大数据学习笔记(六)
一、Azkaban介绍
1.1 Azkaban是什么
Azkaban是由Linkedin开源的一个批量工作流任务调度工具,用于在一个工作流内以一个特定的顺序运行一组工作和流程。Azkaban定义了一种k/v(properties)格式文件来建立任务之间的依赖关系,并提供一个易于使用的web用户界面来维护和跟踪工作流。
1.2 为什么要使用Azkaban
一个完整的数据分析系统通常都是由大量任务单元组成,比如shell脚本、Java程序、MapReduce程序、hive脚本等等。各任务单元之间存在时间先后或前后依赖的关系。为了很好地组织这些任务单元按照计划执行,需要一个强大的工作流调度系统来调度执行。
Azkaban是一款开源的、轻量级的额任务调用工具,它的功能类似于linux操作系统的定时任务crontab。但是在实际应用中,简单的任务调用我们会使用crontab来定义。在hadoop领域,我们会使用一些功能更加强大的任务调度器,如Azkaban、Oozie等。
二、Azkaban安装
2.1 编译
首先从github下载压缩包,下载地址:https://github.com/azkaban/azkaban。下载完成后,需要进行编译操作。Azkaban要求安装java8以上版本。
# 编译安装,但不运行测试
cd /export/servers/azkaban-3.51.0
bin/gradlew build installDist -x test
2.2 单机模式安装
第一步:进入/export/servers/azkaban-3.51.0/azkaban-solo-server/build/distributions目录,该目录下存放着两个压缩包。
![]()
第二步:将其中一个压缩包解压缩到/export/servers目录下;
tar -zxvf azkaban-solo-server-0.1.0-SNAPSHOT.tar.gz -C /export/servers/
第三步:进入/export/servers/azkaban-solo-server-0.1.0-SNAPSHOT/conf目录,编辑azkaban.properties文件,修改时区配置信息;
default.timezone.id=Asia/Shanghai
第四步:进入/export/servers/azkaban‐solo‐server‐0.1.0‐SNAPSHOT/plugins/jobtypes目录,编辑commonprivate.properties文件,将execute.as.user和memCheck.enabled设置为false;
# 如果为true,代表可以使用非登录用户执行任务
execute.as.user=false
# 关闭内存检测
memCheck.enabled=false
第五步:启动服务;
cd /export/servers/azkaban‐solo‐server‐0.1.0‐SNAPSHOT
bin/start‐solo.sh
如果不是在azkaban‐solo‐server根目录下运行bin/start-solo.sh,会出现以下错误:

启动成功后,在浏览器上输入http://node01:8081后,输入用户名(默认:azkaban)和密码(默认:azkaban)登录即可。
2.3 集群模式安装
如果是单机模式,所有的数据信息都是保存在默认的H2数据库中。如果是集群模式,需要在服务器环境中安装mysql数据库。
2.3.1 导入数据库
首先进入/export/servers/azkaban-3.51.0/azkaban-db/build/sql目录下,该目录存放了创建数据库的脚本文件create-all-sql-0.1.0-SNAPSHOT.sql。
导入mysql数据库的步骤:
- 第一步:打开mysql终端,登录mysql数据库;
mysql ‐uroot ‐p
- 第二步:创建数据库;
CREATE DATABASE azkaban;
use azkaban;
- 第三步:创建数据库用户,并授权;
CREATE USER 'azkaban'@'%' IDENTIFIED BY 'azkaban';
GRANT all privileges ON azkaban.* to 'azkaban'@'%' identified by 'azkaban' WITH GRANT OPTION;
flush privileges;
- 第四步:导入数据库;
source /export/servers/azkaban-3.51.0/azkaban-db/build/sql/create-all-sql-0.1.0-SNAPSHOT.sql;
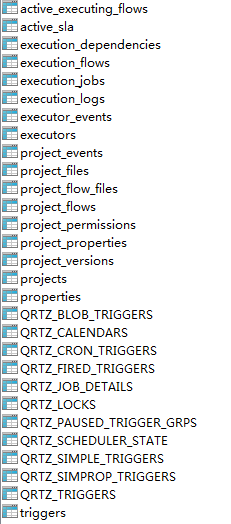
azkaban内置的所有表:
2.3.2 解压软件
执行之前编译操作后,在azkaban-3.51.0目录下会产生两个子目录:azkaban-exec-server和azkaban-web-server。azkaban-exec-server模块负责执行具体的任务;azkaban-web-server模块负责提供web界面展示和接收http请求。
