深度学习调参
优化类的参数:学习率(learning rates)、 batch_size(批处理参数:每次训练的样本数)、训练代数(epochs)、dropout
模型类的参数:隐含层数(hidden layers)、模型结构的参数(如RNN)
优化类的参数
学习率 Learning Rate
一个好的起点是从0.01尝试起
可选的几个常用值:
0.01
0.001
0.0001
0.00001
0.000001
判断依据是验证集的误差(validation error)
常用策略:
学习率衰减(learning rate)
如果选用了Adam和Adagrad的作为优化器(optimizer),则他们自带了可自适应的学习率(adaptive learning rate)
EPOCHS
当一个完整的数据集通过了神经网络一次并且返回了一次,这个过程称为一个 epoch。
然而,当一个 epoch 对于计算机而言太庞大的时候,就需要把它分成多个小块。
为什么要使用多于一个 epoch?
我知道这刚开始听起来会很奇怪,在神经网络中传递完整的数据集一次是不够的,而且我们需要将完整的数据集在同样的神经网络中传递多次。但是请记住,我们使用的是有限的数据集,并且我们使用一个迭代过程即梯度下降,优化学习过程和图示。因此仅仅更新权重一次或者说使用一个 epoch 是不够的。随着 epoch 数量增加,神经网络中的权重的更新次数也增加,曲线从欠拟合变得过拟合。
那么,几个 epoch 才是合适的呢?
不幸的是,这个问题并没有正确的答案。对于不同的数据集,答案是不一样的。但是数据的多样性会影响合适的 epoch 的数量。
要选择合适的Epochs,就可以用early stopping的方法:
具体就是观察validation error上升时就early stop,但是别一看到上升就停,再观察一下,因为有可能只是暂时的现象,这时候停止反而训练会不充分。
BATCH SIZE
一个 batch 中的样本总数。记住:batch size 和 number of batches 是不同的。
BATCH 是什么?
在不能将数据一次性通过神经网络的时候,就需要将数据集分成几个 batch。
迭代是 batch 需要完成一个 epoch 的次数。记住:在一个 epoch 中,batch 数和迭代数是相等的。
batch size这个还是需要去适当调整的,看相关的blogs,一般设置不会超过128,有可能也很小,在我目前的任务中,batch size =16有不错的效果。
dropout
可以比较有效的缓解过拟合的发生,在一定程度上达到正则化的效果。
Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。如图所示。
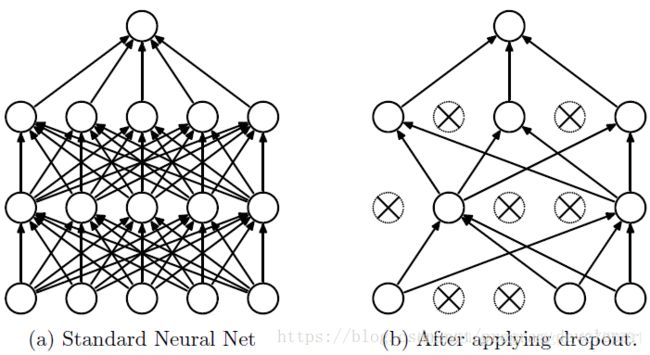
Dropout具体工作流程
假设我们要训练这样一个神经网络,如图所示。
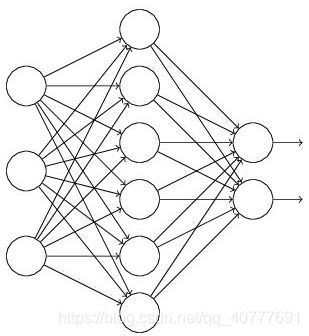
输入是x输出是y,正常的流程是:我们首先把x通过网络前向传播,然后把误差反向传播以决定如何更新参数让网络进行学习。使用Dropout之后,过程变成如下:
(1)首先随机(临时)删掉网络中一半的隐藏神经元,输入输出神经元保持不变(图3中虚线为部分临时被删除的神经元)

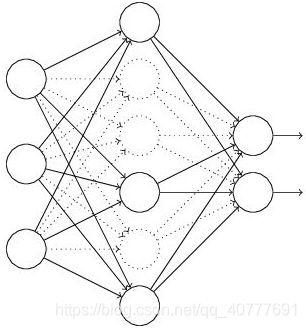
(2) 然后把输入x通过修改后的网络前向传播,然后把得到的损失结果通过修改的网络反向传播。一小批训练样本执行完这个过程后,在没有被删除的神经元上按照随机梯度下降法更新对应的参数(w,b)。
(3)然后继续重复这一过程:
. 恢复被删掉的神经元(此时被删除的神经元保持原样,而没有被删除的神经元已经有所更新)
. 从隐藏层神经元中随机选择一个一半大小的子集临时删除掉(备份被删除神经元的参数)。
. 对一小批训练样本,先前向传播然后反向传播损失并根据随机梯度下降法更新参数(w,b) (没有被删除的那一部分参数得到更新,删除的神经元参数保持被删除前的结果)。
不断重复这一过程。
Dropout大多数论文上设置都是0.5,据说0.5的效果很好,能够防止过拟合问题,但是在不同的task中,还需要适当的调整dropout的大小,出来要调整dropout值之外,dropout在model中的位置也是很关键的,可以尝试不同的dropout位置,或许会收到惊人的效果。
模型类的参数
隐含层单元数Hidden Units
解决的问题的模型越复杂则用越多hidden units,但是要适度,因为太大的模型会导致过拟合
可以增加Hidden Units数量直到validation error变差
通常来说3层的隐含层比2层的好,但是4,5,6层再深就没什么明显效果了
,一个例外情况是CNN
RNN的调参
RNN内参数
选择CELL类型,常用LSTM和GRU
stack多少个layer,通常两层
用作RNN模型前端的word embedding层的embedding数量控制在 50-200之间
如何调参?
1、在确保了数据与网络的正确性之后,使用默认的超参数设置,观察loss的变化,初步定下各个超参数的范围,再进行调参。对于每个超参数,我们在每次的调整时,只去调整一个参数,然后观察loss变化,千万不要在一次改变多个超参数的值去观察loss。
2、对于loss的变化情况,主要有以下几种可能性:上升、下降、不变,对应的数据集有train与val(validation),那么进行组合有如下的可能:
train loss 不断下降,val loss 不断下降——网络仍在学习;
train loss 不断下降,val loss 不断上升——网络过拟合;
train loss 不断下降,val loss 趋于不变——网络欠拟合;
train loss 趋于不变,val loss 趋于不变——网络陷入瓶颈;
train loss 不断上升,val loss 不断上升——网络结构问题;
train loss 不断上升,val loss 不断下降——数据集有问题;
其余的情况,也是归于网络结构问题与数据集问题中。
3、当loss趋于不变时观察此时的loss值与1-3中计算的loss值是否相同,如果相同,那么应该是在梯度计算中出现了nan或者inf导致oftmax输出为0。
此时可以采取的方式是减小初始化权重、降低学习率。同时评估采用的loss是否合理。
Reference:
https://blog.csdn.net/program_developer/article/details/80737724
https://www.jianshu.com/p/a0009ec5225e