并查集 Union Find 路径压缩 简介+实现
- 简介
- 合并和查找
- 路径压缩
- 非递归
- 递归
- 实现
简介
适用于: 可以解决连接问题, 查看网络中的节点的连接状态(比通过求两个网络的路径来看连接状态效率高); 求两个集合的并集
合并和查找
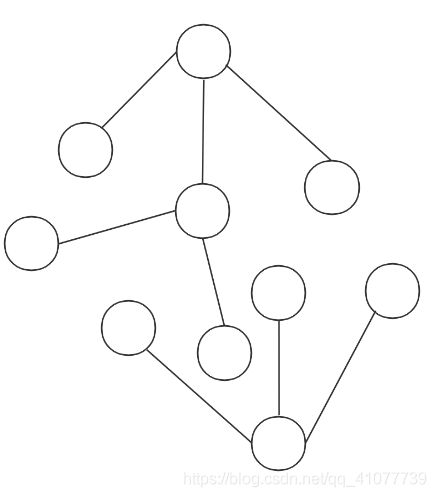
指向同一个根节点的节点在同一个集合
并查集和其他树相比比较特殊的一点是: 其他的树都是从父节点指向子节点, 并查集是子节点指向父节点
一开始5个节点都自成一个集合, 他们的父节点是自己

如果合并1, 2 (执行union(1, 2)), 就把节点2作为节点1的父节点, 节点1指向节点2

合并节点3, 4(union(3, 4), 之后再合并节点4, 5(union(4, 5)
要寻找节点3的根节点只需要while循环一直往上查找, 直到一个节点的父节点是他自己(下图的节点5), 这个节点就是节点3的父节点
同理节点4的根节点也是节点5, 所以节点3, 4在同一个集合

在上面这种情况下分别尝试, 合并节点5, 2(union(5, 2)) 和 合并节点2, 5(union(2, 5))
情况一: 合并节点5, 2(union(5, 2)), 节点2是5的父亲

情况二: 合并节点2, 5(union(2, 5)), 节点5是2的父亲
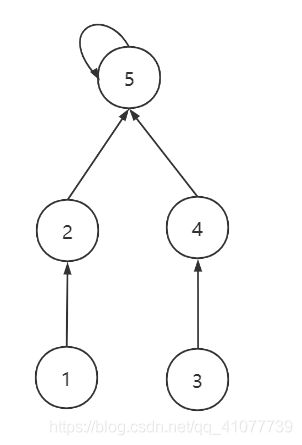
可以看出情况一的树的深度比情况二的要深, 极端的情况下甚至可能退化成一个链表, 复杂度将变成O(n), 这是我们不希望看到的, 所以在进行合并的时候要做一些判断, 把深度较高的树的根节点作为深度较低的树的根节点的父亲
这里给每个节点引入一个rank值, 表示以这个节点为根的树的深度值
// p节点所在的树的元素个数比较少
// 根据两个元素所在树的rank不同判断合并方向
if(rank[pRoot] < rank[qRoot]) // 深度低的树的根节点把深度高的树的根节点作为父亲
parent[pRoot] = qRoot; // qRoot所在树的深度没变, rank不用维护
else if(rank[pRoot] > rank[qRoot])
parent[qRoot] = pRoot;
else{ // rank[pRoot] == rank[qRoot]
parent[pRoot] = qRoot; // 如果棵树的深度一样, 可以任意选择一个根作为父亲
rank[qRoot] += 1; // 但是作为父亲的那个节点的rank值会变化, 因为深度变了
}
路径压缩
回到一开始, 如果我们合并节点1, 2(union(1, 2)), 然后合并节点2, 3(union(2, 3))

再合并节点3, 4(union(3, 4)), 最后合并节点4, 5(union(4, 5))

