hive数据加载
一.需要注意的问题:
1.hive不支持行级别的增删改
2.使用overwrite会覆盖表的原有数据,into则是追加。
3.local会将本地文件系统复制一份再上传至指定目录,无local只是将本地文件系统上的数据移动到指定目录。
4.若目录指向hdfs上的数据则执行的是move操作。
5.分隔符要与数据文件中的分隔符一样,且分隔符默认只有一个(如:'\t\n')。
6.load数据时,字段类型不能互相转化时,查询返回Null。
7.select查询插入,字段类型不能相互转化时,插入数据为NULL。
8.select查询插入数据,字段值顺序要与表中字段顺序一致,名称可以不一致(hive在加载数据时不做检查,查询时检查).
9.直接移动数据文件到含有分区表的存放目录下时,数据存放的路径层次也和表的分区一致,若表中没有添加相应的分区对应数据存放路径,即使目标路径下有数据也依然会查不到。
二.load data语句装载数据
load data导入数据格式。
1. load data inpath '/user/hadoop/emp.txt'into/overwrite table table_name;
2. load data local inpath'/user/hadoop/emp.txt' into/overwrite table table_name;
3. load data local inpath'/user/hadoop/emp.txt' into/overwrite table table_namepartition(part="a");
例. hive> create table emp(
> id int,
> name string,
> job string,
> salary int
> )
> partitioned by (city string,dt string)
> row format delimited
> fields terminated by '\t'
> lines terminated by '\n'
> stored as textfile;
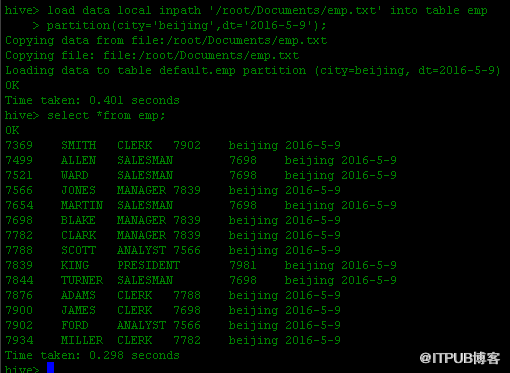
三.通过查询语句向表中插入数据(emp1,emp2)
1.insert into/overwrite table table_nameselect *from source_table;
2.insert into/overwrite table table_namepartition(part="a") select id,name from source_table;
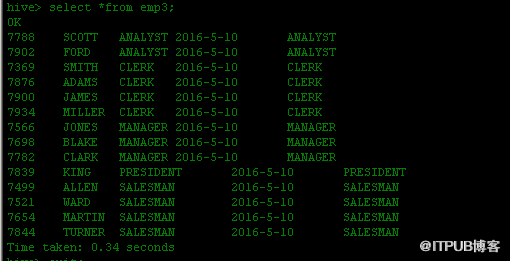
例. hive>insertinto table emp1 partition(city='shanghai',dt='2016-5-9')
>selectid,name,job,salary from emp;
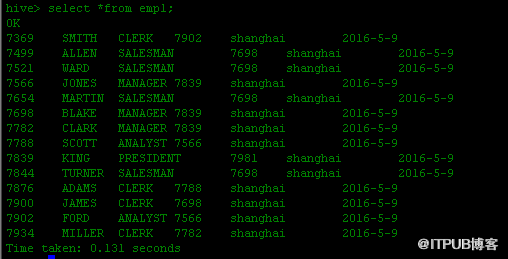
在使用此语式时table_name的表结构字段个数,必须与select后查询字段个数对应。
如无分区时可使用CTAS方式加载数据更灵活(下面会介绍)。3.hive还可以一次查询产生多个不相交的输出。(降低源表的扫描次数)。
from source_table
insert into/overwrite table table_name partition(part="a")
select id,name,age where id>0 and id<20
insert into/overwrite table table_name partition(part="a")
select id,name,age where id>100 and id<120
insert into/overwrite table table_name partition(part="a")
select id,name,age where id>150 and id<200;

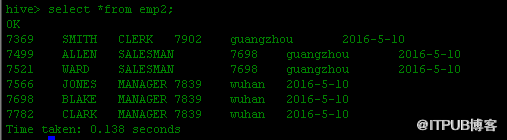
四.动态分区插入
在需要创建非常多的分区时,可以使用动态分区,基于查询创建需要创建的分区。动态分区功能默认是关闭的,开启后默认是严格模式。严格模式要求至少有一列分区字段是静态的,且必须要放在动态分区之前,避免因错误操作导致产生大量的分区。
set hive.exec.dynamic.partition=true;//开启动态分区
sethive.exec.dynamic.partition.mode=nonstrict; //nostrict无限制模式,不用担心第一列分区是否为静态。
若为strict,则你需要有一个静态分区,且必须要放在动态分区之前。
动态分区数据插入格式:
insert overwrite/into table table_namepartition(part="a")
selectid,name,job as job,salary,award from source_table;例.
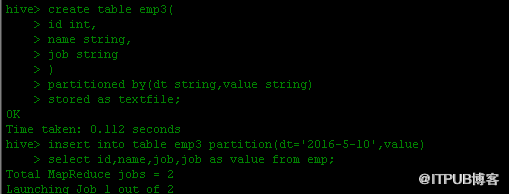
五.通过CTAS加载数据,即在创建表的时候通过从别的表中查询出相应的记录并插入到所创建的表中。CTAS是原子的,若失败新表则不会创建。
CTAS 数据导入格式:
create table table_name as select id,namefrom source_table;
例.
hive> create table emp4 as select id,name from emp; 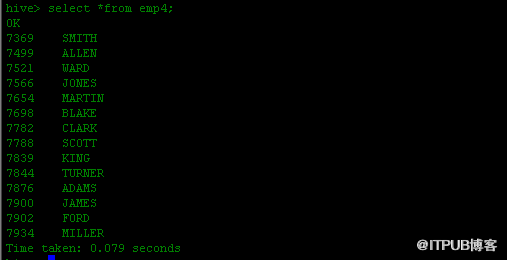
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/30172158/viewspace-2096367/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/30172158/viewspace-2096367/