Flume1.8.0原理解析及安装部署
Flume是数据收集/聚合/传输的组件,也是我们生产环境中常用的日志收集传输系统,常用的一种日志实时处理架构就是Flume+Kafka+Storm/Flink+HDFS,这些实时系统的集成日后我们会提及到。
一 背景
简介:Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,2009年贡献给Apache并成为顶级项目。Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。Flume有两个版本Flume 0.9X版本的统称Flume-og(original generation),Flume1.X版本的统称Flume-ng(next generation),由于Flume-ng经过重大重构,与Flume-og有很大不同,使用时请注意区分。本文中所介绍的Flume原理以及安装、简单使用均是基于Flume-ng版本。
对比:目前有很多的日志收集系统,例如Facebook—Scribe日志收集系统、Apache—Chukwa日志收集系统、Apache—Flume日志收集系统、elastic—logstash日志收集系统。scribe 主要包括客户端、数据收集和存储这三个部分,在数据收集(collector)和存储(store)之间有良好的容错机制。 但是不足的是,并没有提供客户端(agent)和数据收集(collector)之间的数据容错机制,需要使用者自己实现,此外系统在负载均衡方面的性能也有待于提高;Logstash耗资源较大,运行占用CPU和内存高。Flume在性能、安装各方面表现相对来说更有优势。
应用:日志分析可以应用在很多方面。例如实时推荐,通过实时分析log4j日志记录的交互信息,推送至个性推荐算法,快速构建用户兴趣矩阵。 例如网易云音乐的智能播放模式;系统告警:在实时分析日志流记录后,统计出在一分钟之内,某IP地址登录次数超过十次,标记为异常IP,在可视化系统中弹出提示。
二 Flume运行机制
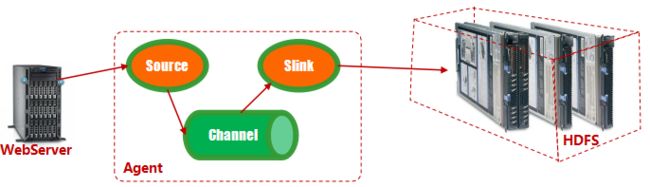
Flume-ng是分布式日志收集系统,它将各个服务器中的日志数据收集起来并送到指定的地方去,比如说送到图中的HDFS,简单来说flume就是收集日志的,经过传输之后将这些海量数据下沉落地值数据存储。从下图中可以看出,Flume 运行核心是Agent,agent为最小的独立运行单位,含有三个组件Source、Channel、Sink。每台机器运行一个agent,但是可以在一个agent中包含对个sources和sinks。
Flume 传输的数据的基本单位是 Event,如果是文本文件,通常是一行记录,这也是事务的基本单位。Event 从 Source,流向 Channel,再到 Sink,本身为一个 byte 数组,并可携带 headers 信息。Event 代表着一个数据流的最小完整单元,从外部数据源来,向外部的目的地去。event结构如下图所示:

那么总结一下Flume的运行机制就是,source在接收到日志数据后,将数据发送给channel, channel作为一个数据缓冲区会临时存放这些数据,随后sink会将channel中的数据发送到指定的地方,等到Sink将数据成功发送之后,Channel将缓存的此部分数据删除,至此,一趟Flume数据传输成功。
三 Flume核心组件剖析
Flume提供了大量内置的Source、Channel和Sink类型,不同类型的Source,Channel和Sink之间可以自由组合。组合方式基于用户设置的配置文件,非常灵活。比如:Channel可以把事件暂存在内存里,也可以持久化到本地硬盘上。Sink可以把日志写入HDFS, HBase,甚至是另外一个Source等等。Flume支持用户建立多级流,也就是说,多个agent可以协同工作,并且支持Fan-in、Fan-out、Contextual Routing、Backup Routes。下面着重介绍一个三个核心组件:
1、Source:Source相当于一个采集源,用于跟各种日志服务器进行对接以获取数据push到agent中,数据源不仅限于JMS或者其他处理的输出结果,source甚至可以自己生产数据,夸张的说,它可以接受任何来源的数据。Flume 支持 Avro,log4j,syslog 和 http post(body为json格式)。可以让应用程序同已有的Source直接打交道,Flume主要的RPC Source 是 Avro Source;此外Flume提供两种自动读取文件的source:
- SpoolSource: 监测配置的目录下新增的文件,并将文件中的数据读取出来。这也是在自动化环境下常用的一个组件类型。但是需要注意两点:拷贝到 spool 目录下的文件不可以再打开编辑;spool 目录下不可包含相应的子目录。
- ExecSource: 以运行 Linux 命令的方式,持续的输出最新的数据,如 tail -F 文件名 指令,在这种方式下,取的文件名必须是指定的。 ExecSource 可以实现对日志的实时收集,但是存在Flume不运行或者指令执行出错时,将无法收集到日志数据,无法保证日志数据的完整性。
本文列举了8种常用的Source类型,读者可根据自己的需要选择不同的source服务。
| Source类型 | 说明 |
| Avro Source | 支持Avro协议(实际上是Avro RPC),内置支持 |
| Thrift Source | 支持Thrift协议,内置支持 |
| Exec Source | 基于Unix的command在标准输出上生产数据 |
| JMS Source | 从JMS::: java消息系统:::(消息、主题)中读取数据,ActiveMQ已经测试过 |
| Spooling Directory Source | 监控指定目录内数据变更 |
| Netcat Source | 监控某个端口,将流经端口的每一个文本行数据作为Event输入 |
| HTTP Source | 基于HTTP POST或GET方式的数据源,支持JSON、BLOB表示形式 |
| Syslog Sources | 读取syslog数据,产生Event,支持UDP和TCP两种协议 |
Source的生命周期:
2、channel:agent内部数据传输通道,根据用户需要指定选择不同的Channel Type,用于将event(事件)从Source传输到Sink,但值得注意的是,必须等Sink将channel部分的数据成功发送出去,channel才会将临时数据进行删除,这种机制可以保证日志数据传输的可靠性和安全性。大家可以把这部分当做一个数据的缓冲区。目前常用的几种类型有:
- Memory Channel:基于内存的通道,可支持高速的吞吐,如果对数据的实时性有一定要求,可以选择此种类型,但是数据完整性无法保证。
- File Channel:基于磁盘文件的通道,是一个持久化的通道,它将所有event都持久化到磁盘中,从而保证在节点故障情况下数据不丢失,但也是因为在磁盘中,传输的速率相对来说比较低。
| Channel类型 | 说明 |
| Memory Channel | Event数据存储在内存中 |
| File Channel | Event数据存储在磁盘文件中 |
| JDBC Channel |
Event数据存储在持久化存储中,当前Flume Channel内置支持Derby |
| Spillable Memory Channel | Event数据存储在内存中和磁盘上,当内存队列满了,会持久化到磁盘文件(当前试验性的,不建议生产环境使用 |
| Custom Channe | 自定义Channel实现 |
划重点***********知识点********,我们常说Flume的错误恢复机制,就是通过Channel组件来进行恢复的。
3、Sink:数据目的地。采集数据的传送目的,用于往下一级agent传递数据或者往最终存储系统传递数据。Sink在设置存储数据时,可以向文件系统、数据库、hadoop存数据,在日志数据较少时,可以将数据存储在文件系中,并且设定一定的时间间隔保存数据。在日志数据较多时,可以将相应的日志数据存储到Hadoop中,便于日后进行相应的数据分析。
- HDFS Sink:将数据写入HDFS中。目前,它支持HDFS的文本和序列文件格式,以及支持两个文件类型的压缩。支持将所用的时间、数据大小、事件的数量为操作参数,对HDFS文件进行关闭(关闭当前文件,并创建一个新的)。它还可以对事源的机器名(hostname)及时间属性分离数据,即通过时间戳将数据分布到对应的文件路径
- HBase Sink:Hbase Sink支持写数据到安全的Hbase。为了将数据写入安全的Hbase,用户代理运行必须对配置的table表有写权限。主要用来验证对KDC的密钥表可以在配置中指定。在Flume Agent的classpath路径下的Hbase-site.xml文件必须设置到Kerberos认证。
| Sink类型 | 说明 |
| HDFS Sink | 数据写入HDFS |
| HBase Sink | 数据写入HBase数据库 |
| Logger Sink | 数据写入日志文件 |
| Avro Sink | 数据被转换成Avro Event, 然后发送到配置的RPC端口上 |
| Thrift Sink | 数据被转换成Thrift Event,然后发送到配置的RPC端口上 |
| File Roll Sink | 存储数据到本地文件系统 |
| ElasticSearch Sink | 数据发送到Elastic Search搜索服务器(集群) |
| Null Sink | 丢弃到所有数据 |
| Custom Sink | 自定义Sink实现 |
四 Flume安装部署
Flume的安装真的是属于简单的,你将Flume的包下载解压之后,整个安装过程就完成了一半左右。
1、使用WinSCP上传下载好的Flume二进制包apache-flume-1.8.0-bin.tar.gz至linux系统中。
2、解压Flume压缩包,tar -zvxf apache-flume-1.8.0-bin.tar.gz。为了后期方便访问Flume文件夹 mv apache-flume-1.8.0 flume(即相当于创建了flume文件夹,并将apache-flume-1.8.0文件夹的内容全部移动到flume文件夹中)。

