Python Requests:两个例子说明get和post方法+用谷歌浏览器查看网络请求
文章目录
- 一、前言
- 二、get请求
- 三、post请求
- 四、后记
一、前言
上学期学完了Python爬虫后,就一直想着自己做个系统的爬虫课程博客。原因是前面写的爬虫随笔系列内容太随便,而且例子也不够丰满,实操体验不足,对于寻求某个特定问题的人确实能提供优秀的解决方案,但对学习的新手来说体验还是不足。不过后来爬虫课程也一直迟迟没有做起来,一个是没有时间和机会,另一个也是很难找一些很好的例子。这个过程也深深体验到,学和教是两个层次。最近做一个讲爬虫的PPT的时候就找了很多case,关于HTTP请求的两种方式终于找到了好一点的例子了,所以就随手写一下分享出来。
这里,我假设读者已经明白了爬虫的概念,也初步接触了requests包。事实上,爬虫入门就是学会三件事:发起请求、解析源码、反爬策略。这几件事都有现成的第三方库可以做,关键的学习应该聚焦于弄懂概念,例如明白HTTP请求过程、弄懂源码解析的规则、了解常见的反爬虫策略以及如何应对。至于代码的使用,永远是最简单的。 学到后面,更多的就是直接上Scrapy框架了,用到的包和涉及的方法都不一样,但做的事还是一样的,所以“有概念”就很重要了。
二、get请求
那么先解释一下什么叫请求,当我们利用计算机先网络上其它计算机(例如一些企业的服务器)发起请求时,会经常冠以http或者https的前缀,就意味着我们这次请求遵循了对应的协议,这些协议规定了你要如何向你说请求的计算机描述你要它返回给你的东西。打个比方,你去饭店吃饭,你所点的菜品必须是在菜单上,并且量和做法只能按所给范围选择,否则厨师就不知道上什么菜给你。
而在http/https请求中,提供了几个规定好的请求方法,其中最常用的就是get和post。先说get请求,这种方法就好比你进入一家店,点菜的方式是在前台点菜,描述清楚你要的东西(form link),一段时间后根据你的“请求”返回给你菜品(data),你再进店坐下(网页)。 一般浏览器发起get请求的方式是直接将链接填进地址栏,或者点击页面上的链接跳转。
那么在http请求中,这种“菜单”的格式就是这样的:
协 议 名 : / / 域 名 : 端 口 / 内 部 目 录 或 服 务 名 ? 参 数 名 1 = 参 数 & 参 数 名 2 = 参 数 & … 协议名://域名:端口/内部目录或服务名?参数名1=参数\&参数名2=参数\&\dots 协议名://域名:端口/内部目录或服务名?参数名1=参数&参数名2=参数&…
现在,如果我们想请求百度的服务器,给我们“python”这个词的搜索结果,那么构造出来的get请求链接就是:https://www.baidu.com/s?wd=python,点击这个链接后我们就会到达百度的搜索详情页。
在这个链接中,协议名是’https’,域名是 ‘www.baidu.com’,服务名是’s’,应该是search的意思,’?‘后面带的都是相应的参数,例如’wd’就是word的意思,我们给这个参数的值是’python’。
那么这些参数如何知道呢?例如下面我们来找一下搜索不同页面的参数是什么,可选范围是什么。
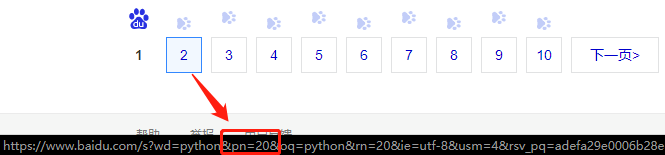
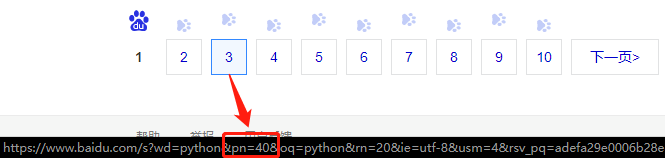
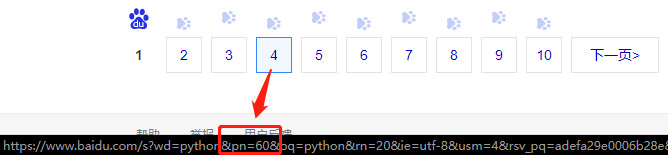
