写爬虫时面对httpx和requests怎么选择呢
文章目录
- 前言
- 开始动手
- 代码
- 总结
前言
已经忘了多久没写博客,确实没什么时间也没什么精力。不过我觉得比起看理论的那些书,我还是更喜欢动手敲敲代码。政治不是说认识和实践要结合才能实现两次飞跃嘛,抽点空给自己放松一下。刷推文发现了httpx这个库,想试一下这个库怎么玩,所以随手写了个简单的代码来玩一下。
开始动手
先去看看httpx官方文档
httpx官方文档链接
从开头就看得出它支持同步和异步请求,并且只支持python3,安装方法文档末尾也给出了,就是pip install httpx,需要python3.6+。
那今天爬哪个网站呢,本来想试试csdn的,结果刚F12按下去,发现主页竟然推荐里面有爬取中国大学排名的,那好吧我去试试这个网站。
顺便贴一下这个小哥哥(看名字应该是吧)的原博客链接:【Python爬虫】 2020中国大学排名
这个代码的注释真的是太详细了,爱了爱了。然后浏览了一下他的主页,发现他是大二在读,看博客内容应该是在学习python和小程序后端相关的知识,那就一起加油啦。
ok,言归正传,打开目标网页2020中国大学排名1200强【完整版】
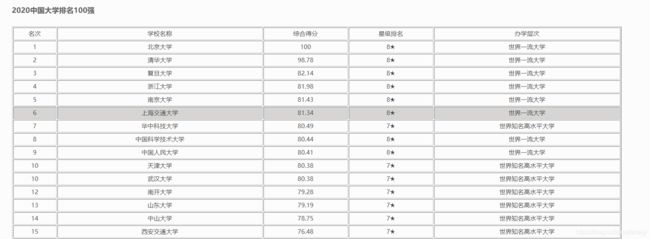
稍微检查一下,发现我们需要的内容都是在表格标签中的

那就直接解析就行
代码
代码部分呢主要就是对比httpx和requests库的差异(主要是速度上),解析部分我用的pyquery,数据存储用pandas的to_csv保存为csv文件。对网页进行100次的请求,来对比两个库的速度
httpx版本代码
import httpx
import pandas as pd
from pyquery import PyQuery as pq
import asyncio
import time
async def myrequest(client):
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'}
url_base='http://m.gaosan.com/gaokao/265440.html'
r=await client.get(url_base,headers=headers)
r.encoding='utf8'
# doc=pq(r.text)
#
# for li in doc.items('table tr td:first-child'):
# num.append(li.text())
# for li in doc.items('table tr td:nth-child(2)'):
# name.append(li.text())
# for li in doc.items('table tr td:nth-child(3)'):
# score.append(li.text())
# for li in doc.items('table tr td:nth-child(4)'):
# star.append(li.text())
# for li in doc.items('table tr td:last-child'):
# level.append(li.text())
async def main():
async with httpx.AsyncClient() as client:
start=time.time()
for i in range(100):
task_list=[]
req=myrequest(client)
task=asyncio.create_task(req)
task_list.append(task)
await asyncio.gather(*task_list)
end=time.time()
print(f"花费了{end-start}s")
if __name__ == '__main__':
# num=[]
# name=[]
# score=[]
# star=[]
# level=[]
asyncio.run(main())
# data=pd.DataFrame({num[0]:num[1:],name[0]:name[1:],score[0]:score[1:],star[0]:star[1:],level[0]:level[1:]})
# data.to_csv('./中国大学排名.csv',index=False)
requests版本代码
import requests
import pandas as pd
from pyquery import PyQuery as pq
import time
def myrequest():
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'}
url_base='http://m.gaosan.com/gaokao/265440.html'
r=requests.get(url_base,headers=headers)
r.encoding='utf8'
# doc=pq(r.text)
#
# for li in doc.items('table tr td:first-child'):
# num.append(li.text())
# for li in doc.items('table tr td:nth-child(2)'):
# name.append(li.text())
# for li in doc.items('table tr td:nth-child(3)'):
# score.append(li.text())
# for li in doc.items('table tr td:nth-child(4)'):
# star.append(li.text())
# for li in doc.items('table tr td:last-child'):
# level.append(li.text())
def main():
start=time.time()
for i in range(100):
myrequest()
end=time.time()
print(f"花费了{end-start}s")
if __name__ == '__main__':
# num=[]
# name=[]
# score=[]
# star=[]
# level=[]
main()
# data=pd.DataFrame({num[0]:num[1:],name[0]:name[1:],score[0]:score[1:],star[0]:star[1:],level[0]:level[1:]})
# data.to_csv('./中国大学排名2.csv',index=False)
对比
httpx只用了3.3s
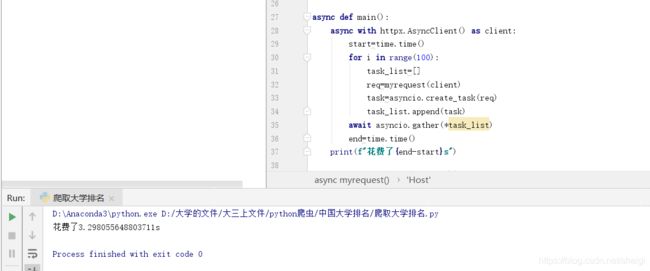
而requests花费了26.5s
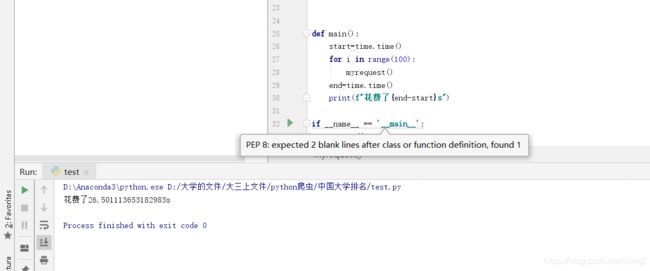
这个差距就不用多说了吧。
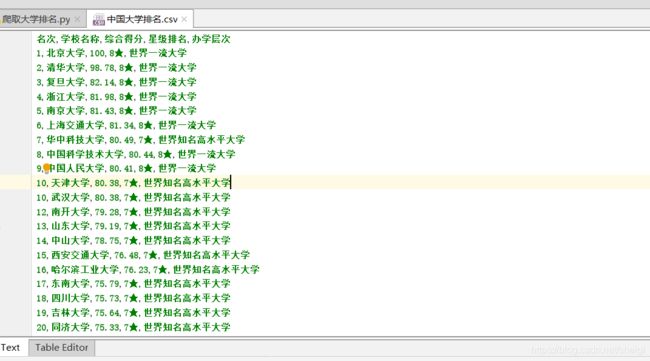
上面的代码将注释部分去掉,并且去掉循环部分(或者把100改成1)就能爬取并保存我们想要的数据了,结果如下
总结
从结果的时间对比来看,异步框架的优越性不言而喻。但是在一次请求的比较时,两者的差距并不大。因此,当我们需要爬取大量数据的时候,不妨试试异步爬取,该放弃requests的时候还是要放弃的。为什么我对比的对象是httpx而不是aiohttp,主要是因为aiohttp只支持异步,还需要学习并发方面的一些内容以及模块使用,而相对的httpx更贴近于熟悉的requests,并且对于并发依赖相比较来说少一些,更易于上手。不过,如果想真的理解熟练使用异步框架,还是应该把相关的所有内容都系统的学习一遍。