3、修改配置文件 cd /usr/flume/conf 使用ll命令查看配置文件夹中的内容。复制配置文件并更改, cp flume-env.sh.template flume-env.sh。 编辑该配置该配置文件 vi flume-env.sh。

将系统中的JDK的位置更改即可。本例中为: export JAVA_HOME=/usr/java/jdk1.8.0_161。

4、验证是否安装成功 查看版本信息
[root@master bin]# ./flume-ng version
Flume 1.8.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: 99f591994468633fc6f8701c5fc53e0214b6da4f
Compiled by denes on Fri Sep 15 14:58:00 CEST 2017
From source with checksum fbb44c8c8fb63a49be0a59e27316833d5、配置环境变量 vi /etc/profile 添加以下内容
export FLUME_HOME=/usr/flume
export PATH=$JAVA_HOME/bin:$FLUME_HOME/bin:$PATH![]()
执行 source /etc/profile 刷新环境变量内容,即可在任何目录下执行flume-ng version的命令。
Flume就安装好了,是不是超级简单。下面就开始使用Flume吧。
五 Flume测试例子—NetCat 测试
1、在conf目录下新建一个netcat.conf文件,并添加以下内容 vi netcat.conf
#example.conf: A single-node flume configuration
#It is Just for test flume listen NetCat Example
#Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#Describe/configue the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
#Describe the sink
a1.sinks.k1.type = logger
#use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1配置文件内容分为五个部分:1、从整体上描述代理agent中sources、sinks、channels所涉及到的组件;2、详细描述agent中每一个source、sink与channel的具体实现:即在描述source的时候,需要指定source到底是什么类型的,即这个source是接受文件的、还是接受http的、还是接受thrift的;对于sink也是同理,需要指定结果是输出到HDFS中,还是Hbase中啊等等;对于channel需要指定是内存等;3、通过channel将source与sink连接起来。
在安装Flume的节点上执行如下命令,启动Flume。
[root@master ~]# flume-ng agent --conf conf --conf-file netcat.conf --name a1 -Dflume.root.logger=INFO,console参数说明:
--conf 指定flume配置文件的目录 /usr/flume/conf
--conf-file 指定agent的配置文件,即上面自己写的conf
--name 指定agent名称(注意要与配置文件中代理的名字相同,否则取不到三个组件)
-Dflume.root.logger=INFO,console 设置日志等级
成功启动后如下图所示:

我们克隆一个新的Session ,用来监听44444端口,并在此端口输入一些测试信息OK、this is ambrose、test flume netcat:

此时,我们回到flume启动的界面,可以看到以下信息:

NetCat Source测试成功。。。