观察可以看出,页数由’pn’这个参数决定,并且规律为20*(n-1),这样,我们就可以构造出第5页的请求链接,就是https://www.baidu.com/s?wd=python&pn=80,所以根据这个规则,我们就可以批量请求了,例如访问前十页内容,就可以用这样的代码构造批量请求:
import requests
for i in range(10):
url = 'https://www.baidu.com/s?wd=python&pn='+str(20*i)
r = requests.get(url)
# 对请求到的网页内容后续处理
上面的代码中第4行也是requests发起get请求的代码。代码很简单,但我们用了更简单的方式实现大批量请求。
三、post请求
post请求是另一种常见的http请求的方式,这种方式就好比你是先进入了饭店(网页),坐下后服务员过来给你菜单(param list),你再点菜(form data),把你的“请求”按参数填上去(post),之后上菜(data),期间你需要别的东西再叫来服务员进行post。 浏览器发起post请求的场景很多,比如填写登录信息、比如在页面勾选某些选项后提交刷新,这些操作都是在原来的页面上再进行一定的post请求得到新数据后再渲染加载出新的页面。很多情况下,返回的内容会是一个json数据。
那么,如何发起post请求呢,requests的post方法如何使用呢?在cmd打开ipython来help一下:
C:\User\mfw>ipython
Python 3.6.5 |Anaconda, Inc.| (default, Mar 29 2018, 13:32:41) [MSC v.1900 64 bit (AMD64)]
Type 'copyright', 'credits' or 'license' for more information
IPython 6.4.0 -- An enhanced Interactive Python. Type '?' for help.
In [1]: import requests
In [2]: help(requests.post)
Help on function post in module requests.api:
post(url, data=None, json=None, **kwargs)
Sends a POST request.
:param url: URL for the new :class:`Request` object.
:param data: (optional) Dictionary (will be form-encoded), bytes, or file-like object to send in the body of the :class:`Request`.
:param json: (optional) json data to send in the body of the :class:`Request`.
:param \*\*kwargs: Optional arguments that ``request`` takes.
:return: :class:`Response ` object
:rtype: requests.Response
可以看到,post方法最关键的两个参数是url和data,前者是访问的网站,后者是给这个网站提交的数据清单,以字典或者json格式组织。
举个post请求的栗子,翻译网站的样式现在大都是在左框输入翻译内容,右框输出翻译结果。这个过程很明显就是post请求,页面将我们输入的信息,例如翻译的词语,转换的语言,生成post的数据清单提交给网站,再接受服务器返回的结果显示在页面上。我们可以通过浏览器的开发者工具来体验这个过程中浏览器背地里做了什么。