下面是如何解压这两个模块的具体操作:
# 解压azkaban-exec-server
cd /export/servers/azkaban-3.51.0/azkaban-exec-server/build/distributions
tar -zxvf azkaban-exec-server-0.1.0-SNAPSHOT.tar.gz -C /export/servers
# 解压azkaban-exec-server
cd /export/servers/azkaban-3.51.0/azkaban-web-server/build/distributions
tar -zxvf azkaban-web-server-0.1.0-SNAPSHOT.tar.gz -C /export/servers
2.3.3 生成ssl证书
为了能够使用https方式访问web服务,我们需要在解压后的azkaban-web-server-0.1.0-SNAPSHOT目录下,生成ssl证书。
cd /export/servers/azkaban-web-server-0.1.0-SNAPSHOT
keytool -keystore keystore -alias jetty -genkey -keyalg RSA
2.3.4 安装azkaban web server
进入/export/servers/azkaban-web-server-0.1.0-SNAPSHOT/conf目录,然后修改azkaban.properties文件。
# 修改时区
default.timezone.id=Asia/Shanghai
# 启用ssl
jetty.use.ssl=true
# 配置ssl
jetty.ssl.port=8443
jetty.keystore=/export/servers/azkaban-web-server-0.1.0-SNAPSHOT/keystore
jetty.password=azkaban
jetty.keypassword=azkaban
jetty.truststore=/export/servers/azkaban-web-server-0.1.0-SNAPSHOT/keystore
jetty.trustpassword=azkaban
# 无需刷新执行程序统计信息即可处理的最长时间(以毫秒为单位)
azkaban.activeexecutor.refresh.milisecinterval=10000
# 从Web服务器初始化中启用队列处理器
azkaban.queueprocessing.enabled=true
# 无需刷新执行程序统计信息即可处理的最大队列流数
azkaban.activeexecutor.refresh.flowinterval=10
# 刷新执行程序统计信息的最大线程数
azkaban.executorinfo.refresh.maxThreads=10
2.3.5 安装azkaban executor server
第一步:进入/export/servers/azkaban-exec-server-0.1.0-SNAPSHOT/conf目录,然后修改azkaban.properties文件。
# 修改时区
default.timezone.id=Asia/Shanghai
# 启用ssl
jetty.use.ssl=true
# 配置ssl
jetty.keystore=/export/servers/azkaban-web-server-0.1.0-SNAPSHOT/keystore
jetty.password=azkaban
jetty.keypassword=azkaban
jetty.truststore=/export/servers/azkaban-web-server-0.1.0-SNAPSHOT/keystore
jetty.trustpassword=azkaban
azkaban.webserver.url=https://node01:8443
第二步:进入/export/servers/azkaban-3.51.0/az-exec-util/src/main/c目录,将execute-as-user.c文件拷贝到/export/servers/azkaban-exec-server-0.1.0-SNAPSHOT/plugins/jobtypes目录;
cd /export/servers/azkaban-3.51.0/az-exec-util/src/main/c
cp execute-as-user.c /export/servers/azkaban-exec-server-0.1.0-SNAPSHOT/plugins/jobtypes
第三步:执行编译;
cd /export/servers/azkaban-exec-server-0.1.0-SNAPSHOT/plugins/jobtypes
