN (i.e., rpn.proposal_layer.ProposalLayer), or any other source
all_rois = rpn_rois # rpn_rois为post_nms_topN*5的矩阵
all_scores = rpn_scores # rpn_scores为post_nms_topN的矩阵,代表对应的archors为正样本的概率
if cfg.TRAIN.USE_GT: # Include ground-truth boxes in the set of candidate rois; USE_GT=False,未使用这段代码
zeros = np.zeros((gt_boxes.shape[0], 1), dtype=gt_boxes.dtype)
all_rois = np.vstack((all_rois, np.hstack((zeros, gt_boxes[:, :-1]))))
all_scores = np.vstack((all_scores, zeros)) # not sure if it a wise appending, but anyway i am not using it
num_images = 1 # 该程序只能一次处理一张图片
rois_per_image = cfg.TRAIN.BATCH_SIZE / num_images # 每张图片中最终选择的rois
fg_rois_per_image = np.round(cfg.TRAIN.FG_FRACTION * rois_per_image) # 正样本的个数:0.25*rois_per_image
# Sample rois with classification labels and bounding box regression targets
# labels:正样本和负样本对应的真实的类别
# rois:从post_nms_topN个archors中选择256个archors(第一列的全0更新为每个archors对应的类别)
# roi_scores:256个archors对应的为正样本的概率
# bbox_targets:256*(4*21)的矩阵,只有为正样本时,对应类别的坐标才不为0,其他类别的坐标全为0
# bbox_inside_weights:256*(4*21)的矩阵,正样本时,对应类别四个坐标的权重为1,其他全为0
labels, rois, roi_scores, bbox_targets, bbox_inside_weights = _sample_rois(all_rois, all_scores, gt_boxes, fg_rois_per_image, rois_per_image, _num_classes) # 选择256个archors
rois = rois.reshape(-1, 5)
roi_scores = roi_scores.reshape(-1)
labels = labels.reshape(-1, 1)
bbox_targets = bbox_targets.reshape(-1, _num_classes * 4)
bbox_inside_weights = bbox_inside_weights.reshape(-1, _num_classes * 4)
bbox_outside_weights = np.array(bbox_inside_weights > 0).astype(np.float32) # 256*(4*21)的矩阵,正样本时,对应类别四个坐标的权重为1,其他全为0
return rois, roi_scores, labels, bbox_targets, bbox_inside_weights, bbox_outside_weights
def _get_bbox_regression_labels(bbox_target_data, num_classes):
"""Bounding-box regression targets (bbox_target_data) are stored in a compact form N x (class, tx, ty, tw, th)
This function expands those targets into the 4-of-4*K representation used by the network (i.e. only one class has non-zero targets).
Returns:
bbox_target (ndarray): N x 4K blob of regression targets
bbox_inside_weights (ndarray): N x 4K blob of loss weights
"""
clss = bbox_target_data[:, 0] # 第1列,为类别
bbox_targets = np.zeros((clss.size, 4 * num_classes), dtype=np.float32) # 256*(4*21)的矩阵
bbox_inside_weights = np.zeros(bbox_targets.shape, dtype=np.float32)
inds = np.where(clss > 0)[0] # 正样本的索引
for ind in inds:
cls = clss[ind] # 正样本的类别
start = int(4 * cls) # 每个正样本的起始坐标
end = start + 4 # 每个正样本的终止坐标(由于坐标为4)
bbox_targets[ind, start:end] = bbox_target_data[ind, 1:] # 对应的坐标偏移赋值给对应的类别
bbox_inside_weights[ind, start:end] = cfg.TRAIN.BBOX_INSIDE_WEIGHTS # 对应的权重(1.0, 1.0, 1.0, 1.0)赋值给对应的类别
# bbox_targets:256*(4*21)的矩阵,只有为正样本时,对应类别的坐标才不为0,其他类别的坐标全为0
# bbox_inside_weights:256*(4*21)的矩阵,正样本时,对应类别四个坐标的权重为1,其他全为0
return bbox_targets, bbox_inside_weights
def _compute_targets(ex_rois, gt_rois, labels):
"""Compute bounding-box regression targets for an image."""
