Apache Zeppelin安装及介绍
背景
Apache Zeppelin提供了web版的类似ipython的notebook,用于做数据分析和可视化。背后可以接入不同的数据处理引擎,包括spark, hive, tajo等,原生支持scala, java, shell, markdown等。它的整体展现和使用形式和Databricks Cloud是一样的,就是来自于当时的demo。
Mac OS上安装
目前github上,zeppelin版本是0.5.0,没用预先编译好的包提供下载。安装文档:http://zeppelin.incubator.apache.org/docs/install/install.html
其他组件都是好安装的,直接mvn install是没问题的。
我安装的时候唯一不太熟悉的就是zeppelin-web项目,里面使用了node, grunt, bower这些前段的工具。
我的经验是,修改zeppelin-web项目的pom.xml,把这部分脚本单独走一遍,
<plugin>
<groupId>com.github.eirslettgroupId>
<artifactId>frontend-maven-pluginartifactId>
<version>0.0.23version>
<executions>
<execution>
<id>install node and npmid>
<goals>
<goal>install-node-and-npmgoal>
goals>
<configuration>
<nodeVersion>v0.10.18nodeVersion>
<npmVersion>1.3.8npmVersion>
configuration>
execution>
<execution>
<id>npm installid>
<goals>
<goal>npmgoal>
goals>
execution>
<execution>
<id>bower installid>
<goals>
<goal>bowergoal>
goals>
<configuration>
<arguments>--allow-root installarguments>
configuration>
execution>
<execution>
<id>grunt buildid>
<goals>
<goal>gruntgoal>
goals>
<configuration>
<arguments>--no-color --forcearguments>
configuration>
execution>
executions>
plugin>安装顺序:
1. 首先需要提前安装好npm和node。 brew install npm和npm install -g node。
2. 进入zeppelin-web目录下,执行 npm install。它会根据package.json的描述安装一些grunt的组件,安装bower,然后再目录下生产一个node_modules目录。
3. 执行 bower –alow-root install,会根据bower.json安装前段库依赖,有点类似于java的mvn。见http://bower.io/
4. 执行 grunt –force,会根据Gruntfile.js整理web文件。
5. 最好执行 mvn install -DskipTests,把web项目打包,在target目录下会生成war。
mvn可能会出错,因为web.xml不在默认路径下,需要在pom.xml里添加:
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-war-pluginartifactId>
<configuration>
<webXml>app\WEB-INF\web.xmlwebXml>
configuration>
plugin>启动
安装完之后,在zeppelin parent目录下,修改conf文件夹里的zeppelin-env.sh和zeppelin-site.xml,可以是默认配置,但要把两个文件原本的无效后缀去掉。
在zeppelin parent目录下执行
bin/zeppelin-daemon.sh start就可以在localhost:8080 访问到zepplin主页了。如果没有出主页,可以看浏览器console,是缺少了什么文件,八成是web项目打包的时候漏了,很可能是bower和grunt命令执行的时候缺少依赖出错的。
主界面为 
zeppelin parent目录下会看到一个notebook文件夹,按notebook的名字命名区分了多个子目录。目录下是一个note.json文件,记录了每个notebook里输入的代码和执行结果,启动的时候会加载起来。
功能
进入页面上的notebook,可以直接写scala代码, 
通过标识%md, %sh, %sql, %spark, %hive, %tajo来区分要执行的是什么,默认不写的话,执行环境是scala。在 http://127.0.0.1:8080/#/interpreter 页面里有详细的参数说明。
我还随手试了几个: 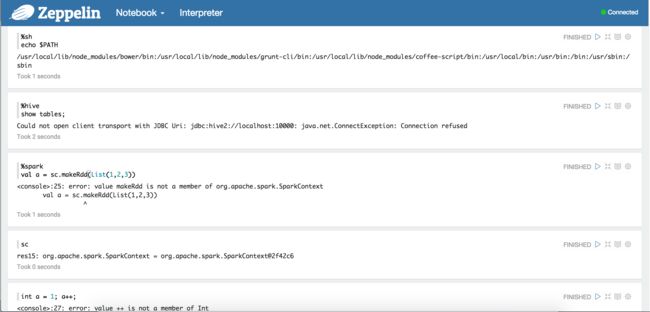
非常酷。
此外,zeppelin为spark sql做了可视化工作,进入tutorial notebook,它里面已经写好了例子。由于本地编译没有指定spark 版本,1.3之前版本没用toDF方法,而是toSchemaRDD,改下面这段:
import sys.process._
// sc is an existing SparkContext.
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
val zeppelinHome = ("pwd" !!).replace("\n", "")
val bankText = sc.textFile(s"$zeppelinHome/data/bank-full.csv")
case class Bank(age: Integer, job: String, marital: String, education: String, balance: Integer)
val bank = bankText.map(s => s.split(";")).filter(s => s(0) != "\"age\"").map(
s => Bank(s(0).toInt,
s(1).replaceAll("\"", ""),
s(2).replaceAll("\"", ""),
s(3).replaceAll("\"", ""),
s(5).replaceAll("\"", "").toInt
)
).toSchemaRDD
bank.registerTempTable("bank")生成bank表之后,可以做查询,效果如下: 
有直方图,饼状图,散点图,折线图等等。
注意: 
这里${maxAge=}的写法和databricks cloud里的demo一样。当时那个例子是输入soccer,然后下方会实时训练并输出与足球有关的tweets(值FIFA比赛时期)。
这种表示方法,Zeppelin称之为Dynamic Form:
http://zeppelin.incubator.apache.org/docs/dynamicform.html
总结
apache zeppelin应该会很吸引分布式计算、数据分析从业者,代码量少,模块很清楚,可以尝试接入不同计算引擎,试试任务运行、可视化效果,是个值得把玩的算比较前卫的项目。
没有过多复杂的操作,只是区分了多个notebook,每个notebook里做单独的分析处理工作,流程和结果会被保存下来。此外,为spark做了更好的支持,比如默认是scala环境,默认sc已经创建好,即spark local可跑,默认spark sql有可视化效果。
全文完 :)