gcc execute-as-user.c -o execute-as-user
chown root execute-as-user
chmod 6050 execute-as-user
第四步:修改commonprivate.properties配置文件;
cd /export/servers/azkaban-exec-server-0.1.0-SNAPSHOT/plugins/jobtypes
vi commonprivate.properties
# 添加下面两行配置信息
memCheck.enabled=false
azkaban.native.lib=/export/servers/azkaban-exec-server-0.1.0-SNAPSHOT/plugins/jobtypes
2.3.6 启动服务
第一步:启动azkaban-exec-server;
cd /export/servers/azkaban-exec-server-0.1.0-SNAPSHOT
bin/start-exec.sh
第二步:激活azkaban-exec-server;
# 可以在任意目录下执行如下命令做激活操作
curl -G "node01:$(<./executor.port)/executor?action=activate" && echo
第三步:启动azkaban-web-server;
cd /export/servers/azkaban-web-server-0.1.0-SNAPSHOT
bin/start-web.sh
启动完成后,在浏览器上输入https://node01:8443,然后输入用户名和密码(同为azkaban)即可登录管理平台。
这里需要注意的是,因为我们启动了ssl功能,所以访问后台的地址需要使用https协议。
三、实战
3.1 单一类型job
- 第一步:创建一个文本文件,文件编码格式使用“UTF-8 without bom”;
vi single_command.job
type=command
command=echo 'hello world'
- 第二步:将文件打包成zip包;
zip single_command.zip single_command.job
- 第三步:在azkaban管理后台创建项目,并上传zip包;
- 第四步:启动job;
3.2 多类型job
- 第一步:新建文本文件,命名为foo.job,文件内容如下:
type=command
command=echo 'foo'
- 第二步:新建第二个文本文件,命名为bar.job,文件内容如下:
type=command
command=echo 'bar'
dependencies=foo
- 第三步:将两个文件打包成zip格式;
- 第四步:将zip包部署到azkaban上,并运行job;
3.3 操作HDFS
- 第一步:创建一个文本文件,文件内容如下:
type=command
command=/export/servers/hadoop‐3.1.1/bin/hdfs dfs ‐mkdir /azkaban
第二步:将文件打包成zip格式;
第三步:上传zip包到azkaban上,并运行job;
3.4 MapReduce任务
- 第一步:创建文本文件,文件内容如下:
type=command
command=/export/servers/hadoop‐3.1.1/bin/hadoop jar /export/servers/hadoop-3.1.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar pi 3 5
- 第二步:将文件打包成zip格式,然后再上传到azkaban上;
- 第三步:启动job;
3.5 运行Hive脚本
- 第一步:准备hive脚本文件,命名为
hive.sql;
create database if not exists azkaban;
use azkaban;
create table if not exists emp(id string,name string) row format
delimited fields terminated by '\t';
- 第二步:创建job文件,文件内容如下:
type=command
command=/export/servers/apache‐hive‐3.1.1‐bin ‐f 'hive.sql'
- 第三步:将job文件与hive脚本文件一起打包成zip包;
- 第四步:将zip包上传到azkaban上,并启动job;
3.6 定时任务
azkaban提供了scheduler功能,用以实现对我们的作业任务进行定时调度。
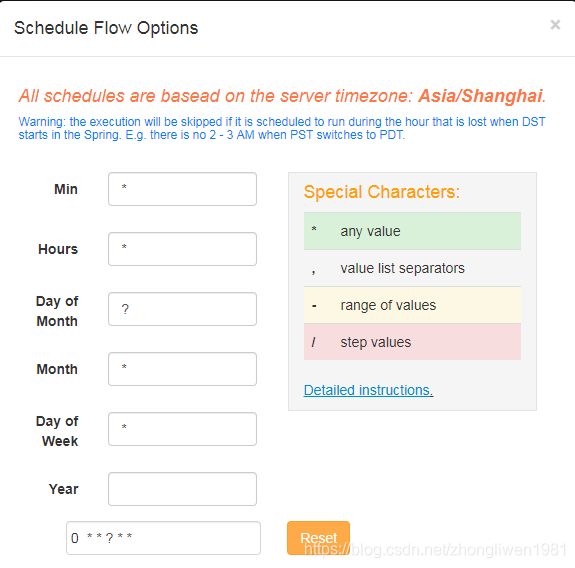
*/1 * ? * * 每分钟执行一次定时调度任务;
0 1 ? * * 每天晚上凌晨一点钟执行这个任务;
0 */2 ? * * 每隔两个小时定时执行这个任务;
30 21 ? * * 每天晚上九点半定时执行这个任务;