Hadoop之MapReduce过程,单词计数WordCount
简介
单词计数是最简单也是最能体现MapReduce思想的程序之一,可以称为MapReduce版“Hello World”,该程序的完整代码可以在Hadoop安装包的src/example目录下找到。单词计数主要完成的功能:统计一系列文本文件中每个单词出现的次数,如下图所示。
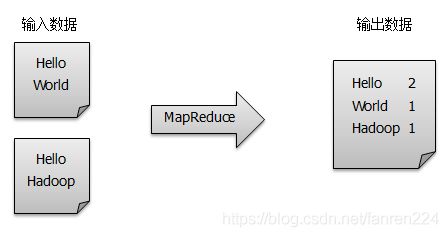
WordCount详细过程
1)将文件拆分成splits,由于测试用的文件较小,所以每个文件为一个split,并将文件按行分割形成< key,value >对,如图所示。这一步由MapReduce框架自动完成,其中偏移量(即key值)包括了回车符所占的字符数(Windows和Linux环境下会不同)

2)将分割好的< key,value>对交给用户定义的map方法进行处理,生成新的< key,value >对,如图所示:

3)得到map方法输出的< key,value>对后,Mapper会将它们按照key值进行排序,并执行Combine过程,将key值相同的value值累加,得到Mapper的最终输出结果,如图所示:
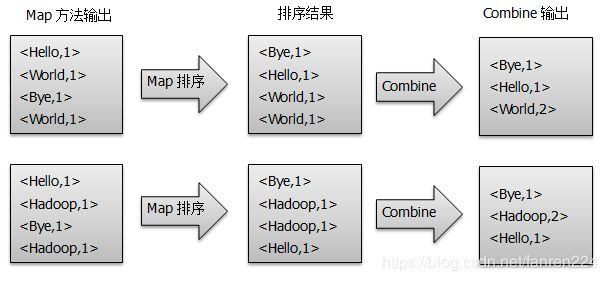
4) Reducer先对从Mapper接收的数据进行排序,再交由用户自定义的reducer方法进行处理,得到新的< key,value>对,并作为WordCount的输出结果,如图所示:


1)Combiner 节点负责完成上面提到的将同一个map中相同的key进行合并,避免重复传输,从而减少传输中的通信开销。
2)Partitioner节点负责将map产生的中间结果进行分区,确保相同的key到达同一个reduce节点.
实例:
1.创建hdfs目录
[root@master] ~$ hadoop fs -mkdir /input
2.创建本地文件file1.txt和file2.txt
[root@master] ~$ echo "hello world" > file1.txt
[root@master] ~$ echo "hello hadoop" > file2.txt
3.上传输入文件至hdfs
[root@master] ~$ hadoop fs -put file*.txt /input
3.运行jar应用,(output目录不用提前创建)
[root@master] /usr/local/hadoop/sbin$ hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount /input /output
18/11/11 21:48:52 INFO client.RMProxy: Connecting to ResourceManager at master.hanli.com/192.168.255.130:8032
18/11/11 21:48:53 INFO input.FileInputFormat: Total input paths to process : 2
18/11/11 21:48:53 INFO mapreduce.JobSubmitter: number of splits:2
18/11/11 21:48:54 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1541944054972_0001
18/11/11 21:48:54 INFO impl.YarnClientImpl: Submitted application application_1541944054972_0001
18/11/11 21:48:55 INFO mapreduce.Job: The url to track the job: http://master.hanli.com:8088/proxy/application_1541944054972_0001/
18/11/11 21:48:55 INFO mapreduce.Job: Running job: job_1541944054972_0001
18/11/11 21:49:07 INFO mapreduce.Job: Job job_1541944054972_0001 running in uber mode : false
18/11/11 21:49:07 INFO mapreduce.Job: map 0% reduce 0%
18/11/11 21:49:20 INFO mapreduce.Job: map 100% reduce 0%
18/11/11 21:49:27 INFO mapreduce.Job: map 100% reduce 100%
18/11/11 21:49:28 INFO mapreduce.Job: Job job_1541944054972_0001 completed successfully
18/11/11 21:49:28 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=55
FILE: Number of bytes written=368179
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=243
HDFS: Number of bytes written=25
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=21571
Total time spent by all reduces in occupied slots (ms)=4843
Total time spent by all map tasks (ms)=21571
Total time spent by all reduce tasks (ms)=4843
Total vcore-milliseconds taken by all map tasks=21571
Total vcore-milliseconds taken by all reduce tasks=4843
Total megabyte-milliseconds taken by all map tasks=22088704
Total megabyte-milliseconds taken by all reduce tasks=4959232
Map-Reduce Framework
Map input records=2
Map output records=4
Map output bytes=41
Map output materialized bytes=61
Input split bytes=218
Combine input records=4
Combine output records=4
Reduce input groups=3
Reduce shuffle bytes=61
Reduce input records=4
Reduce output records=3
Spilled Records=8
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=370
CPU time spent (ms)=1780
Physical memory (bytes) snapshot=492568576
Virtual memory (bytes) snapshot=6234935296
Total committed heap usage (bytes)=264638464
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=25
File Output Format Counters
Bytes Written=25
4.查看结果
[root@master] /usr/local/hadoop/sbin$ hadoop fs -ls /output
Found 2 items
-rw-r--r-- 3 root supergroup 0 2018-11-11 21:49 /output/_SUCCESS
-rw-r--r-- 3 root supergroup 25 2018-11-11 21:49 /output/part-r-00000
[root@master] /usr/local/hadoop/sbin$ hadoop fs -cat /output/part-r-00000
hadoop 1
hello 2
world 1
报错
卡住不动,如下所示
[root@master] /usr/local/hadoop/sbin$ hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount /input /output
18/11/11 21:26:50 INFO client.RMProxy: Connecting to ResourceManager at /192.168.255.130:8032
18/11/11 21:26:52 INFO input.FileInputFormat: Total input paths to process : 2
18/11/11 21:26:53 INFO mapreduce.JobSubmitter: number of splits:2
18/11/11 21:26:53 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1541942707552_0001
18/11/11 21:26:53 INFO impl.YarnClientImpl: Submitted application application_1541942707552_0001
18/11/11 21:26:53 INFO mapreduce.Job: The url to track the job: http://master.hanli.com:8088/proxy/application_1541942707552_0001/
18/11/11 21:26:53 INFO mapreduce.Job: Running job: job_1541942707552_0001
查看日志先
节点日志:/usr/local/hadoop/logs/yarn-root-nodemanager-slave1.hanli.com.log
master资源调度器日志:/usr/local/hadoop/logs/yarn-root-resourcemanager-master.hanli.com.log
参考文章
https://www.codetd.com/article/132972
https://www.cnblogs.com/xiangyangzhu/p/5711549.html
最后解决办法:在yare-site.xml里添加如下信息之后问题得到解决
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
(注意我将master、slave1、slave2这个文件都修改了,是不是只修改master就可以,不清楚,但是初步判断应该全部修改)
另外有人提到上述配置是默认的,这就不得而知了,总之问题是解决了~