我们打开有道翻译,按下F12或者右键->检查,就可以得到下面这个页面,这里显示了浏览器过程中后台的数据情况,我们主要关注Network这一块:
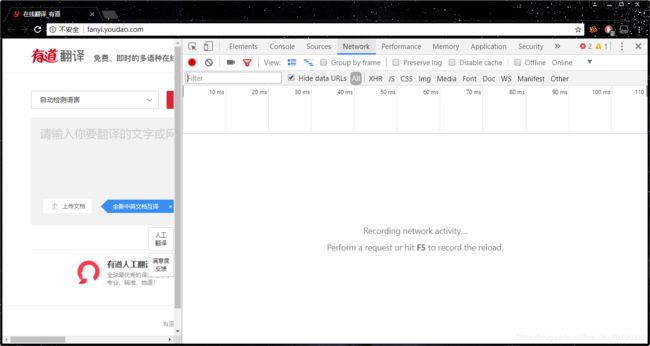
接下来,当我们在页面的左框输入一个词语然后回车的时候,我们会看到跳出了一系列的文件和数据,这就是服务器返回来的内容,里面可能有HTML文本,或者Img图片,或者链接等等的内容。而中间还有一天时间轴,各种颜色对应着各个文件返回来的时间段。
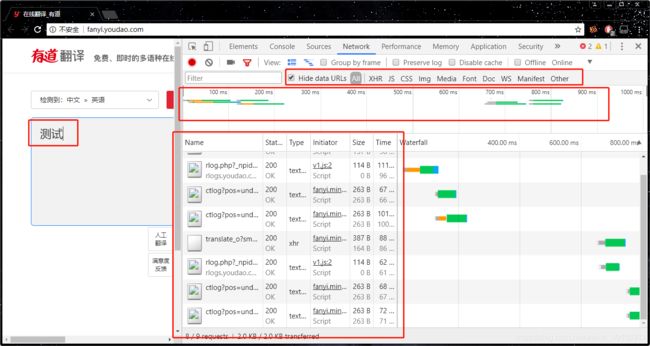
接下来,把过滤器从’All’点到’XHR’,XHR文件是什么东西,请看这里。而每个XHR文件旁边都有一栏显示’Headers’、‘Perview’等等,我们先看到后者——预览,从这里可以看到这个文件的内容。
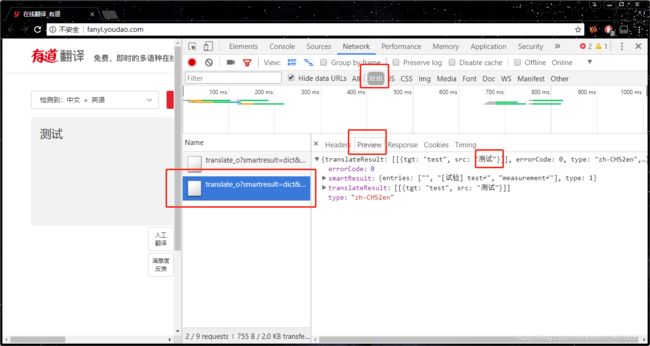
看到’Headers’,这里写的是这个数据的头,包含着一些信息,主要说明了这个文件从哪里根据哪种方式和什么参数请求得来的,General中看到这个requests请求的实际URL是哪个,Requests Mode就是我们说的get和post,最关键的是这个Status_code,状态码为200意味着请求正常,而例如常见的404,503就是网络问题或者服务器问题。下面的请求头和响应头一般都不是我们关注的,对于post请求,Form Data则是我们必须看的,仔细读取里面的信息,就可以初步体会到我们刚才post时提交了什么数据了,例如’i’无疑就是我们的输入词语,'from’和’to’应该就是从什么语言到什么语言,下面还有一些页面自动生成的信息。
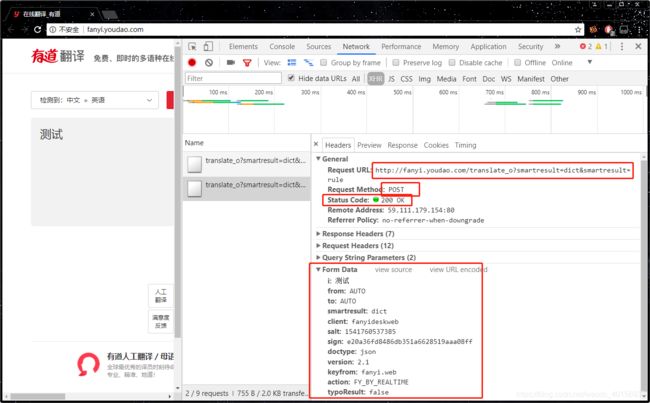
那么我们已经知道了,对哪个网址,进行哪种请求,提交什么数据,自然就可以写出程序来实现这个请求的过程了。
# -*- coding: utf-8 -*-
import requests
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule"
data = {
'i':'测试',
'from':'AUTO',
'to':'AUTO',
'smartresult':'dict',
'client':'fanyideskweb',
'salt':'1541040870670',
'sign':'a3b45c4c28237d17d6c596592929ccc0',
'doctype':'json',
'version':'2.1',
'keyfrom':'fanyi.web',
'action':'FY_BY_REALTIME',
'typoResult':'false',
}
r = requests.post(url, data = data)
result = r.json()
print(result)
print(result['translateResult'][0][0]['tgt'])
这里返回的数据是json格式的,所以还要进一步解析,关于json数据的处理也可自行查阅资料学习。
四、后记
虽然以后在工程中使用requests比之于Scrapy要少的多,但平时写些体量比较小的爬虫小程序的时候,效率还是蛮高的。
emmm其实没啥好记了。。纯属强迫症,有前言一定要有后记。。。