按照这种顺序合并的话, rank的引入也没用, 我们依然得到了一条链表
因此我们需要请出路径压缩来解决这个问题
非递归
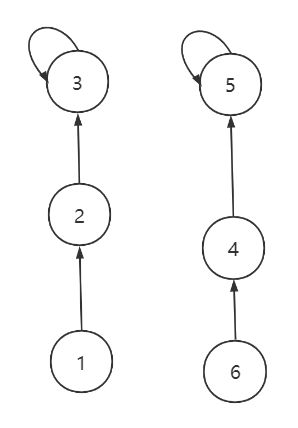
在上面这种情况下, 如果要合并节点1, 4(union(1, 4), 合并前我们都要先看两个节点是的根节点是否一样, 不一样才合并, 在向上找节点1的父亲时, 我们可以顺便修改节点1的父亲, 压缩这棵树的深度
parent[节点1] = parent[parent[节点1]]; // 节点1的父亲等于原来他父亲(节点2)的父亲(节点3)
结果如下
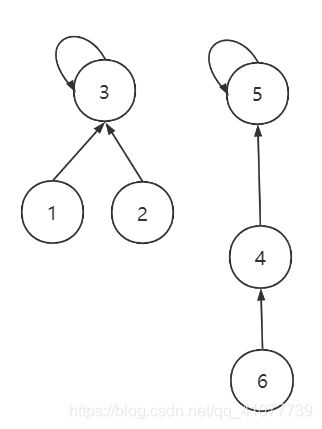
再执行union(3, 6)的结果如下, 查找节点6的父亲时进行压缩
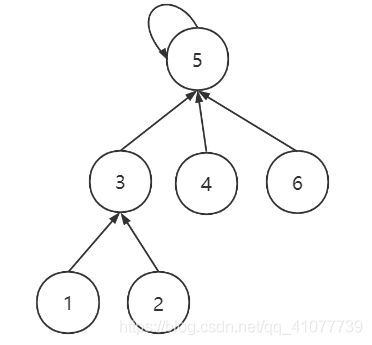
代码是这样的
while(节点 != parent[节点]) // 直到找到根节点才停止
parent[节点] = parent[parent[节点]; // 路径压缩
节点 = parent[节点]; // 向上查找, 移动
递归
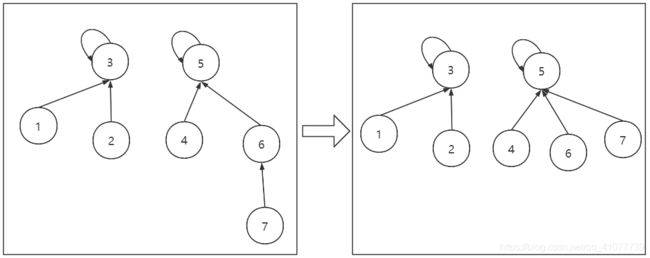
在下面这种情况, 使用非递归的路径压缩
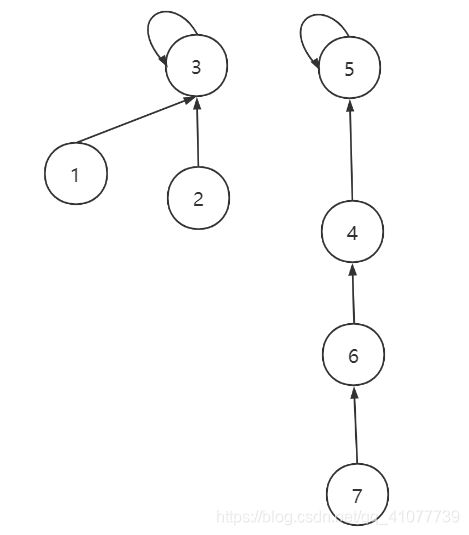
首先节点7在查找父亲的时候顺便修改了父亲
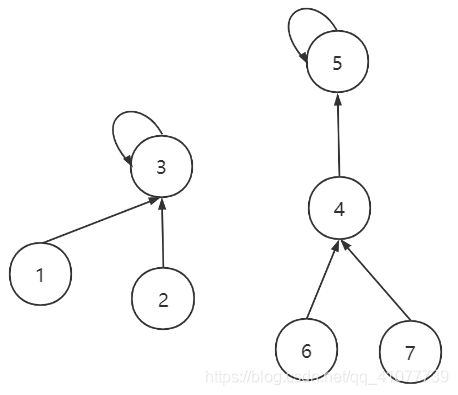
然后union(7, 2)得到的结果如下图