assert ex_rois.shape[0] == gt_rois.shape[0]
assert ex_rois.shape[1] == 4
assert gt_rois.shape[1] == 4
targets = bbox_transform(ex_rois, gt_rois) # 通过公式2后四个,结合256个archor和对应的正样本的坐标计算坐标的偏移
if cfg.TRAIN.BBOX_NORMALIZE_TARGETS_PRECOMPUTED: # Optionally normalize targets by a precomputed mean and stdev
targets = ((targets - np.array(cfg.TRAIN.BBOX_NORMALIZE_MEANS)) / np.array(cfg.TRAIN.BBOX_NORMALIZE_STDS)) # 坐标减去均值除以标准差,进行归一化
return np.hstack((labels[:, np.newaxis], targets)).astype(np.float32, copy=False) # 之前的bbox第一列为全0,此处第一列为对应的类别
def _sample_rois(all_rois, all_scores, gt_boxes, fg_rois_per_image, rois_per_image, num_classes): # all_rois第一列全0,后4列为坐标;gt_boxes前4列为坐标,最后一列为类别
"""Generate a random sample of RoIs comprising foreground and background examples."""
# 计算archors和gt_boxes重叠区域面积的比值
overlaps = bbox_overlaps(np.ascontiguousarray(all_rois[:, 1:5], dtype=np.float), np.ascontiguousarray(gt_boxes[:, :4], dtype=np.float)) # overlaps: (rois x gt_boxes)
gt_assignment = overlaps.argmax(axis=1) # 得到每个archors对应的gt_boxes的索引
max_overlaps = overlaps.max(axis=1) # 得到每个archors对应的gt_boxes的重叠区域的值
labels = gt_boxes[gt_assignment, 4] # 得到每个archors对应的gt_boxes的类别
# 每个archors对应的gt_boxes的重叠区域的值大于阈值的作为正样本,得到正样本的索引
fg_inds = np.where(max_overlaps >= cfg.TRAIN.FG_THRESH)[0] # Select foreground RoIs as those with >= FG_THRESH overlap
# Guard against the case when an image has fewer than fg_rois_per_image. Select background RoIs as those within [BG_THRESH_LO, BG_THRESH_HI)
# 每个archors对应的gt_boxes的重叠区域的值在给定阈值内的作为负样本,得到负样本的索引
bg_inds = np.where((max_overlaps < cfg.TRAIN.BG_THRESH_HI) & (max_overlaps >= cfg.TRAIN.BG_THRESH_LO))[0]
# Small modification to the original version where we ensure a fixed number of regions are sampled
# 最终选择256个archors
if fg_inds.size > 0 and bg_inds.size > 0: # 正负样本均存在,则选择最多fg_rois_per_image个正样本,不够的话,补充负样本
fg_rois_per_image = min(fg_rois_per_image, fg_inds.size)
fg_inds = npr.choice(fg_inds, size=int(fg_rois_per_image), replace=False)
bg_rois_per_image = rois_per_image - fg_rois_per_image
to_replace = bg_inds.size < bg_rois_per_image
bg_inds = npr.choice(bg_inds, size=int(bg_rois_per_image), replace=to_replace)
elif fg_inds.size > 0: # 只有正样本,选择rois_per_image个正样本
to_replace = fg_inds.size < rois_per_image
fg_inds = npr.choice(fg_inds, size=int(rois_per_image), replace=to_replace)
fg_rois_per_image = rois_per_image
elif bg_inds.size > 0: # 只有负样本,选择rois_per_image个负样本
to_replace = bg_inds.size < rois_per_image
bg_inds = npr.choice(bg_inds, size=int(rois_per_image), replace=to_replace)
fg_rois_per_image = 0
else:
import pdb
pdb.set_trace()
keep_inds = np.append(fg_inds, bg_inds) # 正样本和负样本的索引
labels = labels[keep_inds] # 正样本和负样本对应的真实的类别
labels[int(fg_rois_per_image):] = 0 # 负样本对应的类别设置为0
rois = all_rois[keep_inds] # 从post_nms_topN个archors中选择256个archors
roi_scores = all_scores[keep_inds] # 256个archors对应的为正样本的概率