但是并查集并没有限制孩子的个数, 所以我们可以极端一些, 在节点7在查找父亲的时候把右边那棵树压缩成如下图
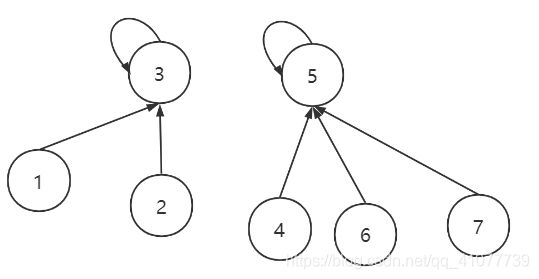
这就要使用递归了
代码如下
find(节点)
if(节点!= parent[节点])
parent[节点] = find(parent[节点]);
return parent[节点];
但是递归是有额外开销的, 实际运行起来并不会比非递归的实现快很多
而实际上非递归的实现如果查找的次数足够多的话, 修改父亲的次数足够多的话也能够得到跟使用递归一样的树结构, 而且更快
实现
// 基于rank(树的深度)的优化
// 路径压缩
public class UnionFind implements UF {
private int[] parent;
// 如果没有路径压缩的话, rank[i]表示以i为根的集合所表示的树的深度
// 但rank的值在路径压缩的过程中, 有可能不在是树的深度值
// 这也是rank不叫height或者depth的原因, 他只是作为比较的一个标准
private int[] rank;
public UnionFind(int size){
parent = new int[size];
rank = new int[size];
for(int i=0; i<size; i++){
parent[i] = i; // 初始化, 每一个parent[i]指向自己, 表示每一个元素自己自成一个集合
rank[i] = 1;
}
}
@Override
public int getSize() {
return parent.length;
}
/**
* 查找元素p所对应的集合编号
* O(h)复杂度, h为树的高度
* @param p
* @return
*/
private int find(int p){
if(p < 0 && p >= parent.length)
throw new IllegalArgumentException("Out of bound. ");
// 向上查找, 直到根节点
while(p != parent[p]){
parent[p] = parent[parent[p]]; // 路径压缩
p = parent[p];
}
return p;
}
/**
* 查找元素p所对应的集合编号, 递归实现
* @param p
* @return
*/
private int findR(int p){
if(p < 0 && p >= parent.length)
throw new IllegalArgumentException("Out of bound. ");
if(p != parent[p])
parent[p] = findR(parent[p]); // 路径压缩
return parent[p];
}
/**
* 查看元素p和元素q是否所属一个集合
* O(h)复杂度, h为树的高度
* @param p
* @param q
* @return
*/
@Override
public boolean isConnected(int p, int q) {
return find(p) == find(q);
}
/**
* 合并p, q所属的集合
* 将rank低的集合合并到rank高的集合上
* O(h)
* @param p
* @param q
*/
@Override
public void unionElements(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if(pRoot == qRoot)
return;
// 根据两个元素所在树的rank不同判断合并方向
if(rank[pRoot] < rank[qRoot]){
parent[pRoot] = qRoot; // qRoot所在树的深度没变, rank不用维护
}
else if(rank[pRoot] > rank[qRoot]){
parent[qRoot] = pRoot;
}
else{ // rank[pRoot] == rank[qRoot]
parent[pRoot] = qRoot;
rank[qRoot] += 1;
}
}
}
时间复杂度严格意义上不是O(h), 而是O(logn), iterated logarithm
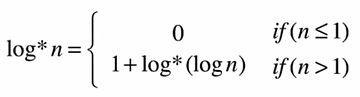
O(logn)比O(log n)快, 但比O(1)慢, 近乎是O(1)级别的