# 通过256个archors的坐标和每个archors对应的gt_boxes的坐标及这些archors的真实类别得到坐标偏移(将rois第一列的全0更新为每个archors对应的类别)
bbox_target_data = _compute_targets(rois[:, 1:5], gt_boxes[gt_assignment[keep_inds], :4], labels)
# bbox_targets:256*(4*21)的矩阵,只有为正样本时,对应类别的坐标才不为0,其他类别的坐标全为0
# bbox_inside_weights:256*(4*21)的矩阵,正样本时,对应类别四个坐标的权重为1,其他全为0
bbox_targets, bbox_inside_weights = _get_bbox_regression_labels(bbox_target_data, num_classes)
# labels:正样本和负样本对应的真实的类别
# rois:从post_nms_topN个archors中选择256个archors(第一列的全0更新为每个archors对应的类别)
# roi_scores:256个archors对应的为正样本的概率
# bbox_targets:256*(4*21)的矩阵,只有为正样本时,对应类别的坐标才不为0,其他类别的坐标全为0
# bbox_inside_weights:256*(4*21)的矩阵,正样本时,对应类别四个坐标的权重为1,其他全为0
return labels, rois, roi_scores, bbox_targets, bbox_inside_weights6.3.1、bbox_overlaps
bbox_overlaps用于计算archors和ground truth box重叠区域的面积
7、_crop_pool_layer
_crop_pool_layer用于将256个archors从特征图中裁剪出来缩放到14*14,并进一步max pool到7*7的固定大小,得到特征,方便rcnn网络分类及回归坐标。该函数先得到特征图对应的原始图像的宽高,而后将原始图像对应的rois进行归一化,并使用tf.image.crop_and_resize(该函数需要归一化的坐标信息)缩放到[cfg.POOLING_SIZE * 2, cfg.POOLING_SIZE * 2],最后通过slim.max_pool2d进行pooling,输出大小依旧一样(256*7*7*512)。
tf.slice(rois, [0, 0], [-1, 1])是对输入进行切片。其中第二个参数为起始的坐标,第三个参数为切片的尺寸。注意,对于二维输入,后两个参数均为y,x的顺序;对于三维输入,后两个均为z,y,x的顺序。当第三个参数为-1时,代表取整个该维度。上面那句是将roi的从0,0开始第一列的数据(y为-1,代表所有行,x为1,代表第一列)
8、_head_to_tail
_head_to_tail用于将上面得到的256个archors的特征增加两个fc层(ReLU)和两个dropout(train时有,test时无),降维到4096维,用于_region_classification的分类及回归。
9、_region_classification
fc7通过_region_classification进行分类及回归。fc7先通过fc层(无ReLU)降维到21层(类别数,得到cls_score),得到概率cls_prob及预测值cls_pred(用于rcnn的分类)。另一方面fc7通过fc层(无ReLU),降维到21*4,得到bbox_pred(用于rcnn的回归)。
def _region_classification(self, fc7, is_training, initializer, initializer_bbox):
# 增加fc层,输出为总共类别的个数,进行分类
cls_score = slim.fully_connected(fc7, self._num_classes, weights_initializer=initializer, trainable=is_training, activation_fn=None, scope='cls_score')
cls_prob = self._softmax_layer(cls_score, "cls_prob") # 得到每一类别的概率
cls_pred = tf.argmax(cls_score, axis=1, name="cls_pred") # 得到预测的类别
# 增加fc层,预测位置信息的偏移
bbox_pred = slim.fully_connected(fc7, self._num_classes * 4, weights_initializer=initializer_bbox, trainable=is_training, activation_fn=None, scope='bbox_pred')
self._predictions["cls_score"] = cls_score # 用于rcnn分类的256个archors的特征
self._predictions["cls_pred"] = cls_pred
self._predictions["cls_prob"] = cls_prob
self._predictions["bbox_pred"] = bbox_pred
return cls_prob, bbox_pred总结:通过以上步骤,完成了网络的创建rois, cls_prob, bbox_pred = self._build_network(training)。
rois:256*5
cls_prob:256*21(类别数)
bbox_pred:256*84(类别数*4)
损失函数_add_losses
faster rcnn包括两个损失:rpn网络的损失+rcnn网络的损失。其中每个损失又包括分类损失和回归损失。分类损失使用的是交叉熵,回归损失使用的是smooth L1 loss。
程序通过_add_losses增加对应的损失函数。其中rpn_cross_entropy和rpn_loss_box是RPN网络的两个损失,cls_score和bbox_pred是rcnn网络的两个损失。前两个损失用于判断archor是否是ground truth(二分类);后两个损失的batchsize是256。
将rpn_label(1,?,?,2)中不是-1的index取出来,之后将rpn_cls_score(1,?,?,2)及rpn_label中对应于index的取出,计算sparse_softmax_cross_entropy_with_logits,得到rpn_cross_entropy。
计算rpn_bbox_pred(1,?,?,36)和rpn_bbox_targets(1,?,?,36)的_smooth_l1_loss,得到rpn_loss_box。
计算cls_score(256*21)和label(256)的sparse_softmax_cross_entropy_with_logits:cross_entropy。
计算bbox_pred(256*84)和bbox_targets(256*84)的_smooth_l1_loss:loss_box。
最终将上面四个loss相加,得到总的loss(还需要加上regularization_loss)。
def _add_losses(self, sigma_rpn=3.0):
with tf.variable_scope('LOSS_' + self._tag) as scope:
rpn_cls_score = tf.reshape(self._predictions['rpn_cls_score_reshape'], [-1, 2]) # 每个archors是正样本还是负样本
rpn_label = tf.reshape(self._anchor_targets['rpn_labels'], [-1]) # 特征图中每个位置对应的是正样本、负样本还是不关注(去除了边界在图像外面的archors)
rpn_select = tf.where(tf.not_equal(rpn_label, -1)) # 不关注的archor到的索引
rpn_cls_score = tf.reshape(tf.gather(rpn_cls_score, rpn_select), [-1, 2]) # 去除不关注的archor
rpn_label = tf.reshape(tf.gather(rpn_label, rpn_select), [-1]) # 去除不关注的label
rpn_cross_entropy = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=rpn_cls_score, labels=rpn_label)) # rpn二分类的损失
rpn_bbox_pred = self._predictions['rpn_bbox_pred'] # 每个位置的9个archors回归位置偏移
rpn_bbox_targets = self._anchor_targets['rpn_bbox_targets'] # 特征图中每个位置和对应的正样本的坐标偏移(很多为0)
rpn_bbox_inside_weights = self._anchor_targets['rpn_bbox_inside_weights'] # 正样本的权重为1(去除负样本和不关注的样本,均为0)
rpn_bbox_outside_weights = self._anchor_targets['rpn_bbox_outside_weights'] # 正样本和负样本(不包括不关注的样本)归一化的权重
rpn_loss_box = self._smooth_l1_loss(rpn_bbox_pred, rpn_bbox_targets, rpn_bbox_inside_weights, rpn_bbox_outside_weights, sigma=sigma_rpn, dim=[1, 2, 3])
cls_score = self._predictions["cls_score"] # 用于rcnn分类的256个archors的特征
label = tf.reshape(self._proposal_targets["labels"], [-1]) # 正样本和负样本对应的真实的类别
cross_entropy = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=cls_score, labels=label)) # rcnn分类的损失
bbox_pred = self._predictions['bbox_pred'] # RCNN, bbox loss
bbox_targets = self._proposal_targets['bbox_targets'] # 256*(4*21)的矩阵,只有为正样本时,对应类别的坐标才不为0,其他类别的坐标全为0
bbox_inside_weights = self._proposal_targets['bbox_inside_weights'] # 256*(4*21)的矩阵,正样本时,对应类别四个坐标的权重为1,其他全为0
bbox_outside_weights = self._proposal_targets['bbox_outside_weights'] # 256*(4*21)的矩阵,正样本时,对应类别四个坐标的权重为1,其他全为0
loss_box = self._smooth_l1_loss(bbox_pred, bbox_targets, bbox_inside_weights, bbox_outside_weights)
self._losses['cross_entropy'] = cross_entropy
self._losses['loss_box'] = loss_box
self._losses['rpn_cross_entropy'] = rpn_cross_entropy
self._losses['rpn_loss_box'] = rpn_loss_box
loss = cross_entropy + loss_box + rpn_cross_entropy + rpn_loss_box # 总共的损失
regularization_loss = tf.add_n(tf.losses.get_regularization_losses(), 'regu')
self._losses['total_loss'] = loss + regularization_loss
self._event_summaries.update(self._losses)
return loss 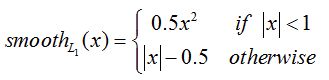
程序中先计算pred和target的差box_diff,而后得到正样本的差in_box_diff(通过乘以权重bbox_inside_weights将负样本设置为0)及绝对值abs_in_box_diff,之后计算上式(3)中的符号smoothL1_sign,并得到的smooth L1 loss:in_loss_box,乘以bbox_outside_weights权重,并得到最终的loss:loss_box
from:https://www.cnblogs.com/darkknightzh/p/10043864.html#_lab2_0_0
from:https://blog.csdn.net/u012457308/article/details/79566195